Scrapy网络爬虫
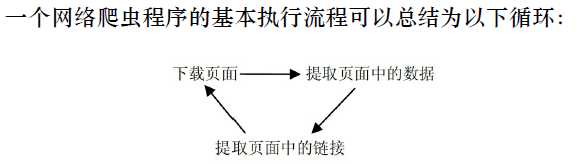


Scrapy结构图:
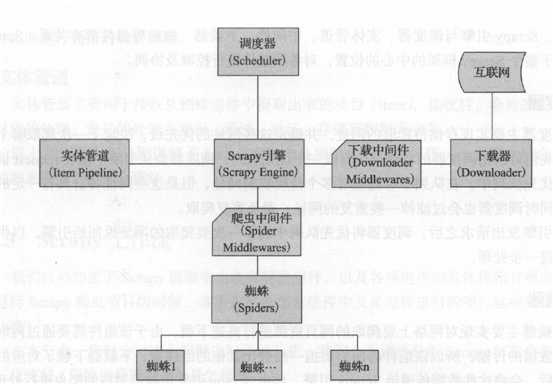
Scrapy流动图
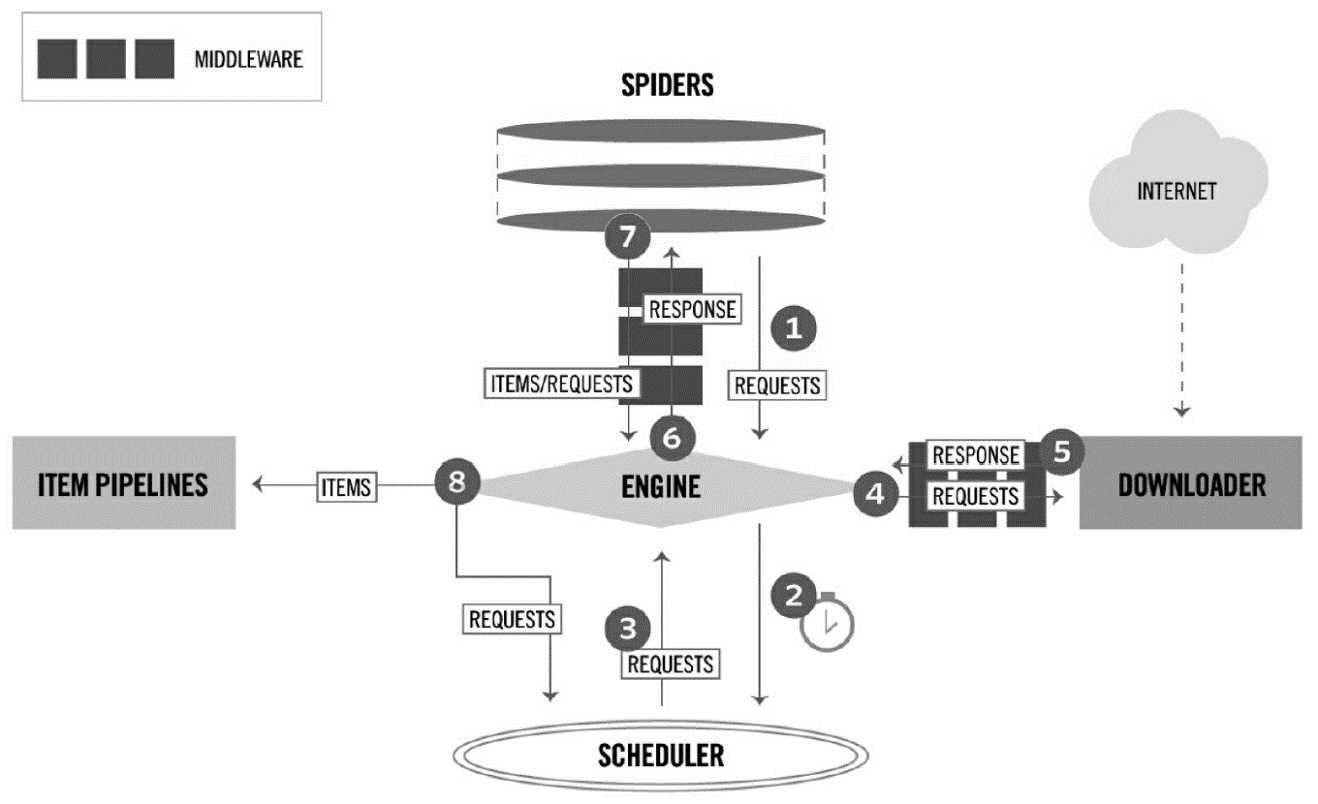
图 2-1



1、在D:\Workspace下新建ScrapyTest文件夹,即D:\Workspace\ScrapyTest
2、cd D:\Workspace\ScrapyTest
3、查看Scrapy版本:scrapy version
4、创建项目 scrapy startproject scrapy_project:
scrapy startproject weibo
5、这将创建一个名为project_name的项目目录,接下来,进入新创建的项目:cd scrapy_project
================project_name工程目录结构===============
通过命令行执行,D:\Workspace\ScrapyTest\weibo>tree /F
卷 DATA1 的文件夹 PATH 列表
卷序列号为 3A2E-EB05
D:.
