本文讨论的背景是Linux环境下的network IO。本文最重要的参考文献是Richard Stevens的“UNIX® Network Programming Volume 1, Third Edition: The Sockets Networking ”,6.2节“I/O Models ”,Stevens在这节中详细说明了各种IO的特点和区别,如果英文够好的话,推荐直接阅读。Stevens的文风是有名的深入浅出,所以不用担心看不懂。本文中的流程图也是截取自参考文献。参照原文博客,仅供学习。
在进行解释之前,首先要说明几个概念:
现在操作系统都是采用虚拟存储器,那么对32位操作系统而言,它的寻址空间(虚拟存储空间)为4G(2的32次方)。操作系统的核心是内核,独立于普通的应用程序,可以访问受保护的内存空间,也有访问底层硬件设备的所有权限。为了保证用户进程不能直接操作内核(kernel),保证内核的安全,操心系统将虚拟空间划分为两部分,一部分为内核空间,一部分为用户空间。针对linux操作系统而言,将最高的1G字节(从虚拟地址0xC0000000到0xFFFFFFFF),供内核使用,称为内核空间,而将较低的3G字节(从虚拟地址0x00000000到0xBFFFFFFF),供各个进程使用,称为用户空间。
为了控制进程的执行,内核必须有能力挂起正在CPU上运行的进程,并恢复以前挂起的某个进程的执行。这种行为被称为进程切换。因此可以说,任何进程都是在操作系统内核的支持下运行的,是与内核紧密相关的。
从一个进程的运行转到另一个进程上运行,这个过程中经过下面这些变化:
注:总而言之就是很耗资源,具体的可以参考这篇文章:进程切换
正在执行的进程,由于期待的某些事件未发生,如请求系统资源失败、等待某种操作的完成、新数据尚未到达或无新工作做等,则由系统自动执行阻塞(Block),使自己由运行状态变为阻塞状态。可见,进程的阻塞是进程自身的一种主动行为,也因此只有处于运行态的进程(获得CPU),才可能将其转为阻塞状态。
# 当进程进入阻塞状态,是不占用CPU资源的。
文件描述符(File descriptor)是计算机科学中的一个术语,是一个用于表述指向文件的引用的抽象化概念。
文件描述符在形式上是一个非负整数。实际上,它是一个索引值,指向内核为每一个进程所维护的该进程打开文件的记录表。当程序打开一个现有文件或者创建一个新文件时,内核向进程返回一个文件描述符。在程序设计中,一些涉及底层的程序编写往往会围绕着文件描述符展开。但是文件描述符这一概念往往只适用于UNIX、Linux这样的操作系统。
缓存 I/O 又被称作标准 I/O,大多数文件系统的默认 I/O 操作都是缓存 I/O。在 Linux 的缓存 I/O 机制中,操作系统会将 I/O 的数据缓存在文件系统的页缓存( page cache )中,也就是说,数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间。
缓存 I/O 的缺点:
数据在传输过程中需要在应用程序地址空间和内核进行多次数据拷贝操作,这些数据拷贝操作所带来的 CPU 以及内存开销是非常大的。
对于一次IO访问(以read举例),数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间。所以说,当一个read操作发生时,它会经历两个阶段:
正式因为这两个阶段,linux系统产生了下面五种网络模式的方案。
注:由于signal driven IO在实际中并不常用,所以我这只提及剩下的四种IO Model。
在linux中,默认情况下所有的socket都是blocking,一个典型的读操作流程大概是这样:
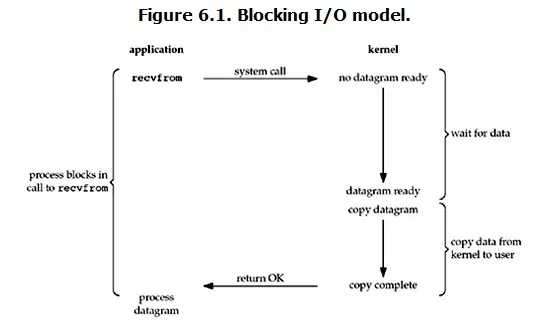
当用户进程调用了recvfrom这个系统调用,kernel就开始了IO的第一个阶段:
所以,blocking IO的特点就是在IO执行的两个阶段都被block了。
几乎所有的程序员第一次接触到的网络编程都是从bind()、listen()、accept()、send()、recv()等接口开始的,
使用这些接口可以很方便的构建服务器/客户机的模型。然而大部分的socket接口都是阻塞型的。Python3 socket官方文档
ps:所谓阻塞型接口是指系统调用(一般是IO接口)不返回调用结果并让当前线程一直阻塞,只有当该系统调用获得结果或者超时出错时才返回。
浏览器发送一个预先定义的文本(HTTP Request), Web server 处理一下(通常是从磁盘上取一个扩展名为.html的文件), 然后把这个文件通过文本方式发送回去(HTTP Response)。 唯一麻烦的是,得请操作系统给我建立HTTP层下面的TCP连接通道,因为所有的文本数据都是通过这些TCP连接通道接受和发送, 这个连接通道是用socket建立的。
socket client && server
import socket
sk = socket.socket()
sk.connect((‘xxx.xxx.oo.oo‘, 9600))
while True:
msg = input(‘>>>>‘)
sk.send(msg.encode())
if msg.lower() == ‘quit‘:
break
ret = sk.recv(1024)
if ret.lower() == ‘quit‘:
break
print(ret.decode())
sk.close()
import socket
sk = socket.socket(family=socket.AF_INET, type=socket.SOCK_STREAM) # 默认TCP,参数可以不写
sk.bind((‘0.0.0.0‘, 9600))
sk.listen()
while True:
conn, ip_addr = sk.accept()
print(ip_addr)
while True:
msg = conn.recv(1024).decode()
if msg.lower() == ‘quit‘:
break
print(msg)
send_msg = input(‘>>>>‘)
conn.send(send_msg.encode())
if send_msg.lower() == ‘quit‘:
break
conn.close()
sk.close()
改进方法
# 一个简单的解决方案: # 在服务器端使用多线程(或多进程)。 多线程(或多进程)的目的是让每个连接都拥有独立的线程(或进程), 这样任何一个连接的阻塞都不会影响其他的连接。 #该方案的问题是: 开启多进程或都线程的方式,在遇到要同时响应成百上千路的连接请求, 则无论多线程还是多进程都会严重占据系统资源,降低系统对外界响应效率, 而且线程与进程本身也更容易进入假死状态。 # 改进方案: # 很多程序员可能会考虑使用“线程池”或“连接池”。 “线程池”旨在减少创建和销毁线程的频率,其维持一定合理数量的线程, 并让空闲的线程重新承担新的执行任务。“连接池”维持连接的缓存池, 尽量重用已有的连接、减少创建和关闭连接的频率。 这两种技术都可以很好的降低系统开销,都被广泛应用很多大型系统,如websphere、tomcat和各种数据库等。 # 改进后方案其实也存在着问题: # “线程池”和“连接池”技术也只是在一定程度上缓解了频繁调用IO接口带来的资源占用。 而且,所谓“池”始终有其上限,当请求大大超过上限时,“池”构成的系统对外界的响应并不比没有池的时候效果好多少。 所以使用“池”必须考虑其面临的响应规模,并根据响应规模调整“池”的大小。 对应上例中的所面临的可能同时出现的上千甚至上万次的客户端请求, “线程池”或“连接池”或许可以缓解部分压力,但是不能解决所有问题。 总之,多线程模型可以方便高效的解决小规模的服务请求,但面对大规模的服务请求, # 多线程模型也会遇到瓶颈,可以用非阻塞接口来尝试解决这个问题。
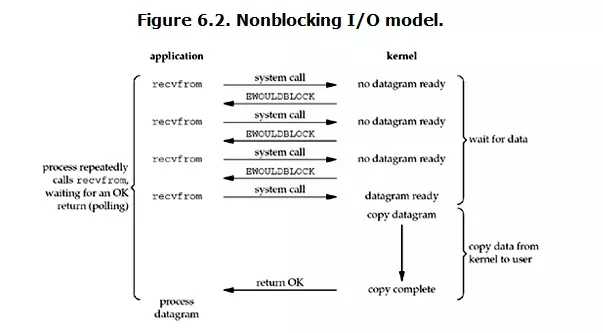
Linux下,可以通过设置socket使其变为non-blocking。当对一个non-blocking socket执行读操作时,轮询(polling)流程是这个样子:
需要注意,copy data from kernel to user --> 拷贝数据整个过程,进程仍然是属于阻塞的状态。
# 服务端 from socket import * import time
s=socket(AF_INET,SOCK_STREAM) s.bind((‘127.0.0.1‘,8080)) s.listen(5) s.setblocking(False) #设置socket的接口为非阻塞 conn_l=[] del_l=[]
