主要内容:
1.scarpy爬虫框架
2.微信机器人
1.
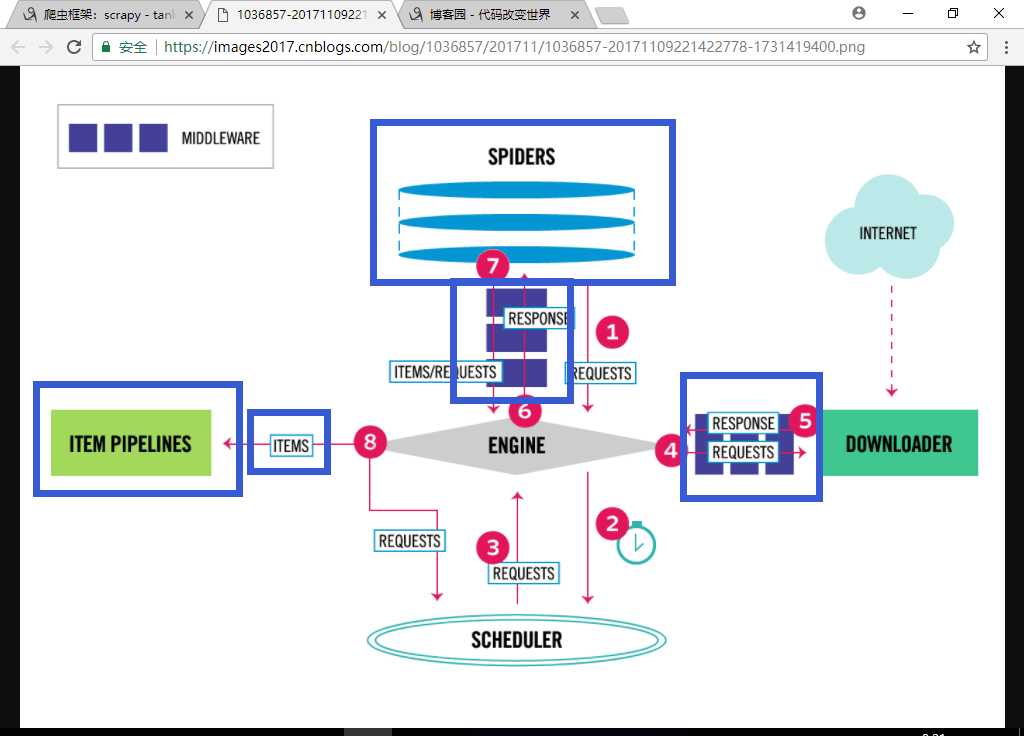
The data flow in Scrapy is controlled by the execution engine, and goes like this:
process_request()).process_response()).process_spider_input()).process_spider_output()).# 一 Scrapy爬虫框架
# 发送请求 ---> 获取响应数据 ---> 解析数据 ---> 保存数据
#
# ** Scarpy框架介绍 **
#
# 1、引擎(EGINE)
# 引擎负责控制系统所有组件之间的数据流,并在某些动作发生时触发事件。有关详细信息,请参见上面的数据流部分。
#
# 2、调度器(SCHEDULER)
# 用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL的优先级队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
#
# 3、下载器(DOWLOADER)
# 用于下载网页内容, 并将网页内容返回给EGINE,下载器是建立在twisted这个高效的异步模型上的
#
# 4、爬虫(SPIDERS)
# SPIDERS是开发人员自定义的类,用来解析responses,并且提取items,或者发送新的请求
#
# 5、项目管道(ITEM PIPLINES)
# 在items被提取后负责处理它们,主要包括清理、验证、持久化(比如存到数据库)等操作
# 下载器中间件(Downloader Middlewares)位于Scrapy引擎和下载器之间,主要用来处理从EGINE传到DOWLOADER的请求request,已经从DOWNLOADER传到EGINE的响应response,
# 你可用该中间件做以下几件事:
# (1) process a request just before it is sent to the Downloader (i.e. right before Scrapy sends the request to the website);
