网络socket输入操作分为两个阶段:等待网络数据到达和将到达内核的数据复制到应用进程缓冲区。对这两个阶段不同的处理方式将网络IO分为不同的模型:IO阻塞模型、非阻塞模型、多路复用和异步IO。本文可运行代码链接:https://github.com/killianxu/network_example
阻塞模型原理如下图1.1,当进行系统调用recvfrom时,应用进程进入内核态,内核判断是否已收到数据报,若没有则阻塞直到数据报准备好,接着复制数据到应用进程缓冲区,然后函数返回。
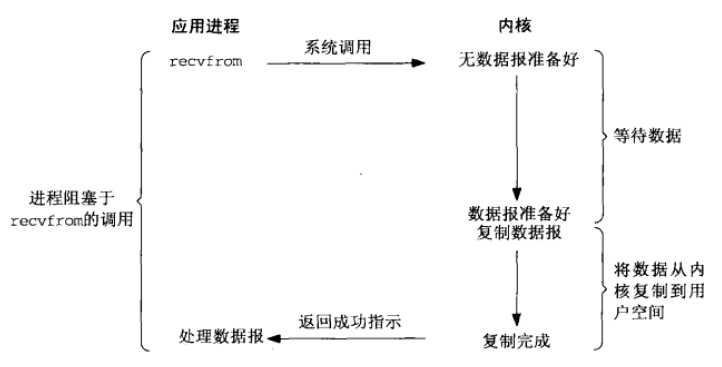
图1.1 阻塞IO模型
阻塞模型缺点:若数据报未准备好,则线程阻塞,不能进行其它操作和网络连接请求。
利用多进程多线程方案,为每个连接创建一个进程或线程,这样一个线程的阻塞不会影响到其它连接,但当遇到连接请求比较多时,会创建较多的进程或线程,严重浪费系统资源,影响进程的响应效率,进程和线程也更容易进入假死状态。
利用线程池或连接池,可以减少资源消耗。线程池利用已有线程,减少线程频繁创建和销毁,线程维持在一定数量,当有新的连接请求时,重用已有线程。连接池尽量重用已有连接,减少连接的创建和关闭。线程池和连接池一定程度上缓解频繁IO的资源消耗,但线程池和连接池都有一定规模,当连接请求数远超过池上线,池系统构成的响应并不比多线程方案好多少。[1]
阻塞模型python实例demo如下:
阻塞模型server端
def start_blocking(self): """同步阻塞server""" self.ssock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) self.ssock.bind((‘‘, 8080)) self.ssock.listen(5) count = 0 while True: conn, addr = self.ssock.accept() count += 1 print ‘Connected by‘, addr print ‘Accepted clinet count:%d‘ % count data = conn.recv(1024) #若无数据则阻塞 if data: conn.sendall(data) conn.close()
阻塞模型client
def start_blocking(self): self.host = ‘123.207.123.108‘ self.port = 8080 self.csock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) self.csock.connect((self.host, self.port)) data = self.csock.recv(1024) print data
运行server端,并运行两个client实例去连接服务端,运行结果如下图1.2,可以看到虽然有两个客户端去连接,但却只有一个连接上,服务端的socket conn为阻塞套接字,conn.recv(1024)未收到客户端发送的数据,处于阻塞状态,服务端无法再响应另一个客户端的连接。

图1.2 阻塞IO服务端运行结果
由于阻塞IO无法满足大规模请求的缺点,因此出现了非阻塞模型。非阻塞IO模型如下图1.3所示,当数据报未准备好,recvfrom立即返回一个EWOULDBLOCK错误,可以利用轮询不停调用recvfrom,当数据报准备好,内核则将数据复制到应用进程缓冲区。
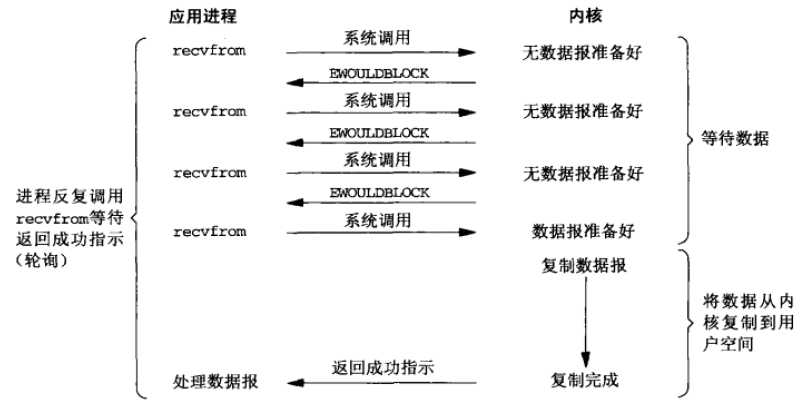
图1.3 非阻塞IO模型
非阻塞IO模型需要利用轮询不断调用recvfrom,浪费大量CPU时间,且当内核接收到数据时,需要等到下一次轮询才能复制到应用进程缓冲区,数据得不到立刻处理。
非阻塞模型python demo如下:
非阻塞服务端
def start_noblocking(self): """ 同步非阻塞 """ self.ssock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) self.ssock.bind((‘‘, 8080)) self.ssock.listen(5) count = 0 while True: conn, addr = self.ssock.accept() conn.setblocking(0) #设置为非阻塞socket count += 1 print ‘Connected by‘, addr print ‘Accepted clinet count:%d‘ % count try: data = conn.recv(1024) #非阻塞,没有数据会立刻返回 if data: conn.sendall(data) except Exception as e: pass finally: conn.close()