while True: try: conn,addr=s.accept() conn_l.append(conn) except BlockingIOError: print(conn_l) for conn in conn_l: try: data=conn.recv(1024) if not data: del_l.append(conn) continue conn.send(data.upper()) except BlockingIOError: pass except ConnectionResetError: del_l.append(conn) for conn in del_l: conn_l.remove(conn) conn.close() del_l=[] #客户端 from socket import * c=socket(AF_INET,SOCK_STREAM) c.connect((‘127.0.0.1‘,8080)) while True: msg=input(‘>>: ‘) if not msg:continue c.send(msg.encode(‘utf-8‘)) data=c.recv(1024) print(data.decode(‘utf-8‘)) # 非阻塞IO实例 #1. 循环调用recv()将大幅度推高CPU占用率;这也是我们在代码中留一句time.sleep(2)的原因,否则在低配主机下极容易出现卡机情况 #2. 任务完成的响应延迟增大了,因为每过一段时间才去轮询一次read操作,而任务可能在两次轮询之间的任意时间完成。这会导致整体数据吞吐量的降低。
# 此外,在这个方案中recv()更多的是起到检测“操作是否完成”的作用,
# 实际操作系统提供了更为高效的检测“操作是否完成“作用的接口,例如select()多路复用模式,可以一次检测多个连接是否活跃。
摘自 unix环境高级编程第三版 仅供参考
14.2 Nonblocking I/O In Section 10.5, we said that system calls are divided into two categories: the ‘‘slow’’ ones and all the others. The slow system calls are those that can block forever. They include • Reads that can block the caller forever if data isn’t present with certain file types (pipes, terminal devices, and network devices) • Writes that can block the caller forever if the data can’t be accepted immediately by these same file types (e.g., no room in the pipe, network flow control) • Opens that block until some condition occurs on certain file types (such as an open of a terminal device that waits until an attached modem answers the phone, or an open of a FIFO for writing only, when no other process has the FIFO open for reading) • Reads and writes of files that have mandatory record locking enabled 481 482 Advanced I/O Chapter 14 • Certain ioctl operations • Some of the interprocess communication functions (Chapter 15)
We also said that system calls related to disk I/O are not considered slow, even though the read or write of a disk file can block the caller temporarily. Nonblocking I/O lets us issue an I/O operation, such as an open, read, or write, and not have it block forever. If the operation cannot be completed, the call returns immediately with an error noting that the operation would have blocked. There are two ways to specify nonblocking I/O for a given descriptor. 1. If we call open to get the descriptor, we can specify the O_NONBLOCK flag (Section 3.3). 2. For a descriptor that is already open, we call fcntl to turn on the O_NONBLOCK file status flag (Section 3.14). Figure 3.12 shows a function that we can call to turn on any of the file status flags for a descriptor. Earlier versions of System V used the flag O_NDELAY to specify nonblocking mode. These versions of System V returned a value of 0 from the read function if there wasn’t any data to be read. Since this use of a return value of 0 overlapped with the normal UNIX System convention of 0 meaning the end of file, POSIX.1 chose to provide a nonblocking flag with a different name and different semantics. Indeed, with these older versions of System V, when we get a return of 0 from read, we don’t know whether the call would have blocked or whether the end of file was encountered. We’ll see that POSIX.1 requires that read return −1 with errno set to EAGAIN if there is no data to read from a nonblocking descriptor. Some platforms derived from System V support both the older O_NDELAY and the POSIX.1 O_NONBLOCK, but in this text we’ll use only the POSIX.1 feature. The older O_NDELAY is intended for backward compatibility and should not be used in new applications. 