‘‘‘
列表
定义:在[]内,可以存放任意类型的值,并以逗号隔开
一般用于存放学生的爱好、课程信息等
‘‘‘
# 优先掌握操作
# 1、按索引取值(正向存取+反向存取):即可存也可取
# 2、切片(顾头不顾尾,步长)
# 3、长度
# 4、成员运算in 和not in
# 5、追加
# 6、删除
student = [‘刘昕航‘, ‘陈伟军‘, ‘闫顺‘] print(student[1]) students_info = [‘刘昕航‘, 21, [‘游戏‘, ‘电影‘], 172.5] # 取我的所有爱好 print(students_info[2]) # 取我的第二个爱好 print(students_info[2][1]) # 优先掌握操作 # 1、按索引取值(正向存取+反向存取):即可存也可取 print(students_info[-1]) # 2、切片(顾头不顾尾,步长) print(students_info[0:4:2]) # 3、长度 print(len(students_info)) # 4、成员运算in 和not in print(‘刘昕航‘ in students_info) print(‘刘昕航‘ not in students_info) # 5、追加 # 在student_info列表末尾追加一个值 students_info.append(‘安徽省合肥市‘) print(students_info) # 6、删除 # 删除列表中索引为2的值 del students_info[2] print(students_info)

# 需要掌握的
# 1、index:获取列表中某个值的索引
# 2、count获取列表中某个值的数量
# 3、取值:默认取列表中最后一个值,类似于删除
# 若pop()括号中给了索引,则取索引对应的值
# 4、移除,把列表中某个值的第一个值移除
# 5、插入值
# 1、index:获取列表中某个值的索引 students_info = [‘刘昕航‘, 21, [‘游戏‘, ‘电影‘], 172.5, 21] print(students_info.index(21)) # 2、count获取列表中某个值的数量 print(students_info.count(21)) # 3、取值:默认取列表中最后一个值,类似于删除 # 若pop()括号中给了索引,则取索引对应的值 students_info.pop() print(students_info) # 取出列表中索引为2的值,并赋值给old old = students_info.pop(2) print(old) print(students_info) # 4、移除,把列表中某个值的第一个值移除 students_info.remove(21) print(students_info) name = students_info.remove(‘刘昕航‘) print(name) print(students_info) # 5、插入值 students_info = [‘刘昕航‘, 21, [‘游戏‘, ‘电影‘], 172.5] # 在student_info中,索引为2的位置插入“合肥学院” students_info.insert(2, ‘合肥学院‘) print(students_info)

‘‘‘
元组
定义:在()内可以可以存放任意类型的值,并以逗号隔开。
注意:元组与列表不一样的地方就是元组只能在定义的时候初始化值,之后不能对其修改
优点:在内存中占用的资源比列表更小
‘‘‘
# 定义
tuple1 = (1, 2, 3, ‘四‘, ‘五‘) # tuple1(1, 2, 3, ‘四‘, ‘五‘)
print(tuple1)
# 优先掌握操作
# 1、按索引取值(正向存取+反向存取):只能取
# 2、切片(顾头不顾尾,步长)
# 3、长度
# 4、成员运算in 和not in
# 5、循环
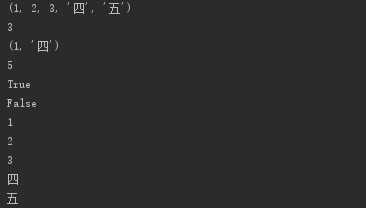
tuple1 = (1, 2, 3, ‘四‘, ‘五‘) # tuple1(1, 2, 3, ‘四‘, ‘五‘) print(tuple1) # 1、按索引取值(正向存取+反向存取):只能取 print(tuple1[2]) # 2、切片(顾头不顾尾,步长) print(tuple1[0:5:3]) # 3、长度 print(len(tuple1)) # 4、成员运算in 和not in print(1 in tuple1) print(1 not in tuple1) # 5、循环 for line in tuple1: print(line )
‘‘‘
不可变类型:
变量的值修改后,内存地址一定不一样。
数字类型:
int
float
字符串类型:
str
元组类型:
tuple
可变类型:
列表类型:
list
字典类型
dict
‘‘‘
# 不可变类型
# int
# float
# str
# 可变类型
# 列表
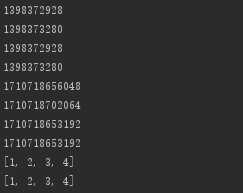
# 不可变类型 # int number = 100 print(id(number)) number = 111 print(id(number)) # float sal = 100 print(id(sal)) sal = 111 print(id(sal)) # str str1 = ‘hello python‘ print(id(str1)) str2 = str1.replace(‘hello‘, ‘like‘) print(id(str2)) # 可变类型 # 列表 list1 = [1, 2, 3] list2 = list1 list1.append(4) # list1和list2指向的是同一地址 print(id(list1)) print(id(list2)) print(list1) print(list2)
‘‘‘
字典类型