运行非阻塞服务端和两个客户端实例,结果如下图1.4所示,服务端接收两个连接请求。由于conn被设置为非阻塞socket,即使客户端并没有向服务端发送数据,conn.recv(1024)也会立即返回,不会阻塞,从而进程可以接收新的连接请求。

图1.4 非阻塞服务端运行结果
IO复用在linux中包括select、poll、epoll模型三种,这三个IO复用模型有各自的API实现,以select模型为例,调用select函数,进程进入阻塞, 同时监控多个套接字描述符的状态 ,当有数据报变为可读或阻塞超时才返回,接着进程可调用recvfrom接收数据报到应用进程缓冲区。
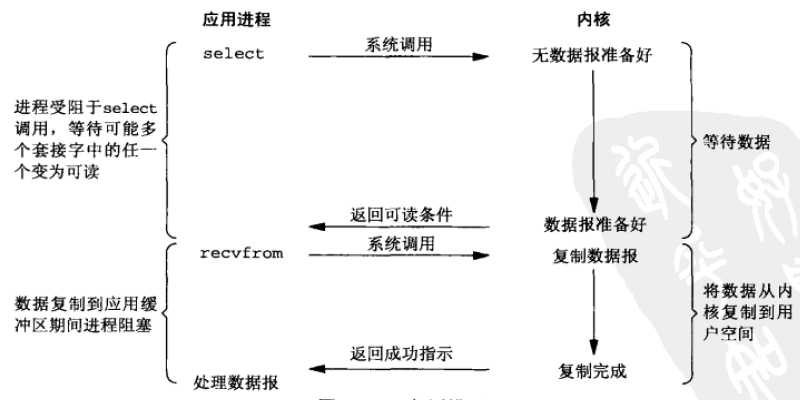
图3.1 IO复用模型
使用IO复用的优点是可以等待多个描述符就绪。[2]
select模型api如下:
int select(int maxfdp1, fd_set *readset, fd_set *writeset, fd_set *exceptset,struct timeval *timeout);
timout表示内核等待任一描述符就绪可等待的时间,有三种情况:
1) 空指针,表示可以一直等下去,直到有描述符就绪。
2) timeout时间为0,不等待检查描述符状态立即返回。
3) 时间不为0,表示等待一定时间,在有描述符准备好但不超过timeval结构所指定的秒数和微秒数。
readset、writeset、exceptset指定需要内核测试读、写和异常条件的描述符。fd_set表示描述符集,在select中用整数数组表示,整数的每一位表示一个描述符, readset、writeset、exceptset这三个参数是值-结果类型。
可以用以下几个宏设置和测试fd_set。在调用select函数前,用1、2、3设置需要监控的描述符,循环调用4测试调用select函数后的描述符,看是否准备好。
1) int FD_ZERO(int fd, fd_set *fdset);
2) int FD_CLR(int fd, fd_set *fdset);
3) int FD_SET(int fd, fd_set *fd_set);
4) int FD_ISSET(int fd, fd_set *fdset);
导致select返回某个套接字就绪的条件如下:
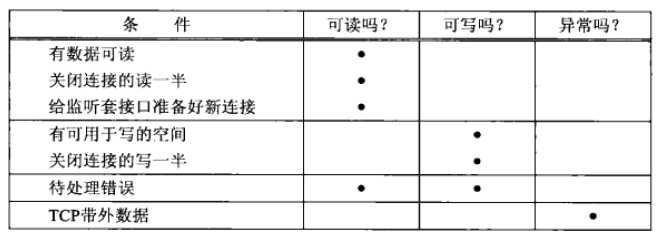
图3.2 就绪条件
maxfd1表示指定待测试描述符个数,值为待测试描述符最大值加1,用这个参数可告诉内核最大只遍历到maxfd1-1的描述符。maxfd1最大不能超过常量FD_SETSIZE(值默认为1024,更改该值需重新编译内核)。
select函数的返回值为整数,表示跨所有描述符集已就绪的总位数。如果超时则返回0。返回-1表示出错,比如被中断[3]。
select实现原理:从用户空间拷贝fd_set到内核空间,遍历所有fd,将当前进程挂到各个设备的等待队列中,挂到队列的同时会返回是否就绪的掩码,当所有fd返回的掩码均未就绪,则当前进程睡眠。当fd对应设备驱动发现可读写时,则会唤醒处于睡眠态的进程。如果超过一定时间还未唤醒, 则调用select的进程会重新被唤醒获得CPU,进而重新遍历fd,判断有没有就绪的fd,将fd_set从内核空间拷到用户空间[4]。
select实现的缺点:
1) 每次都需要将fd_set拷贝到内核空间,当fd_set较大时开销很大
2) 每次都需要在内核中遍历fd加入到等待队列,fd较多开销较大
3) Select支持的文件描述符太小,默认为1024。
select模型python demo如下:
select模型服务端
def start(self): # create a socket server = socket.socket(socket.AF_INET, socket.SOCK_STREAM) server.setblocking(False) # set option reused server.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) server_address = (‘‘, 8080) server.bind(server_address) server.listen(10) # sockets from which we except to read inputs = [server] # sockets from which we expect to write outputs = [] # Outgoing message queues (socket:Queue) message_queues = {} # A optional parameter for select is TIMEOUT timeout = 20 while inputs: print "waiting for next event" # 每次调用select函数,需要将所有socket重新传一次 readable, writable, exceptional = select.select( inputs, outputs, inputs, timeout) # When timeout reached , select return three empty lists if not (readable or writable or exceptional): print "Time out ! " break for s in readable: if s is server: # 监听套接字 # A "readable" socket is ready to accept a connection connection, client_address = s.accept() print " connection from ", client_address connection.setblocking(0) inputs.append(connection) message_queues[connection] = Queue.Queue() else: data = s.recv(1024) # 接收到数据 if data: print " received ", data, "from ", s.getpeername() message_queues[s].put(data) # Add output channel for response if s not in outputs: outputs.append(s) else: # 读这端的连接关闭 # Interpret empty result as closed connection print " closing", client_address if s in outputs: outputs.remove(s) inputs.remove(s) s.close() # remove message queue del message_queues[s] for s in writable: try: next_msg = message_queues[s].get_nowait() except Queue.Empty: print " ", s.getpeername(), ‘queue empty‘ outputs.remove(s) else: print " sending ", next_msg, " to ", s.getpeername() s.send(next_msg) for s in exceptional: print " exception condition on ", s.getpeername() # stop listening for input on the connection inputs.remove(s) if s in outputs: outputs.remove(s) s.close() # Remove message queue del message_queues[s]
select模型客户端
def start(self): messages = ["hello world"] print "Connect to the server" server_address = ("123.207.123.108",8080) #Create a TCP/IP sock socks = [] for i in range(3): socks.append(socket.socket(socket.AF_INET,socket.SOCK_STREAM)) for s in socks: s.connect(server_address) counter = 0 for message in messages : #Sending message from different sockets for s in socks: counter+=1 print " %s sending %s" % (s.getpeername(),message+" version "+str(counter)) s.send(message+" version "+str(counter)) #Read responses on both sockets for s in socks: data = s.recv(1024) print " %s received %s" % (s.getpeername(),data) if not data: print "%s closing socket "%s.getpeername() s.close()
分别运行服务端和客户端,结果如下:
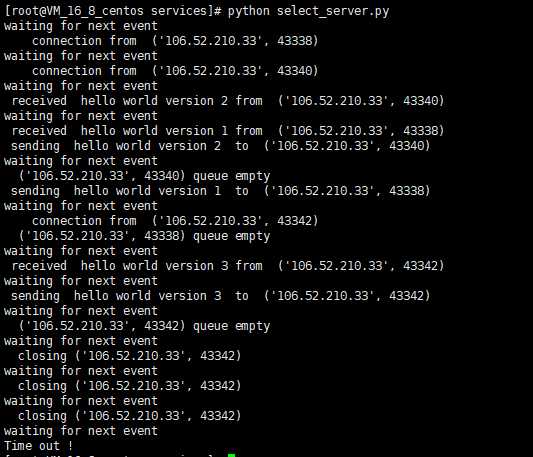
图3.3 select模型服务端运行结果
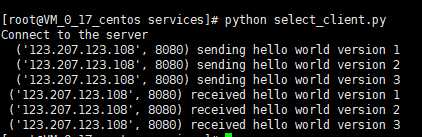
图3.4 select模型客户端运行结果
poll模型api如下[8]:
