在 MySQL 5.7.6 之前,全文索引只支持英文全文索引,不支持中文全文索引,需要利用分词器把中文段落预处理拆分成单词,然后存入数据库。
从 MySQL 5.7.6 开始,MySQL内置了ngram全文解析器,用来支持中文、日文、韩文分词。
本文使用的MySQL 版本是 5.7.24,InnoDB数据库引擎。
ngram就是一段文字里面连续的n个字的序列。
ngram全文解析器能够对文本进行分词,每个单词是连续的n个字的序列。
例如,用ngram全文解析器对“恭喜发财”进行分词:
n=1: ‘恭‘, ‘喜‘, ‘发‘, ‘财‘ n=2: ‘恭喜‘, ‘喜发‘, ‘发财‘ n=3: ‘恭喜发‘, ‘喜发财‘ n=4: ‘恭喜发财‘
MySQL 中使用全局变量 ngram_token_size 来配置 ngram 中 n 的大小,它的取值范围是1到10,默认值是 2。通常ngram_token_size设置为要查询的单词的最小字数。如果需要搜索单字,就要把ngram_token_size设置为1。在默认值是2的情况下,搜索单字是得不到任何结果的。因为中文单词最少是两个汉字,推荐使用默认值2。
全局变量 ngram_token_size 的两种设置方法:
【方式1】:使用启动命令 mysqld 时,传参如下:
mysqld --ngram_token_size=2
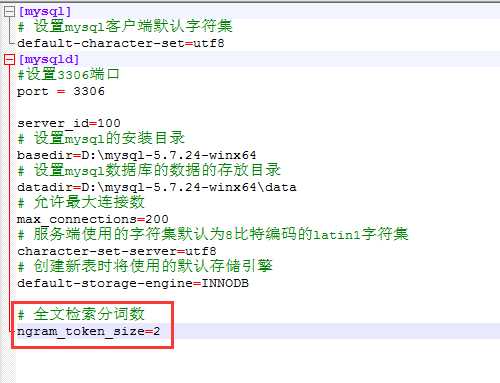
【方式2】:在修改MySQL配置文件 my.ini 中,末尾增加一行 ngram_token_size 的参数设置:
[mysql] # 设置mysql客户端默认字符集 default-character-set=utf8 [mysqld] #设置3306端口 port = 3306 server_id=100 # 设置mysql的安装目录 basedir=D:\mysql-5.7.24-winx64 # 设置mysql数据库的数据的存放目录 datadir=D:\mysql-5.7.24-winx64\data # 允许最大连接数 max_connections=200 # 服务端使用的字符集默认为8比特编码的latin1字符集 character-set-server=utf8 # 创建新表时将使用的默认存储引擎 default-storage-engine=INNODB # 全文检索分词数 ngram_token_size=2
建表语句如下:
/* Navicat Premium Data Transfer Source Server : localhost Source Server Type : MySQL Source Server Version : 50724 Source Host : localhost:3306 Source Schema : test_db Target Server Type : MySQL Target Server Version : 50724 File Encoding : 65001 Date: 07/07/2019 19:54:33 */ SET NAMES utf8mb4; SET FOREIGN_KEY_CHECKS = 0; -- ---------------------------- -- Table structure for t_article -- ---------------------------- DROP TABLE IF EXISTS `t_article`; CREATE TABLE `t_article` ( `id` int(11) NOT NULL AUTO_INCREMENT, `title` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL, `content` text