4.3BSD provided the FNDELAY flag for fcntl, and its semantics were slightly different. Instead of affecting only the file status flags for the descriptor, the flags for either the terminal device or the socket were also changed to be nonblocking, thereby affecting all users of the terminal or socket, not just the users sharing the same file table entry (4.3BSD nonblocking I/O worked only on terminals and sockets). Also, 4.3BSD returned EWOULDBLOCK if an operation on a nonblocking descriptor could not complete without blocking. Today, BSD-based systems provide the POSIX.1 O_NONBLOCK flag and define EWOULDBLOCK to be the same as EAGAIN. These systems provide nonblocking semantics consistent with other POSIX-compatible systems: changes in file status flags affect all users of the same file table entry, but are independent of accesses to the same device through other file table entries. (Refer to Figures 3.7 and 3.9.) Example Let’s look at an example of nonblocking I/O. The program in Figure 14.1 reads up to 500,000 bytes from the standard input and attempts to write it to the standard output. The standard output is first set to be nonblocking. The output is in a loop, with the results of each write being printed on the standard error. The function clr_fl is similar to the function set_fl that we showed in Figure 3.12. This new function simply clears one or more of the flag bits. Section 14.2 Nonblocking I/O 483 #include "apue.h" #include <errno.h> #include <fcntl.h> char buf[500000]; int main(void) { int ntowrite, nwrite; char *ptr; ntowrite = read(STDIN_FILENO, buf, sizeof(buf)); fprintf(stderr, "read %d bytes\n", ntowrite); set_fl(STDOUT_FILENO, O_NONBLOCK); /* set nonblocking */ ptr = buf; while (ntowrite > 0) { errno = 0; nwrite = write(STDOUT_FILENO, ptr, ntowrite); fprintf(stderr, "nwrite = %d, errno = %d\n", nwrite, errno); if (nwrite > 0) { ptr += nwrite; ntowrite -= nwrite; } } clr_fl(STDOUT_FILENO, O_NONBLOCK); /* clear nonblocking */ exit(0); } Figure 14.1 Large nonblocking write If the standard output is a regular file, we expect the write to be executed once: $ ls -l /etc/services print file size -rw-r--r-- 1 root 677959 Jun 23 2009 /etc/services $ ./a.out < /etc/services > temp.file try a regular file first read 500000 bytes nwrite = 500000, errno = 0 a single write $ ls -l temp.file verify size of output file -rw-rw-r-- 1 sar 500000 Apr 1 13:03 temp.file But if the standard output is a terminal, we expect the write to return a partial count sometimes and an error at other times. This is what we see: 484 Advanced I/O Chapter 14 $ ./a.out < /etc/services 2>stderr.out output to terminal lots of output to terminal ... $ cat stderr.out read 500000 bytes nwrite = 999, errno = 0 nwrite = -1, errno = 35 nwrite = -1, errno = 35 nwrite = -1, errno = 35 nwrite = -1, errno = 35 nwrite = 1001, errno = 0 nwrite = -1, errno = 35 nwrite = 1002, errno = 0 nwrite = 1004, errno = 0 nwrite = 1003, errno = 0 nwrite = 1003, errno = 0 nwrite = 1005, errno = 0 nwrite = -1, errno = 35 61 of these errors ... nwrite = 1006, errno = 0 nwrite = 1004, errno = 0 nwrite = 1005, errno = 0 nwrite = 1006, errno = 0 nwrite = -1, errno = 35 108 of these errors ... nwrite = 1006, errno = 0 nwrite = 1005, errno = 0 nwrite = 1005, errno = 0 nwrite = -1, errno = 35 681 of these errors ... and so on ... nwrite = 347, errno = 0
On this system, the errno of 35 is EAGAIN. The amount of data accepted by the terminal driver varies from system to system. The results will also vary depending on how you are logged in to the system: on the system console, on a hard-wired terminal, on a network connection using a pseudo terminal. If you are running a windowing system on your terminal, you are also going through a pseudo terminal device. In this example, the program issues more than 9,000 write calls, even though only 500 are needed to output the data. The rest just return an error. This type of loop, called polling, is a waste of CPU time on a multiuser system. In Section 14.4, we’ll see that I/O multiplexing with a nonblocking descriptor is a more efficient way to do this. Sometimes, we can avoid using nonblocking I/O by designing our applications to use multiple threads (see Chapter 11). We can allow individual threads to block in I/O calls if we can continue to make progress in other threads. This can sometimes simplify the design, as we shall see in Chapter 21; at other times, however, the overhead of synchronization can add more complexity than is saved from using threads.