#include <poll.h> int poll(struct pollfd fds[], nfds_t nfds, int timeout); typedef struct pollfd { int fd; // 需要被检测或选择的文件描述符 short events; // 对文件描述符fd上感兴趣的事件 short revents; // 文件描述符fd上当前实际发生的事件*/ } pollfd_t;
1) poll()函数返回fds集合中就绪的读、写,或出错的描述符数量,返回0表示超时,返回-1表示出错;
2) fds是一个struct pollfd类型的数组,用于存放需要检测其状态的socket描述符,并且调用poll函数之后fds数组不会被清空;
3) nfds记录数组fds中描述符的总数量;
4) timeout是调用poll函数阻塞的超时时间,单位毫秒;
5) 一个pollfd结构体表示一个被监视的文件描述符,通过传递fds[]指示 poll() 监视多个文件描述符。其中,结构体的events域是监视该文件描述符的事件掩码,由用户来设置这个域,结构体的revents域是文件描述符的操作结果事件掩码,内核在调用返回时设置这个域。events域中请求的任何事件都可能在revents域中返回。
合法的事件如下:
1) POLLIN 有数据可读
2) POLLRDNORM 有普通数据可读
3) POLLRDBAND 有优先数据可读
4) POLLPRI 有紧迫数据可读
5) POLLOUT 写数据不会导致阻塞
6) POLLWRNORM 写普通数据不会导致阻塞
7) POLLWRBAND 写优先数据不会导致阻塞
8) POLLERR 发生错误
9) POLLHUP 发生挂起
当需要监听多个事件时,使用POLLIN | POLLPRI设置 events 域;当poll调用之后检测某事件是否发生时,fds[i].revents & POLLIN进行判断
poll模型和select模型相似,poll模型同样需要将所有监控的描述符重新拷贝到内核,并在内核中对所有描述符进行遍历,没有解决select模型的性能问题,但是poll模型没有最大文件描述符数量的限制。
select()和poll()将就绪的文件描述符告诉进程后,如果进程没有对其进行IO操作,那么下次调用select()和poll()的时候将再次报告这些文件描述符,所以它们一般不会丢失就绪的消息,这种方式称为水平触发[5]。
poll模型python demo如下:
def start(self)://poll模型服务端 # Create a TCP/IP socket, and then bind and listen server = socket.socket(socket.AF_INET, socket.SOCK_STREAM) server.setblocking(False) server_address = (‘‘, 8080) print "Starting up on %s port %s" % server_address server.bind(server_address) server.listen(5) message_queues = {} # The timeout value is represented in milliseconds, instead of seconds. timeout = 5000 # Create a limit for the event,POLLIN = POLLRDNORM | POLLRDBAND READ_ONLY = (select.POLLIN | select.POLLPRI) READ_WRITE = (READ_ONLY | select.POLLOUT) #POLLOUT=POLLWRNORM | POLLWRBAND # Set up the poller poller = select.poll() poller.register(server, READ_ONLY) # Map file descriptors to socket objects fd_to_socket = {server.fileno(): server, } while True: print "Waiting for the next event" events = poller.poll(timeout) if len(events) == 0: print ‘Time out‘ break print "*" * 20 print len(events) print events print "*" * 20 for fd, flag in events: s = fd_to_socket[fd] if flag & (select.POLLIN | select.POLLPRI): if s is server: # A readable socket is ready to accept a connection