作用:在{}内,以逗号隔开存放多个值,以key—value存取,取值速度快。
定义:key必须是不可变类型,value可以是任意类型
‘‘‘
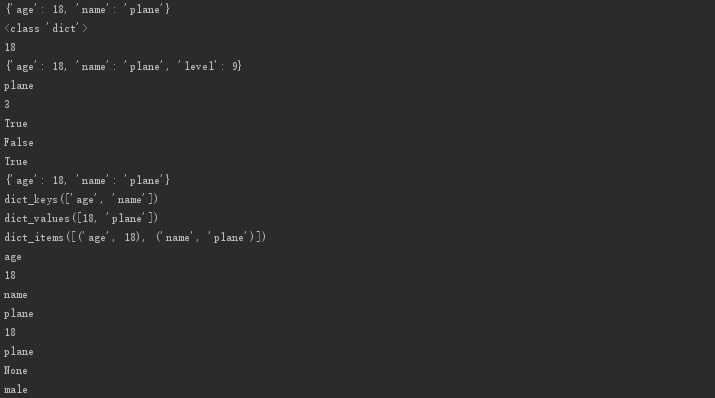
# dict1 = dict({‘age‘:18, ‘name‘:‘plane‘}) dict1 = {‘age‘: 18, ‘name‘: ‘plane‘} print(dict1) print(type(dict1)) # 取值,字典名+[],在括号内写值对应的key print(dict1[‘age‘]) # 优先掌握的操作 # 1、按key取值,可存可取 # 存一个level:9的值到dict1字典中 dict1[‘level‘] = 9 print(dict1) print(dict1[‘name‘]) # 2、长度 print(len(dict1)) # 3、成员运算in和not in 只能判断字典中的key print(‘name‘ in dict1) print(‘plane‘ in dict1) print(‘plane‘ not in dict1) # 4、删除 del dict1[‘level‘] print(dict1) # 5、键keys(),值value(),键值对items() # 得到字典中所有key print(dict1.keys()) # 得到字典中所有值values print(dict1.values()) # 得到字典当中所有items print(dict1.items()) # 6、循环 # 循环遍历字典中所有的key for key in dict1: print(key) print(dict1[key]) # get dict1 = {‘age‘: 18, ‘name‘: ‘plane‘} print(dict1.get(‘age‘)) # []取值 print(dict1[‘name‘]) # get取值 print(dict1.get(‘sex‘)) # 若找不到,为其设置一个默认值 print(dict1.get(‘sex‘, ‘male‘))
‘‘‘
if判断:
语法:
if判断条件
#若条件成立,则执行此处代码
逻辑代码
elif
#若条件成立,则执行此处代码
逻辑代码
else:
#若以上判断都不成立,则执行此处代码
逻辑代码
‘‘‘
# 判断两数大小 x = 20 y = 30 z = 40 if x > y: print(x) elif z > y: print(z) else: print(y)

‘‘‘
while循环
语法:
while 条件判断
#成立执行此处
逻辑代码
break #跳出本层循环
continue #结束本次循环,进入下次循环
‘‘‘
str1 = ‘tank‘ while True: name = input(‘请输入猜测字符:‘).strip() if name == ‘tank‘: print(‘success!‘) break print(‘重新输入‘) # 限制循环次数 str1 = ‘tank‘ # 初始值 num = 0 # 1 2 3 while num < 3: name = input(‘请输入猜测字符:‘).strip() if name == ‘tank‘: print(‘success!‘) break print(‘重新输入‘) num += 1

‘‘‘
文件处理:
open()
写文件:wt
读文件:rt
追加写文件:at
注意:必须指定字符编码,以什么方式写就得以什么方式打开。如:utf-8
1
执行python文件文件过程:
1.先启动python解释器,加载到内存中。
2.把写好的python文件加载到解释器中。
3.检测python语法,执行代码。
SyntaxError:语法错误!
打开文件会产生两种资源:
1.python程序
2.操作系统打开文件
‘‘‘
#参数一:文件的绝对路径
#参数二:操作文件的模式
#参数三:encoding指定字符编码
f = open(‘file.txt‘, mode=‘wt‘, encoding=‘utf-8‘) f.write(‘tank‘) f.close() #关闭操作系统文件资源 #追加写文本文件 a = open(‘file.txt‘, ‘a‘, encoding=‘utf-8‘) a.write(‘\n合肥学院‘) a.close()
‘‘‘
文件处理之上下文管理:
#with可以管理open打开的文件,
会在with执行完毕之后自动调用close()关闭文件
with open() as f "句柄"
‘‘‘
#写 with open (‘file.txt‘, ‘w‘ ,encoding=‘utf-8‘) as f: f.write(‘墨菲定律‘) #读 with open (‘file.txt‘, ‘r‘ ,encoding=‘utf-8‘) as f: res = f.read() print(res) #追加 with open (‘file.txt‘, ‘a‘ ,encoding=‘utf-8‘) as f: f.write(‘围城‘) #读取相片cxk.jpg with open (‘cxk.jpg‘, ‘rb‘) as f: res = f.read() print(res) jpg = res #把cxk.jpg的二进制流写入cxk_copy.jpg with open(‘cxk_copy.jpg‘, ‘wb‘) as f_w: f_w.write(jpg)
#with管理多个文件
#通过with来管理open打开的两个文件句柄f_r,f_w
with open(‘xck.jpg‘, ‘rb‘) as f_w, open(‘cxk_copy.jpg‘, ‘wb‘) as f_r: #通过f_r句柄把图片的二进制流读取出来 res = f_r.read() #通过f_w句柄把图片的二进制写入cxk_copy.jpg文件中 f_w.write(res)
‘‘‘
函数
什么是函数?