IO multiplexing就是我们说的select,poll,epoll,有些地方也称这种IO方式为event driven IO。select/epoll的好处就在于单个process就可以同时处理多个网络连接的IO。它的基本原理就是select,poll,epoll这个function会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程。( process blocks in call to select, waiting for one of possibly many sockets to become readable)
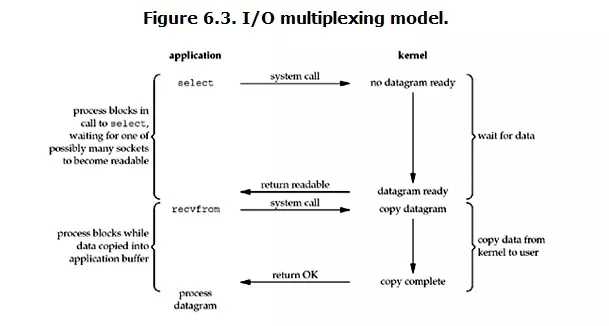
当用户进程调用了select,那么整个进程会被block,而同时,kernel会“监视” 所有 select负责的 socket,当任何一个socket中的数据准备好了,select就会返回。这个时候用户进程再调用read操作,将数据从kernel拷贝到用户进程。
所以,I/O 多路复用的特点是通过一种机制一个进程能同时等待多个文件描述符,而这些文件描述符(套接字描述符)其中的任意一个进入读就绪状态,select()函数就可以返回。
这个图和blocking IO的图其实并没有太大的不同,事实上,还更差一些。
注意:
#服务端
from socket import *
import select
s=socket(AF_INET,SOCK_STREAM)
s.setsockopt(SOL_SOCKET,SO_REUSEADDR,1)
s.bind((‘127.0.0.1‘,8081))
s.listen(5)
s.setblocking(False) #设置socket的接口为非阻塞
read_l=[s,]
while True:
r_l,w_l,x_l=select.select(read_l,[],[])
print(r_l)
for ready_obj in r_l:
if ready_obj == s:
conn,addr=ready_obj.accept() #此时的ready_obj等于s
read_l.append(conn)
else:
try:
data=ready_obj.recv(1024) #此时的ready_obj等于conn
if not data:
ready_obj.close()
read_l.remove(ready_obj)
continue
ready_obj.send(data.upper())
except ConnectionResetError:
ready_obj.close()
read_l.remove(ready_obj)
#客户端
from socket import *
c=socket(AF_INET,SOCK_STREAM)
c.connect((‘127.0.0.1‘,8081))
while True:
msg=input(‘>>: ‘)
if not msg:continue
c.send(msg.encode(‘utf-8‘))
data=c.recv(1024)
print(data.decode(‘utf-8‘))
select网络IO模型
select监听fd变化的过程分析: 用户进程创建socket对象,拷贝监听的fd到内核空间,每一个fd会对应一张系统文件表, 内核空间的fd响应到数据后,就会发送信号给用户进程数据已到; 用户进程再发送系统调用,比如(accept)将内核空间的数据copy到用户空间,同时作为接受数据端内核空间的数据清除, 这样重新监听时fd再有新的数据又可以响应到了(发送端因为基于TCP协议所以需要收到应答后才会清除)。 该模型的优点: 相比其他模型,使用select() 的事件驱动模型只用单线程(进程)执行,占用资源少,不消耗太多 CPU,同时能够为多客户端提供服务。 如果试图建立一个简单的事件驱动的服务器程序,这个模型有一定的参考价值。 该模型的缺点: 首先select()接口并不是实现“事件驱动”的最好选择。因为当需要探测的句柄值较大时,select()接口本身需要消耗大量时间去轮询各个句柄。 很多操作系统提供了更为高效的接口,如linux提供了epoll,BSD提供了kqueue,Solaris提供了/dev/poll,…。 如果需要实现更高效的服务器程序,类似epoll这样的接口更被推荐。遗憾的是不同的操作系统特供的epoll接口有很大差异, 所以使用类似于epoll的接口实现具有较好跨平台能力的服务器会比较困难。 其次,该模型将事件探测和事件响应夹杂在一起,一旦事件响应的执行体庞大,则对整个模型是灾难性的。
摘自 unix环境高级编程第三版 仅供参考
14.4 I/O Multiplexing
When we read from one descriptor and write to another, we can use blocking I/O in a
loop, such as
while ((n = read(STDIN_FILENO, buf, BUFSIZ)) > 0)
if (write(STDOUT_FILENO, buf, n) != n)
err_sys("write error");
We see this form of blocking I/O over and over again. What if we have to read from
two descriptors? In this case, we can’t do a blocking read on either descriptor, as data
may appear on one descriptor while we’re blocked in a read on the other. A different
technique is required to handle this case.