connection, client_address = s.accept() print " Connection ", client_address connection.setblocking(False) fd_to_socket[connection.fileno()] = connection poller.register(connection, READ_ONLY) # Give the connection a queue to send data message_queues[connection] = Queue.Queue() else: data = s.recv(1024) if data: # A readable client socket has data print " received %s from %s " % (data, s.getpeername()) message_queues[s].put(data) poller.modify(s, READ_WRITE) else: # Close the connection print " closing", s.getpeername() # Stop listening for input on the connection poller.unregister(s) s.close() del message_queues[s] elif flag & select.POLLHUP: # A client that "hang up" , to be closed. print " Closing ", s.getpeername(), "(HUP)" poller.unregister(s) s.close() elif flag & select.POLLOUT: # Socket is ready to send data , if there is any to send try: next_msg = message_queues[s].get_nowait() except Queue.Empty: # No messages waiting so stop checking print s.getpeername(), " queue empty" poller.modify(s, READ_ONLY) else: print " sending %s to %s" % (next_msg, s.getpeername()) s.send(next_msg) elif flag & select.POLLERR: # Any events with POLLERR cause the server to close the # socket print " exception on", s.getpeername() poller.unregister(s) s.close() del message_queues[s]
epoll模型api包含三个系统调用[7]:
#include <sys/epoll.h> int epoll_create(int size); int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event); int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
1. epoll_create创建epoll句柄epfd。size表示在这个epoll fd上能关注的最大fd数,失败时返回-1。
2. epoll_ctl注册要监听的事件。
1) epfd表示epoll句柄;
2) op表示fd操作类型:EPOLL_CTL_ADD(注册新的fd到epfd中),EPOLL_CTL_MOD(修改已注册的fd的监听事件),EPOLL_CTL_DEL(从epfd中删除一个fd)
3) fd是要监听的描述符;
4) event表示要监听的事件; EPOLLIN表示对应的文件描述符可以读(包括对端SOCKET正常关闭);EPOLLOUT表示对应的文件描述符可以写;EPOLLPRI表示对应的文件描述符有紧急的数据可读(这里应该表示有带外数据到来);EPOLLERR表示对应的文件描述符发生错误;EPOLLHUP表示对应的文件描述符被挂断;EPOLLET将EPOLL设为边缘触发(Edge Triggered)模式,这是相对于水平触发(Level Triggered)来说的。EPOLLONESHOT只监听一次事件,当监听完这次事件之后,如果还需要继续监听这个socket的话,需要再次把这个socket加入到EPOLL队列里[8]。
3. epoll_wait函数等待事件就绪,成功时返回就绪的事件数目,调用失败时返回 -1,等待超时返回 0。
1) epfd是epoll句柄
2) events表示从内核得到的就绪事件集合
3) maxevents告诉内核events的大小
4) timeout表示等待的超时事件
epoll_event结构体定义如下:
