上篇《Spark(四十九):Spark On YARN启动流程源码分析(一)》我们讲到启动SparkContext初始化,ApplicationMaster启动资源中,讲解的内容明显不完整。
本章将针对yarn-cluster(--master yarn –deploy-mode cluster)模式下全面进行代码补充解读:
使用spark-submit.sh提交任务:
#/bin/sh #LANG=zh_CN.utf8 #export LANG export SPARK_KAFKA_VERSION=0.10 export LANG=zh_CN.UTF-8 jarspath=‘‘ for file in `ls /home/dx/works/myapp001/sparks/*.jar` do jarspath=${file},$jarspath done jarspath=${jarspath%?} echo $jarspath spark-submit --jars $jarspath --properties-file ./conf/spark-properties-myapp001.conf --verbose --master yarn --deploy-mode cluster \#或者client --name Streaming-$1-$2-$3-$4-$5-Agg-Parser --num-executors 16 --executor-memory 6G --executor-cores 2 --driver-memory 2G --driver-java-options "-XX:+TraceClassPaths" --class com.dx.myapp001.Main /home/dx/works/myapp001/lib/application-jar.jar $1 $2 $3 $4 $5
运行spark-submit.sh,实际上执行的是org.apache.spark.deploy.SparkSubmit的main:
1)--master yarn --deploy-mode:cluster
调用YarnClusterApplication进行提交
YarnClusterApplication这是org.apache.spark.deploy.yarn.Client中的一个内部类,在YarnClusterApplication中new了一个Client对象,并调用了run方法
private[spark] class YarnClusterApplication extends SparkApplication { override def start(args: Array[String], conf: SparkConf): Unit = { // SparkSubmit would use yarn cache to distribute files & jars in yarn mode, // so remove them from sparkConf here for yarn mode. conf.remove("spark.jars") conf.remove("spark.files") new Client(new ClientArguments(args), conf).run() } }
2)--master yarn --deploy-mode:client[可忽略]
调用application-jar.jar自身main函数,执行的是JavaMainApplication
/** * Implementation of SparkApplication that wraps a standard Java class with a "main" method. * * Configuration is propagated to the application via system properties, so running multiple * of these in the same JVM may lead to undefined behavior due to configuration leaks. */ private[deploy] class JavaMainApplication(klass: Class[_]) extends SparkApplication { override def start(args: Array[String], conf: SparkConf): Unit = { val mainMethod = klass.getMethod("main", new Array[String](0).getClass) if (!Modifier.isStatic(mainMethod.getModifiers)) { throw new IllegalStateException("The main method in the given main class must be static") } val sysProps = conf.getAll.toMap sysProps.foreach { case (k, v) => sys.props(k) = v } mainMethod.invoke(null, args) } }
从JavaMainApplication实现可以发现,JavaSparkApplication中调用start方法时,只是通过反射执行application-jar.jar的main函数。
当yarn-custer模式中,YarnClusterApplication类中运行的是Client中run方法,Client#run()中实现了任务提交流程:
/** * Submit an application to the ResourceManager. * If set spark.yarn.submit.waitAppCompletion to true, it will stay alive * reporting the application‘s status until the application has exited for any reason. * Otherwise, the client process will exit after submission. * If the application finishes with a failed, killed, or undefined status, * throw an appropriate SparkException. */ def run(): Unit = { this.appId = submitApplication() if (!launcherBackend.isConnected() && fireAndForget) { val report = getApplicationReport(appId) val state = report.getYarnApplicationState logInfo(s"Application report for $appId (state: $state)") logInfo(formatReportDetails(report)) if (state == YarnApplicationState.FAILED || state == YarnApplicationState.KILLED) { throw new SparkException(s"Application $appId finished with status: $state") } } else { val YarnAppReport(appState, finalState, diags) = monitorApplication(appId) if (appState == YarnApplicationState.FAILED || finalState == FinalApplicationStatus.FAILED) { diags.foreach { err => logError(s"Application diagnostics message: $err") } throw new SparkException(s"Application $appId finished with failed status") } if (appState == YarnApplicationState.KILLED || finalState == FinalApplicationStatus.KILLED) { throw new SparkException(s"Application $appId is killed") } if (finalState == FinalApplicationStatus.UNDEFINED) { throw new SparkException(s"The final status of application $appId is undefined") } } }
其中run的方法流程:
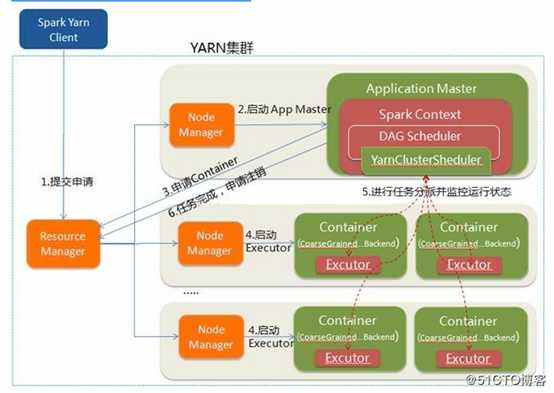
1) 运行submitApplication()初始化yarn,使用yarn进行资源管理,并运行spark任务提交接下来的流程:分配driver container,然后在Driver Containe中启动ApplicaitonMaster,ApplicationMaster中初始化SparkContext。
2) 状态成功,上报执行进度等信息。
3) 状态失败,报告执行失败。
其中submitApplication()的实现流程:
/** * Submit an application running our ApplicationMaster to the ResourceManager. * * The stable Yarn API provides a convenience method (YarnClient#createApplication) for * creating applications and setting up the application submission context. This was not * available in the alpha API. */ def submitApplication(): ApplicationId = { var appId: ApplicationId = null try { launcherBackend.connect() yarnClient.init(hadoopConf) yarnClient.start() logInfo("Requesting a new application from cluster with %d NodeManagers" .format(yarnClient.getYarnClusterMetrics.getNumNodeManagers)) // Get a new application from our RM val newApp = yarnClient.createApplication() val newAppResponse = newApp.getNewApplicationResponse() appId = newAppResponse.getApplicationId() new CallerContext("CLIENT", sparkConf.get(APP_CALLER_CONTEXT), Option(appId.toString)).setCurrentContext() // Verify whether the cluster has enough resources for our AM verifyClusterResources(newAppResponse) // Set up the appropriate contexts to launch our AM val containerContext = createContainerLaunchContext(newAppResponse) val appContext = createApplicationSubmissionContext(newApp, containerContext) // Finally, submit and monitor the application logInfo(s"Submitting application $appId to ResourceManager") yarnClient.submitApplication(appContext) launcherBackend.setAppId(appId.toString) reportLauncherState(SparkAppHandle.State.SUBMITTED) appId } catch { case e: Throwable => if (appId != null) { cleanupStagingDir(appId) } throw e } }
这段代码主要实现向ResourceManager申请资源,启动Container并运行ApplicationMaster。
其中createContainerLaunchContext(newAppResponse)中对应的启动主类amClass分支逻辑如下:
val amClass =
if (isClusterMode) {
Utils.classForName("org.apache.spark.deploy.yarn.ApplicationMaster").getName
} else {
Utils.classForName("org.apache.spark.deploy.yarn.ExecutorLauncher").getName
}
当yarn-cluster模式下,会先通过Client#run()方法中调用Client#submitApplication()向Yarn的Resource Manager申请一个container,来启动ApplicationMaster。
启动ApplicationMaster的执行脚本示例:
[dx@hadoop143 bin]$ps -ef|grep ApplicationMaster # yarn账户在执行 /bin/bash -c /usr/java/jdk1.8.0_171-amd64/bin/java -server -Xmx2048m -Djava.io.tmpdir=/mnt/data3/yarn/nm/usercache/dx/appcache/application_1554704591622_0340/container_1554704591622_0340_01_000001/tmp -Dspark.yarn.app.container.log.dir=/mnt/data4/yarn/container-logs/application_1554704591622_0340/container_1554704591622_0340_01_000001 org.apache.spark.deploy.yarn.ApplicationMaster --class ‘com.dx.myapp001.Main‘ --jar file:/home/dx/works/myapp001/lib/application-jar.jar --arg ‘-type‘ --arg ‘0‘ --properties-file /mnt/data3/yarn/nm/usercache/dx/appcache/application_1554704591622_0340/container_1554704591622_0340_01_000001/__spark_conf__/__spark_conf__.properties 1> /mnt/data4/yarn/container-logs/application_1554704591622_0340/container_1554704591622_0340_01_000001/stdout 2> /mnt/data4/yarn/container-logs/application_1554704591622_0340/container_1554704591622_0340_01_000001/stderr