Let’s look at the structure of the telnet(1) command. In this program, we read
from the terminal (standard input) and write to a network connection, and we read
from the network connection and write to the terminal (standard output). At the other
end of the network connection, the telnetd daemon reads what we typed and
presents it to a shell as if we were logged in to the remote machine. The telnetd
daemon sends any output generated by the commands we type back to us through the
telnet command, to be displayed on our terminal.
The telnet process has two inputs and two outputs. We can’t do a blocking read
on either of the inputs, as we never know which input will have data for us.
One way to handle this particular problem is to divide the process in two pieces
(using fork), with each half handling one direction of data. We show this in
If we use two processes, we can let each process do a blocking read. But this leads to a
problem when the operation terminates. If an end of file is received by the child (the
Section 14.4 I/O Multiplexing 501
network connection is disconnected by the telnetd daemon), then the child terminates
and the parent is notified by the SIGCHLD signal. But if the parent terminates (the user
enters an end-of-file character at the terminal), then the parent has to tell the child to
stop. We can use a signal for this (SIGUSR1, for example), but it does complicate the
program somewhat.
Instead of two processes, we could use two threads in a single process. This avoids
the termination complexity, but requires that we deal with synchronization between the
threads, which could add more complexity than it saves.
We could use nonblocking I/O in a single process by setting both descriptors to be
nonblocking and issuing a read on the first descriptor. If data is present, we read it and
process it. If there is no data to read, the call returns immediately. We then do the same
thing with the second descriptor. After this, we wait for some amount of time (a few
seconds, perhaps) and then try to read from the first descriptor again. This type of loop
is called polling. The problem is that it wastes CPU time. Most of the time, there won’t
be data to read, so we waste time performing the read system calls. We also have to
guess how long to wait each time around the loop. Although it works on any system
that supports nonblocking I/O, polling should be avoided on a multitasking system.
Another technique is called asynchronous I/O. With this technique, we tell the kernel
to notify us with a signal when a descriptor is ready for I/O. There are two problems
with this approach. First, although systems provide their own limited forms of
asynchronous I/O, POSIX chose to standardize a different set of interfaces, so
portability can be an issue. (In the past, POSIX asynchronous I/O was an optional
facility in the Single UNIX Specification, but these interfaces are required as of SUSv4.)
System V provides the SIGPOLL signal to support a limited form of asynchronous I/O,
but this signal works only if the descriptor refers to a STREAMS device. BSD has a
similar signal, SIGIO, but it has similar limitations: it works only on descriptors that
refer to terminal devices or networks.
The second problem with this technique is that the limited forms use only one
signal per process (SIGPOLL or SIGIO). If we enable this signal for two descriptors (in
the example we’ve been talking about, reading from two descriptors), the occurrence of
the signal doesn’t tell us which descriptor is ready. Although the POSIX.1
asynchronous I/O interfaces allow us to select which signal to use for notification, the
number of signals we can use is still far less than the number of possible open file
descriptors. To determine which descriptor is ready, we would need to set each file
descriptor to nonblocking mode and try the descriptors in sequence. We discuss
asynchronous I/O in Section 14.5.
A better technique is to use I/O multiplexing. To do this, we build a list of the
descriptors that we are interested in (usually more than one descriptor) and call a
function that doesn’t return until one of the descriptors is ready for I/O. Three
functions —poll, pselect, and select—allow us to perform I/O multiplexing. On
return from these functions, we are told which descriptors are ready for I/O.
POSIX specifies that <sys/select.h> be included to pull the information for select into
your program. Older systems require that you include <sys/types.h>, <sys/time.h>,
and <unistd.h>. Check the select manual page to see what your system supports.
502 Advanced I/O Chapter 14
I/O multiplexing was provided with the select function in 4.2BSD. This function has
always worked with any descriptor, although its main use has been for terminal I/O and
network I/O. SVR3 added the poll function when the STREAMS mechanism was added.
Initially, poll worked only with STREAMS devices. In SVR4, support was added to allow
poll to work on any descriptor.