CHARACTER SET utf8 COLLATE utf8_general_ci NULL, PRIMARY KEY (`id`) USING BTREE, FULLTEXT INDEX `fulltext_title_content`(`title`, `content`) WITH PARSER `ngram` ) ENGINE = InnoDB AUTO_INCREMENT = 15 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; -- ---------------------------- -- Records of t_article -- ---------------------------- INSERT INTO `t_article` VALUES (1, ‘八荣八耻 1‘, ‘以热爱祖国为荣、以危害祖国为耻‘); INSERT INTO `t_article` VALUES (2, ‘八荣八耻 2‘, ‘以服务人民为荣、以背离人民为耻‘); INSERT INTO `t_article` VALUES (3, ‘八荣八耻 3‘, ‘以崇尚科学为荣,以愚昧无知为耻‘); INSERT INTO `t_article` VALUES (4, ‘八荣八耻 4‘, ‘以辛勤劳动为荣,以好逸恶劳为耻‘); INSERT INTO `t_article` VALUES (5, ‘八荣八耻 5‘, ‘以团结互助为荣,以损人利己为耻‘); INSERT INTO `t_article` VALUES (6, ‘八荣八耻 6‘, ‘以诚实守信为荣,以见利忘义为耻‘); INSERT INTO `t_article` VALUES (7, ‘八荣八耻 7‘, ‘以遵纪守法为荣,以违法乱纪为耻‘); INSERT INTO `t_article` VALUES (8, ‘八荣八耻 8‘, ‘以艰苦奋斗为荣,以骄奢淫逸为耻‘); INSERT INTO `t_article` VALUES (9, ‘满江红‘, ‘靖康耻,尤未雪‘); INSERT INTO `t_article` VALUES (10, ‘第一生产力‘, ‘科学技术是第一 生产力‘); INSERT INTO `t_article` VALUES (11, ‘团结互助‘, ‘团结就是力量‘); INSERT INTO `t_article` VALUES (12, ‘Blue Red‘, ‘Red Black‘); INSERT INTO `t_article` VALUES (13, ‘我是奇迹 1‘, ‘你好,我是奇迹2‘); INSERT INTO `t_article` VALUES (14, ‘恭喜发财‘, ‘你好‘); SET FOREIGN_KEY_CHECKS = 1;
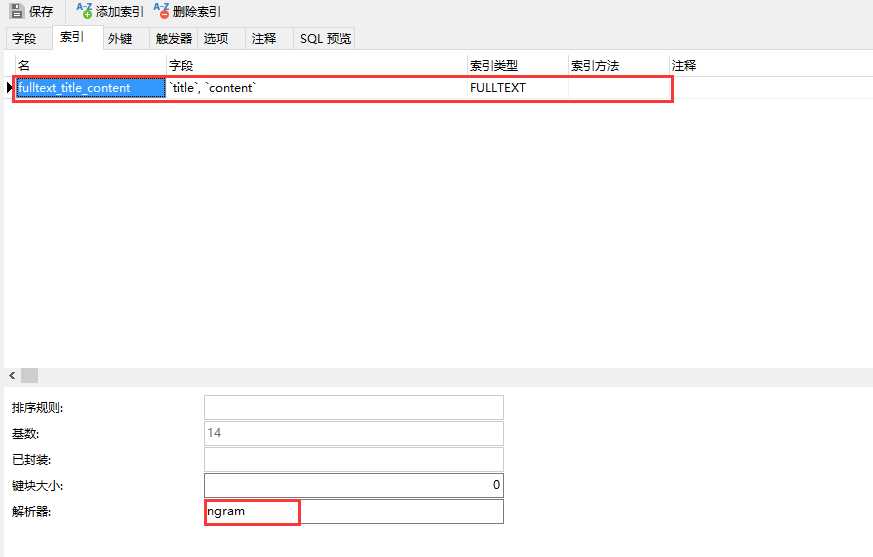
创建字段 title 和 content 的联合全文索引,语句如下:
alter table `t_article` add fulltext index fulltext_title_content(`title`,`content`) WITH PARSER ngram;
重连数据库,刷新查看索引的创建情况:
1)查询 title 或者 content 中包含“祖国”的记录,查询语句如下:
select *, MATCH (title, content) AGAINST (‘祖国‘) as score from t_article where MATCH (title, content) AGAINST (‘祖国‘ IN NATURAL LANGUAGE MODE);
查询结果如下:

