一、 赛题解读
2018的华为软件挑战赛赛题还是很好理解的,简单讲就是分成了两个部分,一是根据多用户请求云端弹性服务器资源个数的时间序列历史数据,来对未来一段时间的用户请求情况进行预测,二是通过装箱(背包)对预测资源进行分配。算是一个比较容易上手的题目。
在官方的指导文档中,更是给出了一个简单、基本的解题思路,并含有伪代码,对于第一次参赛的人非常友好。
二、 初赛方法
因为指数平滑方法的简单稳定,适用于中短期发展趋势预测,所以我们组一开始便选择了这个方法,后来得知大多数队伍在预测部分都是指数平滑法。这也算是我们误打误撞,新手福利吧。
(1) 一次指数平滑:是一种特殊的加权平均法,对于本次实际值和本次预测值赋予不同的权重,求得下一次预测值。
St = α * xt + (1 - a)St-1
其中St为第t次预测值,xt为第t次实际值,α为权值(即平滑系数)。新预测值是根据预测误差对原预测值进行修正得到的。α的大小表明了修正的幅度。α值愈大,修正的幅度愈大,α值愈小,修正的幅度愈小。
一次指数平滑法比较简单,预测的时间序列为一条直线,不能反映时间序列的趋势和季节性。
(2)二次指数平滑: 二次指数平滑用于线性趋势的时间序列
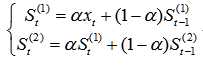
二次指数平滑,将一次平滑的结果作为实际值再次平滑,这样做保留了趋势的信息,使得预测的时间序列可以包含之前数据的趋势,二次指数平滑的预测结果是一条斜的直线。
(3) 三次指数平滑预测:在二次平滑的基础上继续平滑,可用于抛物线型的数据。
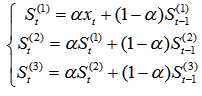
根据评分结果来看,二次指数平滑+三次指数平滑的方法得分最高,所以我们最终采取了这种具有多个参数的预测模型。
在放置部分,我们可以把问题理解成一个装箱问题,只是加了一个关于CPU和MEM的约束关系(1:1,1:2,1:4)。在放置部分我们分别使用过贪心算法和退火算法(有向师兄请教),但是在公布的数据上的结果(得分和分配效果)都是一样,为了稳妥起见(也是增加逼格),最终使用的是退火算法。
三、 遇到的问题
对于一直在Visual Studio 上进行程序调试的小白来讲,对于在Linux下进行编译,虽然觉得这是必要的,但在内心里还是很抗拒的,就像熟悉了MATLAB之后再去使用其他IDE一般。庆幸的是,VS2017可以编辑、编译、调试Linux上的C++、python程序,进行跨平台的开发。具体操作请参考:
https://www.cnblogs.com/xylc/p/6533716.html?&from=androidqq
2. 数据去噪
刚开始并未对数据进行有效的处理,直接将所有数据拿进去使用了。后来在QQ交流群中注意到有人在谈论数据去噪问题,官方给出的数据集中是有一些噪点的。
3∂原则
如果数据服从正态分布,在3∂原则下,异常值为一组测定值中与平均值的偏差超过3倍标准差的值。如果数据服从正态分布,距离平均值3∂之外的值出现的概率为P(|x-u| > 3∂) <= 0.003,属于极个别的小概率事件。
如果数据不服从正态分布,也可以用远离平均值的多少倍标准差来描述。即,使用Z-分数(Z-score)进行判断,计算每个数据的Z-分数。
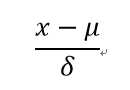
样本中每个数据x - 样本平均数u,除以样本标准差δ,即可以计算每个数据的Z-分数。Z-score的值应该为【-3,+3】,超过该值的存在为异常值的可能,需要进一步判断。
在这里,我们认为数据符合正态分布,将距离平均值3∂之外的数据点视为噪点,并用前一个位置和后一个位置的平均数进行填充。
3.评分规则
有关用例的评分规则部分之前一直没有好好看过,一直在急急忙忙的作比赛码代码,比赛末端,在方法上已经没有好的想法突破之际,我们终于开始静下心来研究评分规则,希望在这上面找到一些提高分数的突破口。

在step4中,得分 = 预测精度 * 资源利用率。那么,处理好预测精度和放置利用率之间的平衡也很重要,假如说,每个服务器可以放置5个虚拟机,预测到16个虚拟机,就会形成有一个服务器只放置1个虚拟机,造成了资源容量浪费的情况,拉低了整体的资源利用率,尽管在预测精度上可能更加准确了,但是拉低了整体的评分。所以,在某些情况下,可以牺牲部分预测准确度以达到更高的资源利用率。
所以我们在最后,增加了一个对最后一个服务器利用率的判断,如果最后一个服务器的资源利用率<0.3,则不进行放置,同时删除对应的预测的虚拟机。
四、 写在最后——感悟与经验

原文:https://www.cnblogs.com/wyr-123-wky/p/11068433.html