struct epoll_event { __uint32_t events; /* Epoll events */ epoll_data_t data; /* User data variable */ }; typedef union epoll_data { void *ptr; int fd; __uint32_t u32; __uint64_t u64; } epoll_data_t;
epoll模型利用三个函数代替select和poll模型的三个函数,可以避免select模型的三个缺点。
1) 不需要每次都将相同的fd监听事件重新拷贝到内核。epoll的解决方案在epoll_ctl函数中。每次注册新的事件到epoll句柄中时(在epoll_ctl中指定EPOLL_CTL_ADD),会把所有的fd拷贝进内核,而不是在epoll_wait的时候重复拷贝。epoll保证了每个fd在整个过程中只会拷贝一次。
2) 不需要再内核中遍历所有fd来看事件是否就绪。epoll的解决方案不像select或poll一样每次都把current进程轮流加入fd对应的设备等待队列中,而只在epoll_ctl时把current进程挂一遍(这一遍必不可少)并为每个fd指定一个回调函数,当设备就绪,唤醒等待队列上的等待者时,就会调用这个回调函数,而这个回调函数会把就绪的fd加入一个就绪链表)。epoll_wait的工作实际上就是在这个就绪链表中查看有没有就绪的fd。
3) 所监听的文件描述符的数目不像select有上限限制, 所支持的FD上限是最大可以打开文件的数目。
epoll对文件描述符的操作有两种模式:LT(level trigger,水平触发)和ET(edge trigger)。
1) 水平触发:默认工作模式,即当epoll_wait检测到某描述符事件就绪并通知应用程序时,应用程序可以不立即处理该事件;下次调用epoll_wait时,会再次通知此事件。
2) 边缘触发:当epoll_wait检测到某描述符事件就绪并通知应用程序时,应用程序必须立即处理该事件。如果不处理,下次调用epoll_wait时,不会再次通知此事件。(直到你做了某些操作导致该描述符变成未就绪状态了,也就是说边缘触发只在状态由未就绪变为就绪时通知一次)。
ET模式很大程度上减少了epoll事件的触发次数,因此效率比LT模式高。
epoll模型python demo如下:
def start(self): # Create a TCP/IP socket, and then bind and listen server = socket.socket(socket.AF_INET, socket.SOCK_STREAM) server.setblocking(False) server_address = (‘‘, 8080) print "Starting up on %s port %s" % server_address server.bind(server_address) server.listen(5) message_queues = {} # The timeout value is represented in milliseconds, instead of seconds. timeout = 5000 # Create a limit for the event READ_ONLY = (select.EPOLLIN) READ_WRITE = (READ_ONLY | select.EPOLLOUT) # Set up the epoll epoll = select.epoll() epoll.register(server.fileno(), READ_ONLY) # Map file descriptors to socket objects fd_to_socket = {server.fileno(): server, } while True: print "Waiting for the next event" events = epoll.poll(timeout) if len(events) == 0: print ‘Time out‘ break print "*" * 20 print len(events) print events print "*" * 20 for fd, flag in events: s = fd_to_socket[fd] if flag & (select.EPOLLIN): if s is server: # A readable socket is ready to accept a connection connection, client_address = s.accept() print " Connection ", client_address connection.setblocking(False) fd_to_socket[connection.fileno()] = connection