2)查询 title 或者 content 中包含“团结劳动”的记录,查询语句如下:
select *, MATCH (title, content) AGAINST (‘团结劳动‘) as score from t_article where MATCH (title, content) AGAINST (‘团结劳动‘ IN NATURAL LANGUAGE MODE);
查询结果如下(查询结果,默认会按照得分 score ,从高到低排序):

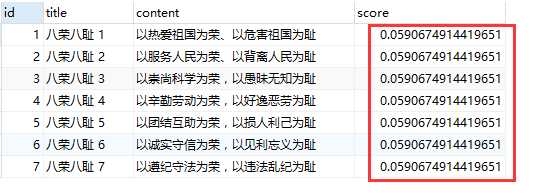
3)查询 title 或者 content 中包含“为荣”的记录,查询语句如下:
select *, MATCH (title, content) AGAINST (‘为荣‘) as score from t_article where MATCH (title, content) AGAINST (‘为荣‘ IN NATURAL LANGUAGE MODE);
查询结果如下(可以看到,此处得分是一样的):
比如,查询 title 或者 content 中包含“力”的记录,查询语句如下:
select *, MATCH (title, content) AGAINST (‘力‘) as score from t_article where MATCH (title, content) AGAINST (‘力‘ IN NATURAL LANGUAGE MODE);
查询结果如下:

从上可以看到,查不到结果。原因是设置的全局变量 ngram_token_size 的值为 2。
如果想查询单个汉字,需要在配置文件 my.ini 中修改 ngram_token_size = 1 ,并重启 mysqld 服务。

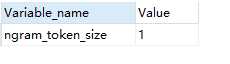
使用如下命令查询 ngram_token_size 的设置情况:
show VARIABLES like ‘ngram_token_size‘;
查询结果如下:
此时,再次执行上面的单个汉字“力”查询语句,结果如下(由于记录id = 10 中包含两个“力”,记录id = 11 中只有一个“力”。所以,查询结果中,前者得到的分数是后者的两倍):

比如,查询字段 content 中包含“诚实”,查询语句如下:
select *, MATCH (content) AGAINST (‘诚实‘) as score from t_article where MATCH (content) AGAINST (‘诚实‘ IN NATURAL LANGUAGE MODE);
查询结果报错如下:
select *, MATCH (content) AGAINST (‘诚实‘) as score from t_article where MATCH (content) AGAINST (‘诚实‘ IN NATURAL LANGUAGE MODE) > 1191 - Can‘t find FULLTEXT index matching the column list > 时间: 0.002s

原因是没有给字段 content 单独创建全文检索的索引。
给字段 content 创建全文检索索引,语句如下:
alter table `t_article` add fulltext index fulltext_content(`content`) WITH PARSER ngram;
执行结果如下:
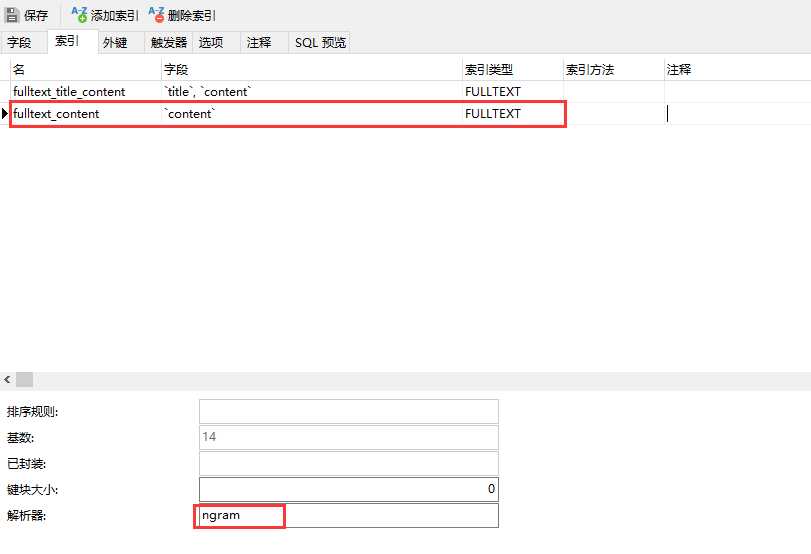
再次执行 查询字段 content 中包含“诚实”,查询结果如下:

