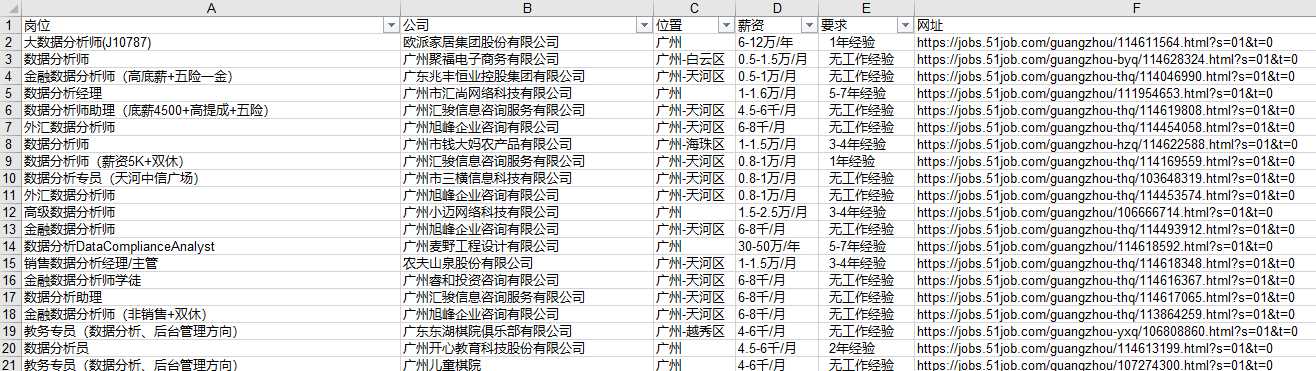
1 def getname_com(arr): 2 info = [] 3 linkinfo = [] 4 for i in arr: 5 info.append(i.string) 6 linkinfo.append(i.get(‘href‘)) 7 Info = info[4:105] 8 namearr = Info[1::2] 9 companyarr = Info[2::2] 10 link = linkinfo[5:105:2] 11 for i in range(len(namearr)): 12 namearr[i] = namearr[i].replace(‘ ‘, ‘‘)[2:] 13 return namearr, companyarr, link 14 15 url = "https://search.51job.com/list/030200,000000,0000,00,9,99,%25E6%2595%25B0%25E6%258D%25AE%25E5%2" \"588%2586%25E6%259E%2590,2," + str(page) + ".html?lang=c&stype=1&postchannel=0000&workyear=99&cotype=99°reefrom" 16 "=99&jobterm=99&companysize=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0" \"&address=&line=&specialarea=00&from=&welfare=" 17 html = requests.get(url) 18 html.encoding = ‘utf-8‘ 19 soup = bs(html.content, "html.parser") 20 name_c = soup.find_all("a", {"target": "_blank"}) # 名称和公司 21 name, company, link = getname_com(name_c)