Linux下的asynchronous IO其实用得很少。先看一下它的流程:
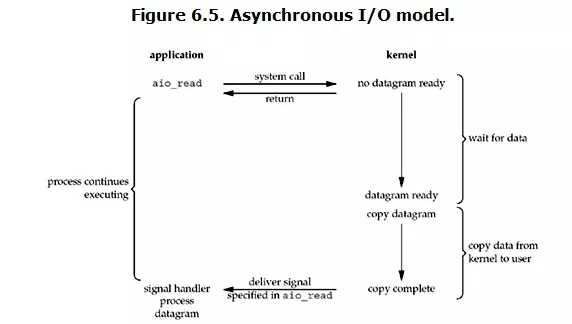
在说明synchronous IO和asynchronous IO的区别之前,需要先给出两者的定义。POSIX的定义是这样子的:
两者的区别就在于synchronous IO做”IO operation”的时候会将process阻塞。
按照这个定义,之前所述的blocking IO,non-blocking IO,IO multiplexing都属于synchronous IO。
有人会说,non-blocking IO并没有被block啊。这里有个非常“狡猾”的地方,定义中所指的”IO operation”是指真实的IO操作,就是例子中的recvfrom这个system call。
各个IO Model的比较如图所示:

通过上面的图片,可以发现non-blocking IO 和 asynchronous IO 的区别还是很明显的。
IO复用:为了解释这个名词,首先来理解下复用这个概念,复用也就是共用的意思,这样理解还是有些抽象,
为此,咱们来理解下复用在通信领域的使用,在通信领域中为了充分利用网络连接的物理介质,
往往在同一条网络链路上采用时分复用或频分复用的技术使其在同一链路上传输多路信号。
到这里我们就基本上理解了复用的含义,
即公用某个“介质”来尽可能多的做同一类(性质)的事,那IO复用的“介质”是什么呢?
为此我们首先来看看服务器编程的模型,客户端发来的请求服务端会产生一个进程来对其进行服务,
每当来一个客户请求就产生一个进程来服务,然而进程不可能无限制的产生,因此为了解决大量客户端访问的问题,
# 引入了IO复用技术,即:一个进程可以同时对多个客户请求进行服务。
# 也就是说IO复用的“介质”是进程(准确的说复用的是select和poll,因为进程也是靠调用select和poll来实现的),
# 复用一个进程(select和poll)来对多个IO进行服务,
虽然客户端发来的IO是并发的但是IO所需的读写数据多数情况下是没有准备好的,
因此就可以利用一个函数(select和poll)来监听IO所需的这些数据的状态,一旦IO有数据可以进行读写了,
进程就来对这样的IO进行服务。
理解完IO复用后,我们在来看下实现IO复用中的三个API(select、poll和epoll)的区别和联系
select,poll,epoll都是IO多路复用的机制,I/O多路复用就是通过一种机制,可以监视多个描述符,
一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知应用程序进行相应的读写操作。
但select,poll,epoll本质上都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,
而异步I/O则无需自己负责进行读写,异步I/O的实现会负责把数据从内核拷贝到用户空间。三者的原型如下所示:
int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
1.select的第一个参数nfds为fdset集合中最大描述符值加1,fdset是一个位数组,其大小限制为__FD_SETSIZE(1024),
位数组的每一位代表其对应的描述符是否需要被检查。第二三四参数表示需要关注读、写、错误事件的文件描述符位数组,
这些参数既是输入参数也是输出参数,可能会被内核修改用于标示哪些描述符上发生了关注的事件,
所以每次调用select前都需要重新初始化fdset。timeout参数为超时时间,该结构会被内核修改,其值为超时剩余的时间。
select的调用步骤如下:
(1)使用copy_from_user从用户空间拷贝fdset到内核空间
(2)注册回调函数__pollwait
(3)遍历所有fd,调用其对应的poll方法(对于socket,这个poll方法是sock_poll,
sock_poll根据情况会调用到tcp_poll,udp_poll或者datagram_poll)
(4)以tcp_poll为例,其核心实现就是__pollwait,也就是上面注册的回调函数。
(5)__pollwait的主要工作就是把current(当前进程)挂到设备的等待队列中,不同的设备有不同的等待队列,
对于tcp_poll 来说,其等待队列是sk->sk_sleep(注意把进程挂到等待队列中并不代表进程已经睡眠了)。
在设备收到一条消息(网络设备)或填写完文件数 据(磁盘设备)后,会唤醒设备等待队列上睡眠的进程,
这时current便被唤醒了。
(6)poll方法返回时会返回一个描述读写操作是否就绪的mask掩码,根据这个mask掩码给fd_set赋值。
(7)如果遍历完所有的fd,还没有返回一个可读写的mask掩码,则会调用schedule_timeout是调用select的进程(也就是 current)进入睡眠。
当设备驱动发生自身资源可读写后,会唤醒其等待队列上睡眠的进程。
如果超过一定的超时时间(schedule_timeout 指定),还是没人唤醒,则调用select的进程会重新被唤醒获得CPU,
进而重新遍历fd,判断有没有就绪的fd。
(8)把fd_set从内核空间拷贝到用户空间。
总结下select的几大缺点:
(1)每次调用select,都需要把fd集合从用户态拷贝到内核态,这个开销在fd很多时会很大
(2)同时每次调用select都需要在内核遍历传递进来的所有fd,这个开销在fd很多时也很大
(3)select支持的文件描述符数量太小了,默认是1024
2.poll与select不同,通过一个pollfd数组向内核传递需要关注的事件,故没有描述符个数的限制,
pollfd中的events字段和revents分别用于标示关注的事件和发生的事件,故pollfd数组只需要被初始化一次。
poll的实现机制与select类似,其对应内核中的sys_poll,只不过poll向内核传递pollfd数组,然后对pollfd中的每个描述符进行poll,相比处理fdset来说,poll效率更高。
poll返回后,需要对pollfd中的每个元素检查其revents值,来得指事件是否发生。
3.直到Linux2.6才出现了由内核直接支持的实现方法,那就是epoll,被公认为Linux2.6下性能最好的多路I/O就绪通知方法。
epoll可以同时支持水平触发和边缘触发(Edge Triggered,只告诉进程哪些文件描述符刚刚变为就绪状态,
它只说一遍,如果我们没有采取行动,那么它将不会再次告知,这种方式称为边缘触发),
理论上边缘触发的性能要更高一些,但是代码实现相当复杂。
epoll同样只告知那些就绪的文件描述符,而且当我们调用epoll_wait()获得就绪文件描述符时,返回的不是实际的描述符,
而是一个代表就绪描述符数量的值,你只需要去epoll指定的一个数组中依次取得相应数量的文件描述符即可,
这里也使用了内存映射(mmap)技术,这样便彻底省掉了这些文件描述符在系统调用时复制的开销。
另一个本质的改进在于epoll采用基于事件的就绪通知方式。
在select/poll中,进程只有在调用一定的方法后,内核才对所有监视的文件描述符进行扫描,
而epoll事先通过epoll_ctl()来注册一个文件描述符,一旦基于某个文件描述符就绪时,
内核会采用类似callback的回调机制,迅速激活这个文件描述符,当进程调用epoll_wait()时便得到通知。
epoll既然是对select和poll的改进,就应该能避免上述的三个缺点。那epoll都是怎么解决的呢?