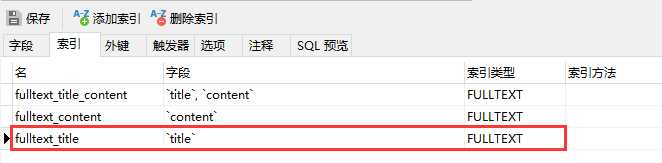
同理,如下需要单独对字段 title 进行全文检索,需要给字段 title 创建全文检索的索引,创建语句如下:
alter table `t_article` add fulltext index fulltext_title(`title`) WITH PARSER ngram;
结果如下:
常用的全文检索模式有两种:
1、自然语言模式(NATURAL LANGUAGE MODE)
自然语言模式是 MySQL 默认的全文检索模式。
自然语言模式不能使用操作符,不能指定关键词必须出现或者必须不能出现等复杂查询。
2、BOOLEAN 模式(BOOLEAN MODE)
BOOLEAN 模式可以使用操作符,可以支持指定关键词必须出现或者必须不能出现或者关键词的权重高还是低等复杂查询。
BOOLEAN 模式,举例如下:
‘apple banana‘ 无操作符,表示或,要么包含apple,要么包含banana ‘+apple +juice‘ 必须同时包含两个词 ‘+apple macintosh‘ 必须包含apple,但是如果也包含macintosh的话,相关性会更高。 ‘+apple -macintosh‘ 必须包含apple,同时不能包含macintosh。 ‘+apple ~macintosh‘ 必须包含apple,但是如果也包含macintosh的话,相关性要比不包含macintosh的记录低。 ‘+apple +(>juice <pie)‘ 查询必须包含apple和juice或者apple和pie的记录,但是apple juice的相关性要比apple pie高。 ‘apple*‘ 查询包含以apple开头的单词的记录,如apple、apples、applet。 ‘"some words"‘ 使用双引号把要搜素的词括起来,效果类似于like ‘%some words%‘, 例如“some words of wisdom”会被匹配到,而“some noise words”就不会被匹配。
举例说明:
1)查询字段 content 中包含 “团结”和“力量”的语句如下:
select *, MATCH (content) AGAINST (‘+团结 +力量‘) as score from t_article where MATCH (content) AGAINST (‘+团结 +力量‘ IN BOOLEAN MODE);
查询结果如下:

2)查询字段 content 中包含 “团结”,但不包含“力量”的语句如下:
select *, MATCH (content) AGAINST (‘+团结 -力量‘) as score from t_article where MATCH (content) AGAINST (‘+团结 -力量‘ IN BOOLEAN MODE);
查询结果如下:

3)查询字段 conent 中包含“团结”或者“力量”的语句如下:
select *, MATCH (content) AGAINST (‘团结 力量‘) as score from t_article where MATCH (content) AGAINST (‘团结 力量‘ IN BOOLEAN MODE);
查询结果如下:

1)只能在类型为 CHAR、VARCHAR 或者 TEXT 的字段上创建全文索引。
2)全文索引只支持 InnoDB 和 MyISAM 引擎。
3)MATCH (columnName) AGAINST (‘keywords‘)。MATCH()函数使用的字段名,必须要与创建全文索引时指定的字段名一致。
如上面的示例,MATCH (title,content)使用的字段名与全文索引t_article(title,conent)定义的字段名一致。
如果要对 title 或者 content 字段分别进行查询,就需要在 title 和 content 字段上分别创建新的全文索引。
4)MATCH()函数使用的字段名只能是同一个表的字段,因为全文索引不能够跨多个表进行检索。
5)如果要导入大数据集,使用先导入数据,再在表上创建全文索引的方式,要比先在表上创建全文索引再导入数据的方式快很多。
原文:https://www.cnblogs.com/miracle-luna/p/11147859.html