从获取到的网址中,再次解析获得工作经验的需求信息
1 def getexp(arr): 2 info = [] 3 exp = [] 4 for url in arr: 5 try: 6 html = requests.get(url) 7 soup = bs(html.content, "html.parser",from_encoding="GBK") 8 info.append(soup.find_all("p", {"class": "msg ltype"})) 9 except: 10 print("come in") 11 info.append("</span>无效地址<span>") 12 pass 13 for i in info: 14 i = str(i) 15 print(i) 16 try: 17 exp.append(re.findall(r"</span>(.*?)<span>", i)[0]) 18 except: 19 exp.append("嘻嘻") # 方便后期查错 20 return exp 21 exp = getexp(link)
最终获得数据:
数据的爬取-链家网
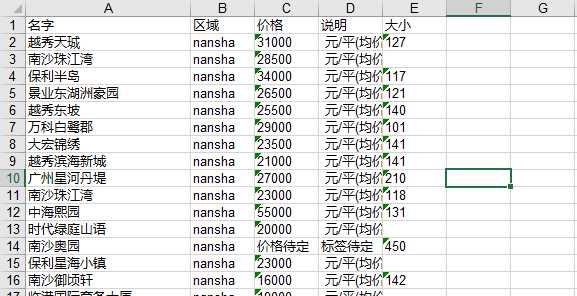
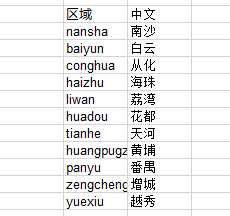
1 ‘‘‘通过解析过的内容进行信息的提取‘‘‘ 2 def getname(namelist): 3 name1 = [] 4 for i in namelist: 5 i = str(i) 6 name1.extend(re.findall(r">(.*)<", i)) 7 return name1 8 ‘‘‘分区域进行搜索,获取搜索结果页数‘‘‘ 9 llist = [‘nansha‘,‘liwan‘, ‘yuexiu‘, ‘haizhu‘, ‘tianhe‘, ‘baiyun‘, ‘huangpugz‘, ‘panyu‘, ‘huadou‘, ‘zengcheng‘, ‘conghua‘] 