函数其实是一种工具。
使用的函数的好处:
1.解决代码冗余问题。
2.使代码结构更清晰
3.易管理
函数的使用必须遵循:先定义,后调用。
函数定义语法:
def 函数名(参数1 ,参数2…):
#注释:声明函数
逻辑代码
return 返回值
def:defind 定义
函数名:必须看命知其意
():接受外部传入的参数。
注释:用来声明函数的作用。
return:返回给调用者的值。
定义函数的三种形式:
1.无参函数:不需要接受外部传入的参数。
2.有参函数:需要接受外部传入的参数。
3.空函数:pass
‘‘‘
#1.无参函数
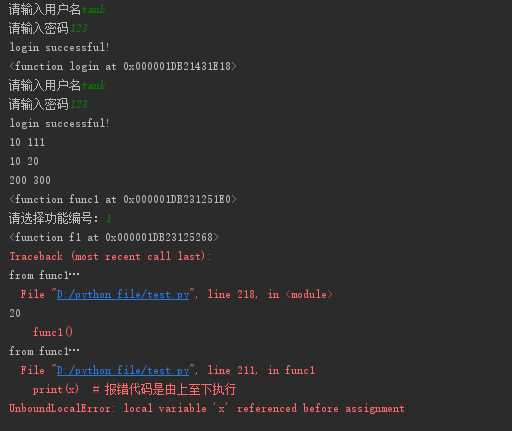
def login(): user = input(‘请输入用户名‘).strip() pwd = input(‘请输入密码‘).strip() if user == ‘tank‘ and pwd == ‘123‘: print(‘login successful!‘) else: print(‘login error!‘) #函数内存地址 print(login) #函数调用 login()
#2.有参函数
#username,password 用来接受外部传入的值
def login(username, password): user = input(‘请输入用户名‘).strip() pwd = input(‘请输入密码‘).strip() if user == ‘tank‘ and pwd == ‘123‘: print(‘login successful!‘) else: print(‘login error!‘) #函数调用 #若函数在定义时需要接收参数,调用者必须为其传参 login(‘tank‘, ‘123‘)
#3.空函数
‘‘‘
ATM:
1.登录
2.注册
3.提现
4.取款
5.转账
6.还款
‘‘‘
#登录功能 def login(): #代表什么都不做 pass #注册功能 def register(): # 代表什么都不做 pass #还款功能 def repay(): # 代表什么都不做 pass #……
#参数的参数
#在定义阶段:x,y称之为形参。
def func(x,y): print(x,y)
在调用阶段:10,100称之为实参。
func(10,100) #10 100
‘‘‘
关键字参数:
关键字实参
按照关键字传参
‘‘‘
#位置形参想x,y
def func(x, y): print(x, y) #在调用阶段:x=10,y=100称之为关键字参数 func(y=111, x=10) #10 111 #不能少传 #func(y=111) #报错TypeError #不能多传 #func(y=111,x=222,z=‘333‘) #报错TypeError
#默认参数:在定义阶段,为参数默认值
def foo(x=10, y=20): print(x, y) #不传参,则使用默认参数 foo() #传参,使用传入的参数 foo(200, 300)
‘‘‘
函数嵌套的定义:
在函数内部定义函数。
函数对象:
函数的名称空间
函数名称空间:
内置:
python解析器自带的都称之为"内置名称空间"。
全局:
所有顶着头写的变量、函数…都称之为"全名称空间"
局部:
在函数内部定义的,都称之为"局部名称空间"
名称空间加载顺序:
内置-->全局-->局部
名称空间查找顺序:
局部-->全局-->内置
‘‘‘
#函数嵌套定义
def fun1(): print(‘from func1…‘) def func2(): print(‘from func2…‘)
#函数对象
print(func1) def f1(): pass def f2(): pass dic1 = {‘1‘: f1, ‘2‘: f2} choice = input(‘请选择功能编号:‘) if choice == ‘1‘ print(dict1[choice]) dict1[choice]() elif choice ==‘2‘: print(dic1[choice]) dict1[choice]() x=10
#名称空间
#函数的嵌套定义
def func1(): x=20 print(‘from func1…‘) print(x) def func2(): print(‘from func1…‘) func1()
def func1(): print(‘from func1…‘) print(x) #报错代码是由上至下执行 x = 20 def func2(): print(‘from func1…‘) func1()
原文:https://www.cnblogs.com/lxhdeboke/p/11087039.html