在此之前,我们先看一下epoll 和select和poll的调用接口上的不同,select和poll都只提供了一个函数——select或者poll函数。
而epoll提供了三个函 数,epoll_create,epoll_ctl和epoll_wait,
epoll_create是创建一个epoll句柄;epoll_ctl是注 册要监听的事件类型;epoll_wait则是等待事件的产生。
对于第一个缺点,epoll的解决方案在epoll_ctl函数中。每次注册新的事件到epoll句柄中时(在epoll_ctl中指定 EPOLL_CTL_ADD),
会把所有的fd拷贝进内核,而不是在epoll_wait的时候重复拷贝。epoll保证了每个fd在整个过程中只会拷贝 一次。
对于第二个缺点,epoll的解决方案不像select或poll一样每次都把current轮流加入fd对应的设备等待队列中,
而只在 epoll_ctl时把current挂一遍(这一遍必不可少)并为每个fd指定一个回调函数,当设备就绪,
唤醒等待队列上的等待者时,就会调用这个回调 函数,而这个回调函数会把就绪的fd加入一个就绪链表)。
epoll_wait的工作实际上就是在这个就绪链表中查看有没有就绪的fd
(利用 schedule_timeout()实现睡一会,判断一会的效果,和select实现中的第7步是类似的)。
对于第三个缺点,epoll没有这个限制,它所支持的FD上限是最大可以打开文件的数目,这个数字一般远大于2048,
举个例子, 在1GB内存的机器上大约是10万左右,具体数目可以cat /proc/sys/fs/file-max察看,
一般来说这个数目和系统内存关系很大。
总结:
(1)select,poll实现需要自己不断轮询所有fd集合,直到设备就绪,期间可能要睡眠和唤醒多次交替。而epoll其实也需要调用 epoll_wait不断轮询就绪链表,
期间也可能多次睡眠和唤醒交替,但是它是设备就绪时,调用回调函数,把就绪fd放入就绪链表中,并唤醒在 epoll_wait中进入睡眠的进程。
虽然都要睡眠和交替,但是select和poll在“醒着”的时候要遍历整个fd集合,而epoll在“醒着”的 时候只要判断一下就绪链表是否为空就行了,这节省了大量的CPU时间,
这就是回调机制带来的性能提升。
(2)select,poll每次调用都要把fd集合从用户态往内核态拷贝一次,并且要把current往设备等待队列中挂一次,而epoll只要 一次拷贝,
而且把current往等待队列上挂也只挂一次(在epoll_wait的开始,注意这里的等待队列并不是设备等待队列,只是一个epoll内 部定义的等待队列),这也能节省不少的开销。
# select,poll,epoll
# 这三种IO多路复用模型在不同的平台有着不同的支持,而epoll在windows下就不支持,好在我们有selectors模块,帮我们默认选择当前平台下最合适的
例子:
#服务端
from socket import *
import selectors
sel=selectors.DefaultSelector()
def accept(server_fileobj,mask):
conn,addr=server_fileobj.accept()
sel.register(conn,selectors.EVENT_READ,read)
def read(conn,mask):
try:
data=conn.recv(1024)
if not data:
print(‘closing‘,conn)
sel.unregister(conn)
conn.close()
return
conn.send(data.upper()+b‘_SB‘)
except Exception:
print(‘closing‘, conn)
sel.unregister(conn)
conn.close()
server_fileobj=socket(AF_INET,SOCK_STREAM)
server_fileobj.setsockopt(SOL_SOCKET,SO_REUSEADDR,1)
server_fileobj.bind((‘127.0.0.1‘,8088))
server_fileobj.listen(5)
server_fileobj.setblocking(False) #设置socket的接口为非阻塞
sel.register(server_fileobj,selectors.EVENT_READ,accept) #相当于网select的读列表里append了一个文件句柄server_fileobj,并且绑定了一个回调函数accept
while True:
events=sel.select() #检测所有的fileobj,是否有完成wait data的
for sel_obj,mask in events:
callback=sel_obj.data #callback=accpet
callback(sel_obj.fileobj,mask) #accpet(server_fileobj,1)
#客户端
from socket import *
c=socket(AF_INET,SOCK_STREAM)
c.connect((‘127.0.0.1‘,8088))
while True:
msg=input(‘>>: ‘)
if not msg:continue
c.send(msg.encode(‘utf-8‘))
data=c.recv(1024)
print(data.decode(‘utf-8‘))
# 基于selectors模块实现聊天
select,poll,epoll都是IO多路复用的机制。I/O多路复用就是通过一种机制,一个进程可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。但select,poll,epoll本质上都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而异步I/O则无需自己负责进行读写,异步I/O的实现会负责把数据从内核拷贝到用户空间。