10 for ll in llist: 11 u = r"https://gz.fang.lianjia.com/loupan/" + ll + "/pg" #分批搜索 12 html = requests.get(u).text 13 soup = bs(html, "html.parser") 14 maxnum.extend(soup.select(".page-box")) #获取页数 15 totalpage = math.ceil(int(str(maxnum[0]).split(‘"‘)[-2])/10) 16 while page != totalpage + 1: 17 url = u + str(page) 18 html = requests.get(url).text 19 soup = bs(html, "html.parser") 20 name.extend(getname(soup.findAll("a", {‘class‘: ‘name‘}))) #提取楼盘名字 21 # location.extend(getloca(soup.select(".resblock-location span"))) 22 price.extend(getname(soup.select(".main-price span"))) #提取价格 23 area.extend(getarea(soup.select(".resblock-area span"))) #提取规格大小 24 page += 1
同样地将数据写入excel中,等待处理。
数据的清洗
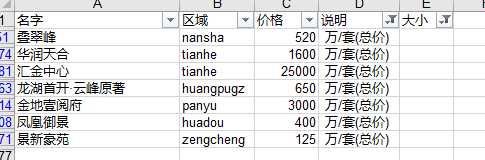

4、至此就清理完毕,总共抓取了573条房源信息,其中包含有效数据569条,其中规格大小虽然部分缺失,但也没有怎么影响到价格,部分被影响的信息也是很少,做删除处理也对最后结果不会产生太大的影响。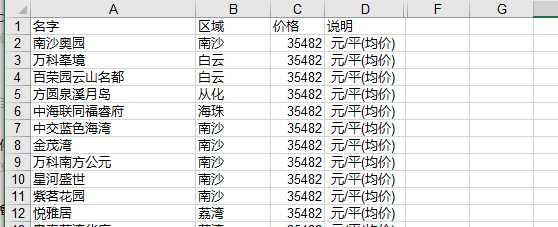