│ scrapy.cfg
│
│ items.py
│ middlewares.py
│ pipelines.py
│ settings.py
│ __init__.py
│
├─spiders
│ │ __init__.py
│ │
│ └─__pycache__
└─__pycache__
====================工程目录结构=======================
scrapy.cfg(项目配置文件):
# Automatically created by: scrapy startproject
#
# For more information about the [deploy] section see:
# https://scrapyd.readthedocs.io/en/latest/deploy.html
[settings]
default = weibo.settings
[deploy]
#url = http://localhost:6800/
project = weibo
items.py(项目items文件):
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class WeiboItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
middlewares.py(项目中间件文件)
# -*- coding: utf-8 -*-
# Define here the models for your spider middleware
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
from scrapy import signals
class WeiboSpiderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the spider middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_spider_input(self, response, spider):
# Called for each response that goes through the spider
# middleware and into the spider.
# Should return None or raise an exception.
return None
def process_spider_output(self, response, result, spider):
# Called with the results returned from the Spider, after
# it has processed the response.
# Must return an iterable of Request, dict or Item objects.
for i in result:
yield i
def process_spider_exception(self, response, exception, spider):
# Called when a spider or process_spider_input() method
# (from other spider middleware) raises an exception.
# Should return either None or an iterable of Response, dict
# or Item objects.
pass
def process_start_requests(self, start_requests, spider):
# Called with the start requests of the spider, and works
# similarly to the process_spider_output() method, except
# that it doesn’t have a response associated.
# Must return only requests (not items).
for r in start_requests:
yield r
def spider_opened(self, spider):
spider.logger.info(‘Spider opened: %s‘ % spider.name)
class WeiboDownloaderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
# Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
return None
def process_response(self, request, response, spider):
# Called with the response returned from the downloader.
# Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest
return response
def process_exception(self, request, exception, spider):
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception.
# Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
pass
def spider_opened(self, spider):
spider.logger.info(‘Spider opened: %s‘ % spider.name)
pipelines.py(项目管道文件)
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don‘t forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
class WeiboPipeline(object):
def process_item(self, item, spider):
return item
settings.py(项目配置文件)
# -*- coding: utf-8 -*-
# Scrapy settings for weibo project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/latest/topics/settings.html
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = ‘weibo‘
SPIDER_MODULES = [‘weibo.spiders‘]
NEWSPIDER_MODULE = ‘weibo.spiders‘
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = ‘weibo (+http://www.yourdomain.com)‘
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# ‘Accept‘: ‘text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8‘,
# ‘Accept-Language‘: ‘en‘,
#}
# Enable or disable spider middlewares
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# ‘weibo.middlewares.WeiboSpiderMiddleware‘: 543,
#}
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# ‘weibo.middlewares.WeiboDownloaderMiddleware‘: 543,
#}
# Enable or disable extensions
# See https://doc.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# ‘scrapy.extensions.telnet.TelnetConsole‘: None,
#}
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
#ITEM_PIPELINES = {
# ‘weibo.pipelines.WeiboPipeline‘: 300,
#}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = ‘httpcache‘
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = ‘scrapy.extensions.httpcache.FilesystemCacheStorage‘
6、cd weibo
=================================================================
示例…………
================================================================
1、 (base) D:\Workspace\ScrapyTest\example>scrapy shell http://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html
进入python shell
………………
[s] Available Scrapy objects:
[s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc)
[s] crawler <scrapy.crawler.Crawler object at 0x000002367A9A7B38>
[s] item {}
[s] request <GET http://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html>
[s] response <200 http://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html>
[s] settings <scrapy.settings.Settings object at 0x000002367A9A7A58>
[s] spider <DefaultSpider ‘default‘ at 0x2367af35198>
[s] Useful shortcuts:
[s] fetch(url[, redirect=True]) Fetch URL and update local objects (by default, redirects are followed)
[s] fetch(req) Fetch a scrapy.Request and update local objects
[s] shelp() Shell help (print this help)
[s] view(response) View response in a browser
In [1]: view(response)
Out[1]: True
In [2]: sel = response.css(‘div.product_main‘)
In [3]: sel.xpath(‘./h1/text()‘).extract_first()
Out[3]: ‘A Light in the Attic‘
In [4]: quit()
可能在很多时候,使用view函数打开的页面和在浏览器直接输入url打开的页面看起来是一样的,但需要知道的是,前者是由Scrapy爬虫下载的页面,而后者是由浏览器下载的页面,有时它们是不同的。在进行页面分析时,使用view函数更加可靠。
2、 (base) D:\Workspace\ScrapyTest\example>scrapy startproject scrape_book
New Scrapy project ‘scrape_book‘, using template directory ‘s:\\users\\jiangshan\\anaconda3\\lib\\site-packages\\scrapy\\templates\\project‘, created in:
D:\Workspace\ScrapyTest\scrape_book
You can start your first spider with:
cd scrape_book
scrapy genspider example example.com
3、 (base) D:\Workspace\ScrapyTest>cd scrape_book
4、 (base) D:\Workspace\ScrapyTest\scrape_book>tree /F
卷 DATA1 的文件夹 PATH 列表
卷序列号为 3A2E-EB05
D:.
│ scrapy.cfg
│
└─scrape_book
│ items.py
│ middlewares.py
│ pipelines.py
│ settings.py
│ __init__.py
│
├─spiders
│ │ __init__.py
│ │
│ └─__pycache__
└─__pycache__
5、 (base) D:\Workspace\ScrapyTest\scrape_book>scrapy genspider books books.toscrape.com
Created spider ‘books‘ using template ‘basic‘ in module:
scrape_book.spiders.books
6、 不需要手工创建Spider文件以及Spider类,可以使用scrapy genspider<SPIDER_NAME> <DOMAIN>命令生成(根据模板)它们,该命令的两个参数分别是Spider的名字和所要爬取的域(网站)(base) D:\Workspace\ScrapyTest\scrape_book>tree /F
卷 DATA1 的文件夹 PATH 列表
卷序列号为 3A2E-EB05
D:.
│ scrapy.cfg
│
└─scrape_book
│ items.py
│ middlewares.py
│ pipelines.py
│ settings.py
│ __init__.py
│
├─spiders
│ │ books.py
│ │ __init__.py
│ │
│ └─__pycache__
│ __init__.cpython-37.pyc
│
└─__pycache__
settings.cpython-37.pyc
__init__.cpython-37.pyc
运行后,scrapy genspider命令创建了文件toscrape_book/spiders/books.py,并在其中创建了一个BooksSpider类:
# -*- coding: utf-8 -*-
import scrapy
class BooksSpider(scrapy.Spider):
name = ‘books‘
allowed_domains = [‘books.toscrape.com‘]
start_urls = [‘http://books.toscrape.com/‘]
def parse(self, response):
pass
原文:https://www.cnblogs.com/jeshy/p/11104788.html