脚本命令如果不经常使用,那么很容易忘记,所以这里记录下,经常使用到的一些脚本命令。忘记的时候,看下笔记也能够快速捡起来
sed [options] {sed-commands} {input-file}
sed 首先从 input-file 中读取第一行,然后执行所有的 sed-commands; 再读取第二行,执行所有 sed-commands,重复这个过程,直到 input-file结束。
通过制定[options] 还可以给 sed 传递一些可选的选项。
例如:
打印/etc/passwd文件下的所有记录
sed -n ‘p‘ /etc/passwd
{sed-commands} 可以是多个命令, 也可以将多个命令放在一个文件中,然后通过-f来调用。
例如:
sed -n -f sed-script /etc/passwd
sed-script代码如下:
/^root/ p /^nobody/ p
也可以使用-e来执行多个命令
例如:
sed -n -e ‘/^root/ p‘ -e ‘/^nobody/ p‘ /etc/passwd
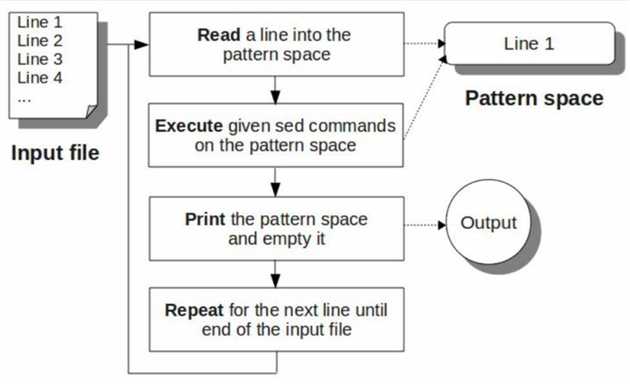
使用命令p, 可以打印模式空间的内容。
sed在执行完命令时,默认会打印模式空间的内容。所以一般使用p命令时,一般要使用-n选项,来屏蔽sed的默认输出,否则同一行会打印两次。
p命令用来控制输出你感兴趣的行。
例如:
sed -n ‘/Jane/ p‘ employee.txt // 打印匹配Jane的行 sed -n ‘1,2 p‘ employee.txt // 打印1~2行 sed -n ‘2,$ p‘ employee.txt // 打印2到最后一行 sed -n ‘2 p‘ employee.txt // 只打印第2行 sed -n ‘/Jason/, $ p‘ employee.txt // 打印匹配到Jason的行到最后一行 sed -n ‘/Jason/, /Jane/ p‘ employee.txt // 打印匹配Jason到Jane的行
m,n表示从m到n行 m~n表示从m行开始,每次跳过n行 1~2打印 1,3,5行 m,+n表示从m行开始后的n行
命令d用来删除模式空间的内容,注意:它只会删除模式空间的内容,不会删除原文件的内容
命令d和上面的p命令差不多
sed -n ‘/Jane/ d‘ employee.txt sed -n ‘1,2 d‘ employee.txt sed -n ‘2,$ d‘ employee.txt sed -n ‘2 d‘ employee.txt sed -n ‘/Jason/, $ d‘ employee.txt sed -n ‘/Jason/, /Jane/ d‘ employee.txt
删除空白行:
sed -n ‘/^$/ d‘ employee.txt
删除所有注释行:
sed ‘/^#/ d‘ employee.txt
w命令可以将模式空间的内容写到文件中
sed -n ‘2 w output.txt‘ employee.txt sed -n ‘1,4 w output.txt‘ employee.txt sed -n ‘2,$ w output.txt‘ employee.txt sed -n ‘/Jane/ w output.txt‘ employee.txt sed -n ‘/Jason/, 4 w output.txt‘ employee.txt sed -n ‘/Jason/, $ w output.txt‘ employee.txt
sed命令使用最多功能最强大的命令就是s命令。
s命令的命令格式为:
sed ‘[address-range|pattern-range] s/original-string/replacement-string/[substitute-flags]’ input file
例如:
# 将Manager替换为Director sed ‘s/Manager/Director/‘ employee.txt # 将匹配Sales的行中的Manger替换为Director sed ‘/Sales/s/Manager/Director/‘ employee.txt
sed默认情况下只会替换第一次出现的original-string, 如果要替换匹配行中出现的所有original-string, 则需要使用g.
例如:
# 只替换每行第一次出现的a为A sed ‘s/a/A/‘ employee.txt # 替换每行所有的a为A sed ‘s/a/A/g‘ employee.txt
还可以指定替换第几次出现的original-string. 例如:
# 只替换每行第二次出现的a为A sed ‘s/a/A/2‘ employee.txt
替换后打印替换了的那些行:
sed -n ‘s/John/Johnny/p‘ employee.txt sed -n ‘s/a/A/2p‘ employee.txt
sed -n ‘s/John/Johnny/w output.txt‘ employee.txt sed -n ‘s/John/Johnny/2w output.txt‘ emmployee.txt
&非常有用,它用来获取匹配到的模式。
当在 replacement-string 中使用&时,它会被替换成匹配到的 original-string 或正则表达式,这是个很有用的东西。
例如:
$ sed ‘s/^[0-9][0-9][0-9]/[&]/‘ employee.txt [101],John Doe,CEO [102],Jason Smith,IT Manager [103],Raj Reddy,Sysadmin [104],Anand Ram,Developer [105],Jane Miller,Sales Manager
将每行用双引号""包起来:
$ sed ‘s/.*/"&"/‘ employee.txt
跟在正则表达式中一样,sed 中也可以使用分组。分组以\(开始,以\)结束。分组可以用在回溯引用中。
$ sed ‘s/\([^,]*\).*/\1/g‘ employee.txt 101 102 103 104 105
正则表达式\([^,]*\)匹配字符串从开头到第一个逗号之间的所有字符(并将其放入第一个分组中)
注意:()要转义
你也可以使用多个\(和\)划分多个分组,使用多个分组时,需要在 replacement-string 中使用\n来指定第 n 个分组。
例如:
sed ‘s/\([^,]*\),\([^,]*\),\([^,]*\)/\1,\3/g‘ employee.txt 101,CEO 102,IT Manager 103,Sysadmin 104,Developer 105,Sales Manager
原文:https://www.cnblogs.com/NewMan13/p/11116165.html