ApplicaitonMaster启动过程会通过半生类ApplicationMaster的main作为入口,执行:
private var master: ApplicationMaster = _ def main(args: Array[String]): Unit = { SignalUtils.registerLogger(log) val amArgs = new ApplicationMasterArguments(args) master = new ApplicationMaster(amArgs) System.exit(master.run()) }
通过ApplicationMasterArguments类对args进行解析,然后将解析后的amArgs作为master初始化的参数,并执行master#run()方法启动ApplicationMaster。
在ApplicationMaster类实例化中,ApplicationMaster的属性包含以下:
private val isClusterMode = args.userClass != null private val sparkConf = new SparkConf() if (args.propertiesFile != null) { Utils.getPropertiesFromFile(args.propertiesFile).foreach { case (k, v) => sparkConf.set(k, v) } } private val securityMgr = new SecurityManager(sparkConf) private var metricsSystem: Option[MetricsSystem] = None // Set system properties for each config entry. This covers two use cases: // - The default configuration stored by the SparkHadoopUtil class // - The user application creating a new SparkConf in cluster mode // // Both cases create a new SparkConf object which reads these configs from system properties. sparkConf.getAll.foreach { case (k, v) => sys.props(k) = v } private val yarnConf = new YarnConfiguration(SparkHadoopUtil.newConfiguration(sparkConf)) private val userClassLoader = { val classpath = Client.getUserClasspath(sparkConf) val urls = classpath.map { entry => new URL("file:" + new File(entry.getPath()).getAbsolutePath()) } if (isClusterMode) { if (Client.isUserClassPathFirst(sparkConf, isDriver = true)) { new ChildFirstURLClassLoader(urls, Utils.getContextOrSparkClassLoader) } else { new MutableURLClassLoader(urls, Utils.getContextOrSparkClassLoader) } } else { new MutableURLClassLoader(urls, Utils.getContextOrSparkClassLoader) } } private val client = doAsUser { new YarnRMClient() } private var rpcEnv: RpcEnv = null // In cluster mode, used to tell the AM when the user‘s SparkContext has been initialized. private val sparkContextPromise = Promise[SparkContext]()
ApplicationMaster属性解释:
ApplicationMaster#run()->ApplicationMaster#runImpl,在ApplicationMaster#runImpl方法中包含以下比较重要分支逻辑:
if (isClusterMode) { runDriver() } else { runExecutorLauncher() }
因为args.userClass不为null,因此isCusterMode为true,则执行runDriver()方法。
ApplicationMaster#runDriver如下:
private def runDriver(): Unit = { addAmIpFilter(None) userClassThread = startUserApplication() // This a bit hacky, but we need to wait until the spark.driver.port property has // been set by the Thread executing the user class. logInfo("Waiting for spark context initialization...") val totalWaitTime = sparkConf.get(AM_MAX_WAIT_TIME) try { val sc = ThreadUtils.awaitResult(sparkContextPromise.future, Duration(totalWaitTime, TimeUnit.MILLISECONDS)) if (sc != null) { rpcEnv = sc.env.rpcEnv val userConf = sc.getConf val host = userConf.get("spark.driver.host") val port = userConf.get("spark.driver.port").toInt registerAM(host, port, userConf, sc.ui.map(_.webUrl)) val driverRef = rpcEnv.setupEndpointRef( RpcAddress(host, port), YarnSchedulerBackend.ENDPOINT_NAME) createAllocator(driverRef, userConf) } else { // Sanity check; should never happen in