Zookeeper集群中的中的Leader和Follower角色是由服务器启动时期的Leader选举产生的,Observer不参与选举,此角色的节点需要在配置文件zoo.cfg中配置。示例如下:
server.1=server1:2888:3888
server.2=server2:2888:3888
server.3=server3:2888:3888
server.4=server4:2888:3888
server.5=server5:2888:3888:observer?不一定,偶数台也可以。选择奇数台原因如下:
Leader选举算法采用了Paxos协议,其核心就是半数通过。
?对于奇数台服务器,比如3台,2 > 3/2 集群最多允许一台故障;
?对于偶数台服务器,比如4台,2 !> 4/2集群最多允许一台故障;
?由此可见,3、4台的容灾能力是一样的,在性能因素非系统瓶颈的情况下,没必要多增加一台,生产一般使用3/5/7。
?对于奇数台服务器,比如5台,当集群出现脑裂时,可能情况为:[1,4]、[2,3]。无论何种情况,都存在能重新进行Leader选举的一方。
?对于偶数台服务器,比如6台,当集群出现脑裂时,可能情况为:[1,5]、[2,4]、[3,3]。当因网络连通问题出现[3,3]这种情况时,即使6台服务器均可正常工作,也无法进行Leader选举。
投票半数有两种情况:选举Leader和更新数据。
在脑裂的情况下,未过半数投票即可成为Leader,则集群中会出现多个Leader的情况。
假设集群中有三台服务器,节点数据更新情况如下:
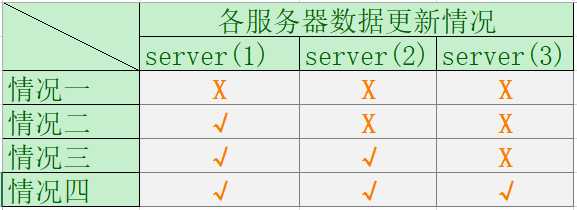
情况一:投票未过半未成功。无论哪个节点,都不会影响集群数据一致性。
情况二:投票未过半成功。当server(1)节点故障时,将出现丢失数据的情况。
情况三:投票过半且成功。无论哪个节点故障,集群中都存在节点记录了最新提交的数据。
情况四:同情况三。
?说白了,就是当出现故障时,只要集群能正常向外提供服务(过半数节点未故障),在正常工作的节点中,一定有一个节点上存着本集群数据一致性最后的希望(最新的成功提交的事务)而存有此希望的节点也将成为Leader选举中的种子选手。
?说明:集群中同时故障两个节点的情况不予考虑,因为此时集群将不再提供服务,也就不存在访问到脏数据的情况了。
原文:https://www.cnblogs.com/DeepInThought/p/11037449.html