1、窗口函数种类:
over():新建一个字段,指定分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变而变化。
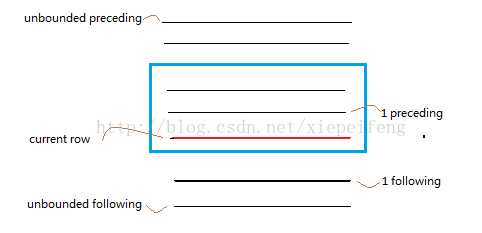
current row:当前行。
n preceding:往前n行。
n following:往后n行
unbounded:起点。
unbounded preceding:第一行
unbounded following:最后一行。
lag(col,n):取前n行的值。
lead(col,n):取后n行的值。
ntile(n):把有序分区中的行分发到指定数据的组中,各个组有编号,编号从1开始,对于每一行,ntile返回此行所属组的编号。n为int型。
ROWS是物理窗口,从行数上控制窗口的尺寸的;
RANGE是逻辑窗口,从列值上控制窗口的尺寸
last_value(sal) over(partition by deptno order by sal rows between unbounded preceding and unbounded following)
当省略窗口子句时:
a) 如果存在order by则默认的窗口是unbounded preceding and current row --当前组的第一行到当前行
b) 如果同时省略order by则默认的窗口是unbounded preceding and unbounded following --整个组
如果省略分组,则把全部记录当成一个组:
a) 如果存在order by则默认窗口是unbounded preceding and current row --当前组的第一行到当前行
b) 如果这时省略order by则窗口默认为unbounded preceding and unbounded following --整个组
2、例题
(1) 查询在2017年4月份购买过的顾客及总人数
(2) 查询顾客的购买明细及月购买总额
(3) 上述的场景,要将cost按照日期进行累加
(4) 查询顾客上次的购买时间
(5) 查询前20%时间的订单信息
表business(name,orderdate,cost)
数据:
jack,2017-01-01,10
tony,2017-01-02,15
jack,2017-02-03,23
tony,2017-01-04,29
jack,2017-01-05,46
jack,2017-04-06,42
tony,2017-01-07,50
jack,2017-01-08,55
mart,2017-04-08,62
mart,2017-04-09,68
neil,2017-05-10,12
mart,2017-04-11,75
neil,2017-06-12,80
mart,2017-04-13,94
(1)查询在2017年4月份购买过的顾客及总人数
select * ,count(*) over()
from business
where orderdate like ‘2017-04%‘;
group by name;
或者
select name,count(*) over ()
from business
where substring(orderdate,1,7) = ‘2017-04‘
group by name;
解析:先执行from语句,然后执行where语句得出2017年4月只有Jack和mart所在的行,再执行group by语句按照name分成两个组,最后count(*)统计组数即为2人。此时窗口大小为全表但是只有两条数据即两组(因为over括号里为空)
(2) 查询顾客的购买明细及月购买总额
select *,sum(cost) over(partition by month(orderdate))from business;
或者
select *,sum(cost) over(distribute by month(orderdate))from business;
解析:窗口大小为每月那个分区,然后sum(cost)处理每个窗口中的数据。
(3) 上述的场景,要将cost按照日期进行累加
select *,sum(cost) over(partition by name order by orderdate rows between unbounded preceding and current row) from business; //partition by和order by
或者
select *,sum(cost) over(distribute by name sort by orderdate rows between unbounded preceding and current row) from business; //distribute by和sort by
解析:此时以name来分组,即窗口大小为rows between unbounded preceding and current row,聚集函数sum(cost)对窗口中数据进行操作。
(4) 查询顾客上次的购买时间
select *,lag(orderdate,1) over(distribute by name sort by orderdate) from business;
解析:先按name分组,再来按orderdate排序,窗口子句lag(orderdate,1),取当前行的前面一行。
(5) 查询前20%时间的订单信息
select * from (
select name,orderdate,cost, ntile(5) over(order by orderdate) sorted
from business
) t
where sorted = 1;
解析:先排序,然后平均对排序后的数据进行标签ntile(5)取名字段为sorted,最后选取标签为1 的行。
原文:https://www.cnblogs.com/hdc520/p/11137190.html