normal operation, since sc should only be null // if the user app did not create a SparkContext. throw new IllegalStateException("User did not initialize spark context!") } resumeDriver() userClassThread.join() } catch { case e: SparkException if e.getCause().isInstanceOf[TimeoutException] => logError( s"SparkContext did not initialize after waiting for $totalWaitTime ms. " + "Please check earlier log output for errors. Failing the application.") finish(FinalApplicationStatus.FAILED, ApplicationMaster.EXIT_SC_NOT_INITED, "Timed out waiting for SparkContext.") } finally { resumeDriver() } }
其执行流程如下:
1) 初始化userClassThread=startUserApplication(),运行用户定义的代码,通过反射运行application_jar.jar(sparksubmit命令中--class指定的类)的main函数;
2) 初始化SparkContext,通过sparkContextPromise来获取初始化SparkContext,并设定最大等待时间。
a) 这也充分证实了driver是运行在ApplicationMaster上(SparkContext相当于driver);
b) 该SparkContext的真正初始化是在application_jar.jar的代码中执行,通过反射执行的。
3) resumeDriver()当初始化SparkContext完成后,恢复用户线程。
4) userClassThread.join()阻塞方式等待反射application_jar.jar的main执行完成。
在spark-submit任务提交过程中,当采用spark-submit --master yarn --deploy-mode cluster时,SparkContext(driver)初始化是在ApplicationMaster中子线程中,SparkContext初始化是运行在该
@volatile private var userClassThread: Thread = _
// In cluster mode, used to tell the AM when the user‘s SparkContext has been initialized. private val sparkContextPromise = Promise[SparkContext]()
线程下
val sc = ThreadUtils.awaitResult(sparkContextPromise.future,
Duration(totalWaitTime, TimeUnit.MILLISECONDS))
sparkContextPromise是怎么拿到userClassThread(反射执行用户代码线程)中的SparkContext的实例呢?
回答:
这个是在SparkContext初始化TaskScheduler时,yarn-cluster模式对应的是YarnClusterScheduler,它里边有一个后启动钩子:
/** * This is a simple extension to ClusterScheduler - to ensure that appropriate initialization of * ApplicationMaster, etc is done */ private[spark] class YarnClusterScheduler(sc: SparkContext) extends YarnScheduler(sc) { logInfo("Created YarnClusterScheduler") override def postStartHook() { ApplicationMaster.sparkContextInitialized(sc) super.postStartHook() logInfo("YarnClusterScheduler.postStartHook done") } }
调用的ApplicationMaster.sparkContextInitialized()方法把SparkContext实例赋给前面的Promise对象:
private def sparkContextInitialized(sc: SparkContext) = { sparkContextPromise.synchronized { // Notify runDriver function that SparkContext is available sparkContextPromise.success(sc) // Pause the user class thread in order to make proper initialization in runDriver function. sparkContextPromise.wait() } }
然后userClassThread是调用startUserApplication()方法产生的,这之后就是列举的那一句:
val sc = ThreadUtils.awaitResult(sparkContextPromise.future,
Duration(totalWaitTime, TimeUnit.MILLISECONDS))
这句就是在超时时间内等待sparkContextPromise的Future对象返回SparkContext实例。
ü SparkContext初始化过程,通过startUserApplication()反射application_jar.jar(用来代码)中的main初始化SparkContext。
ü 如果SparkContext初始化成功,就进入:
i. 给rpcEnv赋值为初始化的SparkContext对象sc的env对象的rpcEnv.
ii. 从sc获取到userConf(SparkConf),driver host,driver port,sc.ui,并将他们作为registerAM(注册ApplicationMaster)的参数。
iii. 根据driver host、driver port和driver rpc server名称YarnSchedulerBackend.ENDPOINT_NAME获取到driver的EndpointRef对象driverRef。
iv. 调用createAllocator(driverRef, userConf)
v. resumeDriver() ---SparkContext初始化线程释放信号量(或者归还主线程)
vi. userClassThread.join()等待运行application_jar.jar的程序运行完成。
ü 如果SparkContext初始化失败,则抛出异常throw new IllegalStateException("User did not initialize spark context!")
Spark(五十一):Spark On YARN(Yarn-Cluster模式)启动流程源码分析(二)
原文:https://www.cnblogs.com/yy3b2007com/p/11087180.html