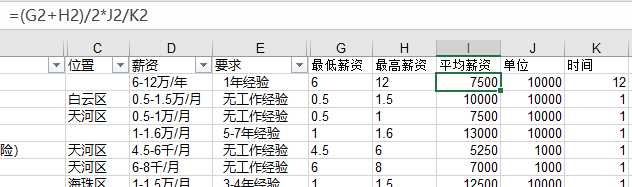
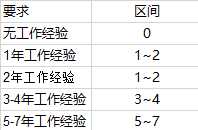
2、使用vlookup函数将工作做经验与平均薪资划分区间。
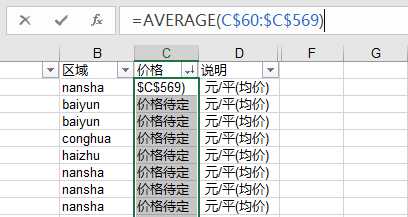
3、发现有部分位置信息是空白的,由于直接看公司名称也不能发现位置信息,所以位置的缺失值将使用出现最多的“天河区”进行代替,至此,职位信息的数据清洗完毕,总共抓取了723条数据,有效数据722条,缺失值都可以得到一定的处理,数据越多,对分析也越有好处,其中发现从化只有一条数据,并不能代表从化的平均薪资水平,所以将从化的职位信息删除,对应的,也将房源信息的从化部分数据删除。
地域性分布
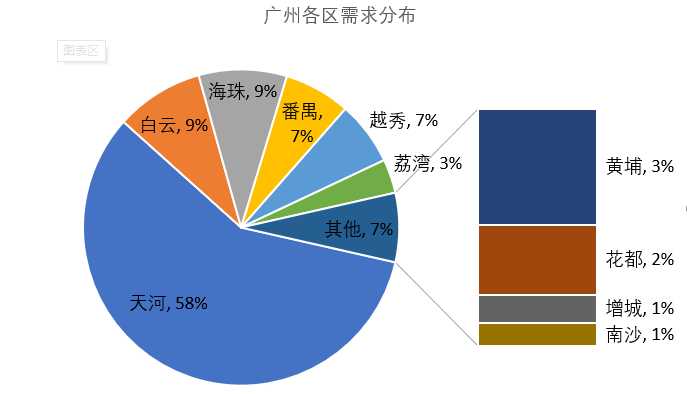
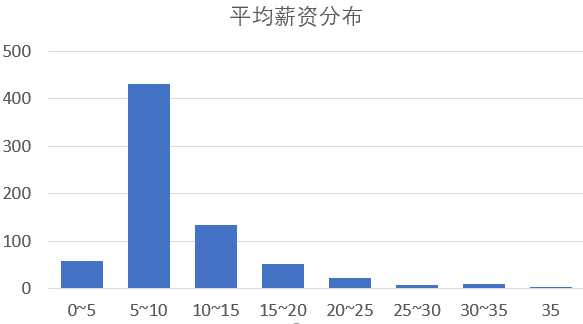
数据分析岗的薪资大多数集中在5~15k/月,有少数能达到25k以上,总体来看,数据分析岗的薪资待遇还是不错的,由于统计的是平均薪资,实际应该会比图中的 情况更好一点。
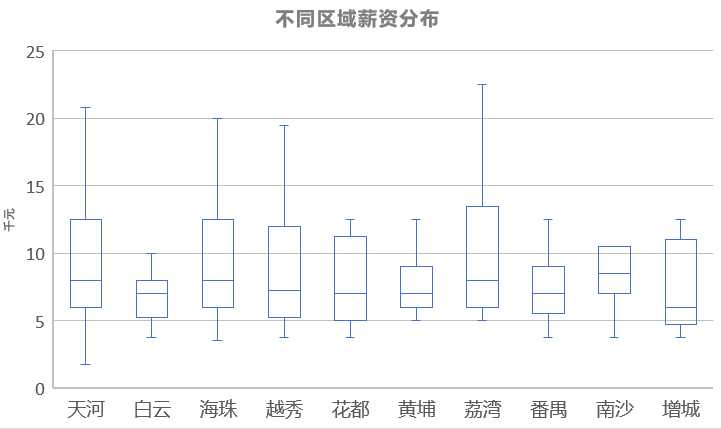
从删除了离群点的箱型图来看,基本还是和总体的薪资分布情况差不多,比较集中,中位数大约都处在7k左右,但高薪资的情况也还是有的的,薪资的分布还与工作经验要求有关系。
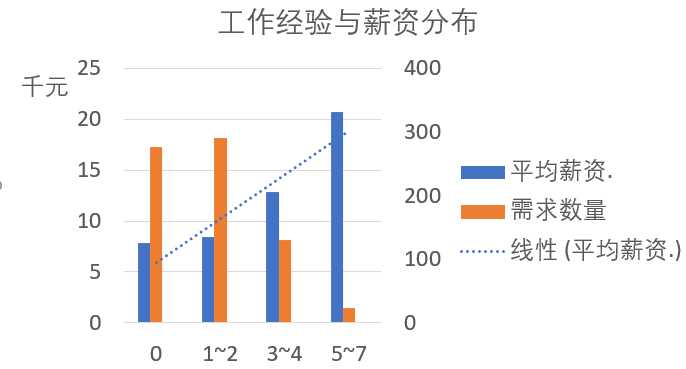
工作经验与薪资分布
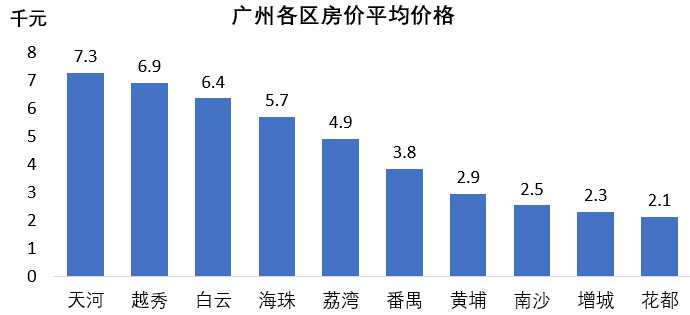
处于市中心的天河区理所当然的登榜首,离不开其丰富的交通体系,各方面的资源都比较齐全,也创造了更多的就业机会。
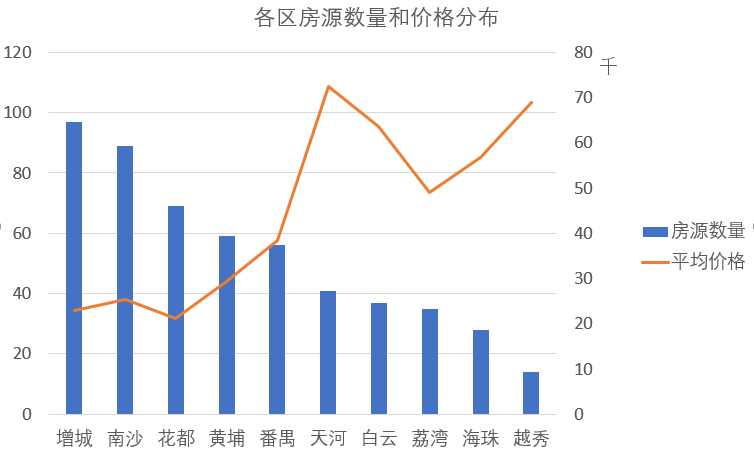
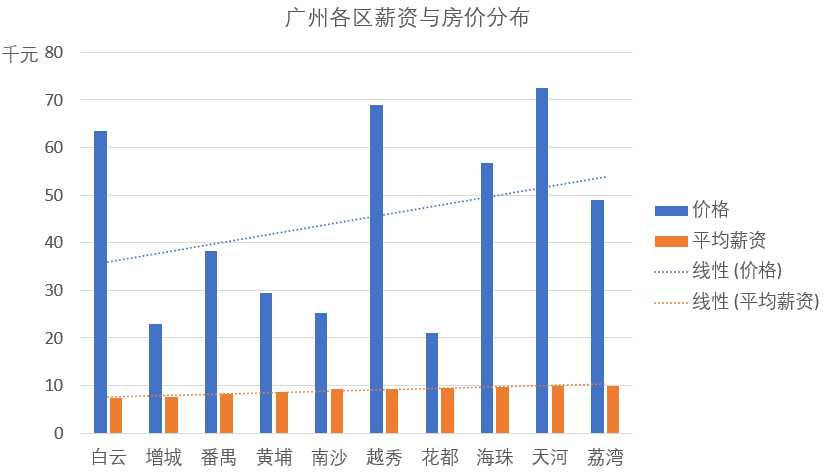
原文:https://www.cnblogs.com/hjhsblogs/p/11073135.html