int select (int n, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
select 函数监视的文件描述符分3类,分别是writefds、readfds、和exceptfds。调用后select函数会阻塞,直到有描述副就绪(有数据 可读、可写、或者有except),或者超时(timeout指定等待时间,如果立即返回设为null即可),函数返回。当select函数返回后,可以 通过遍历fdset,来找到就绪的描述符。
select目前几乎在所有的平台上支持,其良好跨平台支持也是它的一个优点。select的一 个缺点在于单个进程能够监视的文件描述符的数量存在最大限制,在Linux上一般为1024,可以通过修改宏定义甚至重新编译内核的方式提升这一限制,但 是这样也会造成效率的降低。
int poll (struct pollfd *fds, unsigned int nfds, int timeout);
不同与select使用三个位图来表示三个fdset的方式,poll使用一个 pollfd的指针实现。
struct pollfd {
int fd; /* file descriptor */
short events; /* requested events to watch */
short revents; /* returned events witnessed */
};
pollfd结构包含了要监视的event和发生的event,不再使用select“参数-值”传递的方式。同时,pollfd并没有最大数量限制(但是数量过大后性能也是会下降)。 和select函数一样,poll返回后,需要轮询pollfd来获取就绪的描述符。
从上面看,select和poll都需要在返回后,
通过遍历文件描述符来获取已经就绪的socket。事实上,同时连接的大量客户端在一时刻可能只有很少的处于就绪状态,因此随着监视的描述符数量的增长,其效率也会线性下降。
epoll是在2.6内核中提出的,是之前的select和poll的增强版本。相对于select和poll来说,epoll更加灵活,没有描述符限制。epoll使用一个文件描述符管理多个描述符,将用户关系的文件描述符的事件存放到内核的一个事件表中,这样在用户空间和内核空间的copy只需一次。
epoll操作过程需要三个接口,分别如下:
int epoll_create(int size);//创建一个epoll的句柄,size用来告诉内核这个监听的数目一共有多大
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
1. int epoll_create(int size);
创建一个epoll的句柄,size用来告诉内核这个监听的数目一共有多大,这个参数不同于select()中的第一个参数,给出最大监听的fd+1的值,参数size并不是限制了epoll所能监听的描述符最大个数,只是对内核初始分配内部数据结构的一个建议。
当创建好epoll句柄后,它就会占用一个fd值,在linux下如果查看/proc/进程id/fd/,是能够看到这个fd的,所以在使用完epoll后,必须调用close()关闭,否则可能导致fd被耗尽。
2. int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
函数是对指定描述符fd执行op操作。
struct epoll_event {
__uint32_t events; /* Epoll events */
epoll_data_t data; /* User data variable */
};
//events可以是以下几个宏的集合:
EPOLLIN :表示对应的文件描述符可以读(包括对端SOCKET正常关闭);
EPOLLOUT:表示对应的文件描述符可以写;
EPOLLPRI:表示对应的文件描述符有紧急的数据可读(这里应该表示有带外数据到来);
EPOLLERR:表示对应的文件描述符发生错误;
EPOLLHUP:表示对应的文件描述符被挂断;
EPOLLET: 将EPOLL设为边缘触发(Edge Triggered)模式,这是相对于水平触发(Level Triggered)来说的。
EPOLLONESHOT:只监听一次事件,当监听完这次事件之后,如果还需要继续监听这个socket的话,需要再次把这个socket加入到EPOLL队列里
3. int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
等待epfd上的io事件,最多返回maxevents个事件。
参数events用来从内核得到事件的集合,maxevents告之内核这个events有多大,这个maxevents的值不能大于创建epoll_create()时的size,参数timeout是超时时间(毫秒,0会立即返回,-1将不确定,也有说法说是永久阻塞)。该函数返回需要处理的事件数目,如返回0表示已超时。
在 select/poll中,进程只有在调用一定的方法后,内核才对所有监视的文件描述符进行扫描,而epoll事先通过epoll_ctl()来注册一 个文件描述符,一旦基于某个文件描述符就绪时,内核会采用类似callback的回调机制,迅速激活这个文件描述符,当进程调用epoll_wait() 时便得到通知。(此处去掉了遍历文件描述符,而是通过监听回调的的机制。这正是epoll的魅力所在。)
epoll的优点主要是一下几个方面:
如果没有大量的idle -connection或者dead-connection,epoll的效率并不会比select/poll高很多,但是当遇到大量的idle- connection,就会发现epoll的效率大大高于select/poll。
Linux IO模式及 select、poll、epoll详解
原文:https://www.cnblogs.com/51try-again/p/11078674.html