# (2) change received response before passing it to a spider;
# (3) send a new Request instead of passing received response to a spider;
# (4) pass response to a spider without fetching a web page;
# (5) silently drop some requests.
#
# 6、爬虫中间件(Spider Middlewares)
# 位于EGINE和SPIDERS之间,主要工作是处理SPIDERS的输入(即responses)和输出(即requests)
#
# ** Scarpy安装 **
# 1、pip3 install wheel
# 2、pip3 install lxml
# 3、pip3 install pyopenssl
# 4、pip3 install pypiwin32
# 5、安装twisted框架
# 下载twisted
# http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
# 安装下载好的twisted
# pip3 install 下载目录\Twisted-17.9.0-cp36-cp36m-win_amd64.whl
#
# 6、pip3 install scrapy
#
# ** Scarpy使用 **
# 1、进入终端cmd
# - scrapy
# C:\Users\administortra>scrapy
# Scrapy 1.6.0 - no active project
#
# 2、创建scrapy项目
# 1.创建一个文件夹,专门用于存放scrapy项目
# - D:\Scrapy_prject
# 2.cmd终端输入命令
# scrapy startproject Spider_Project( 项目名)
# - 会在 D:\Scrapy_prject文件夹下会生成一个文件
# Spider_Project : Scrapy项目文件
#
# 3.创建爬虫程序
# cd Spider_Project # 切换到scrapy项目目录下
# # 爬虫程序名称 目标网站域名
# scrapy genspider baidu www.baidu.com # 创建爬虫程序
#
# 3、启动scrapy项目,执行爬虫程序
#
# # 找到爬虫程序文件进行执行
# scrapy runspider只能执行某个 爬虫程序.py
# # 切换到爬虫程序执行文件目录下
# - cd D:\Scrapy_prject\Spider_Project\Spider_Project\spiders
# - scrapy runspider baidu.py
#
# # 根据爬虫名称找到相应的爬虫程序执行
# scrapy crawl 爬虫程序名称
# # 切换到项目目录下
# - cd D:\Scrapy_prject\Spider_Project
# - scrapy crawl baidu
#
scrapy基本使用,,,,,,就是特别nb的特别快的那种,特点可以多线程发送请求等,快速获取数据。。。。。
微信机器人:
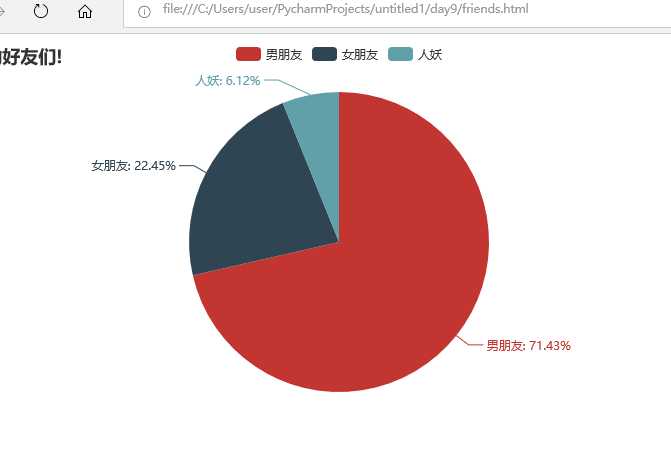
微信好友男女比例:
# from wxpy import Bot
# print(222)
# bot=Bot(cache_path=True)
# print(111)
from wxpy import Bot
from pyecharts import Pie
import webbrowser
# 实例化一个微信机器人对象
bot = Bot()
# 获取到微信的所有好友
friends = bot.friends()
# 设定男性\女性\位置性别好友名称
attr = [‘男朋友‘, ‘女朋友‘, ‘人妖‘]
# 初始化对应好友数量
value = [0, 0, 0]
# 遍历所有的好友,判断这个好友是男性还是女性
for friend in friends:
if friend.sex == 1:
value[0] += 1
elif friend.sex == 2:
value[1] += 1
else:
value[2] += 1
# 实例化一个饼状图对象
pie = Pie(‘tank的好友们!‘)
# 图表名称str,属性名称list,属性所对应的值list,is_label_show是否现在标签
pie.add(‘‘, attr, value, is_label_show=True)
# 生成一个html文件
pie.render(‘friends.html‘)
# 打开html文件
webbrowser.open(‘friends.html‘)
from wxpy import *
from pyecharts import Map
import webbrowser
bot=Bot(cache_path=True)
friends=bot.friends()
area_dic={}#定义一个字典,用来存放省市以及省市人数
for friend in friends:
if friend.province not in area_dic:
area_dic[friend.province]=1
else:
area_dic[friend.province]+=1
attr = area_dic.keys()
value = area_dic.values()
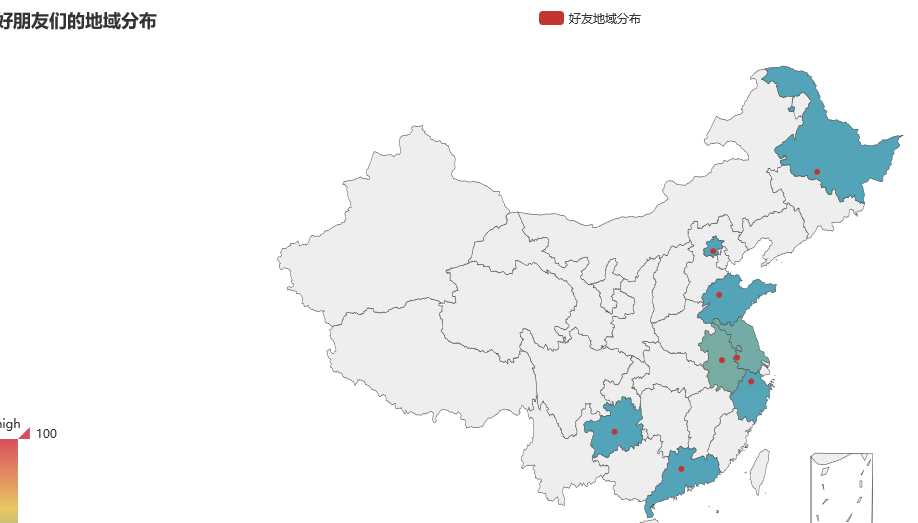
map = Map("好朋友们的地域分布", width=1200, height=600)
map.add(
"好友地域分布",
attr,
value,
maptype=‘china‘,
is_visualmap=True, #结合体VisualMap
)
#is_visualmap -> bool 是否使用视觉映射组件
#
map.render(‘area.html‘)
webbrowser.open("area.html")
注:好友地区显示
最后就是智能聊天了。。。。。
原文:https://www.cnblogs.com/7777qqq/p/11066289.html