epoll.register(connection, READ_ONLY) # Give the connection a queue to send data message_queues[connection] = Queue.Queue() else: data = s.recv(1024) if data: # A readable client socket has data print " received %s from %s " % (data, s.getpeername()) message_queues[s].put(data) epoll.modify(s, READ_WRITE) else: # Close the connection print " closing", s.getpeername() # Stop listening for input on the connection epoll.unregister(s) s.close() del message_queues[s] elif flag & select.EPOLLHUP: # A client that "hang up" , to be closed. print " Closing ", s.getpeername(), "(HUP)" epoll.unregister(s) s.close() elif flag & select.EPOLLOUT: # Socket is ready to send data , if there is any to send try: next_msg = message_queues[s].get_nowait() except Queue.Empty: # No messages waiting so stop checking print s.getpeername(), " queue empty" epoll.modify(s, READ_ONLY) else: print " sending %s to %s" % (next_msg, s.getpeername()) s.send(next_msg) elif flag & select.epollERR: # Any events with epollR cause the server to close the # socket print " exception on", s.getpeername() epoll.unregister(s) s.close() del message_queues[s]
没有IO复用之前,用阻塞型IO,必须为每个建立的连接创建线程或线程,当面对大量连接时, 严重浪费系统资源,影响进程的响应效率,用非阻塞IO,需要轮询测试socket集合是否已经读写就绪,在已经就绪和测试到就绪有一定的时延,数据得不到及时处理。利用IO复用, 同时可监控多个套接字描述符的状态,而不用像阻塞型IO,每个套接字需要一个线程或进程处理,也不像非阻塞IO,存在处理时延,IO复用函数是阻塞函数,不用轮询测试,有socket就绪或超时才会返回。
IO复用分为select、poll、epoll模型三种,select模型存在如下三个缺点:
1) 每次都需要将fd_set拷贝到内核空间,当fd_set较大时开销很大
2) 每次都需要在内核中遍历fd加入到等待队列,fd较多开销较大
3) select支持的文件描述符太小,默认为1024
poll模型不存在同时监听的描述符大小限制,但是仍然存在缺点1和2。epoll模型克服了这三个缺点,epoll模型对于加入监听的socket描述符,会将描述符和监听的事件记在内核,无需像select和poll每次都需要将文件描述符集拷贝到内核。在判断是否有读写就绪时。当有读写事件就绪时,内核会调用函数将就绪的fd加入就绪链表,因此epoll模型只需读就绪链表,而不需要将所有fd遍历一遍,性能会比select和poll模型高。
信号驱动式IO模型原理如下图4.1:
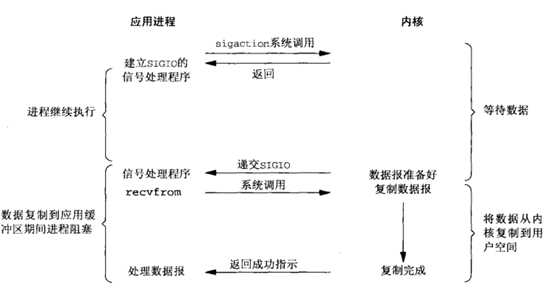
图4.1 信号驱动IO
Signal Driven I/O 的工作原理就是用户进程首先和 kernel 之间建立信号的通知机制,即用户进程告诉 kernel,如果 kernel 中数据准备好了,就通过 SIGIO 信号通知进程。然后用户空间的进程就会调用 read 系统调用将准备好的数据从 kernel 拷贝到用户空间。
但是这种 I/O 模型存在一个非常重大的缺陷问题:SIGIO 这种信号对于每个进程来说只有一个!如果使该信号对进程中的两个描述符(这两个文件描述符都等待着 I/O 操作)都起作用,那么进程在接到此信号后就无法判别是哪一个文件描述符准备好了。所以 Signal Driven I/O 模型在现实中用的非常少。
异步IO模型原理如下图:
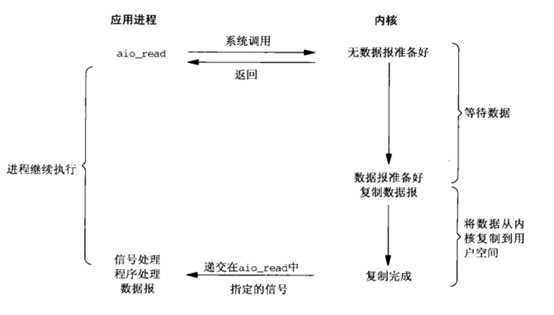
图4.2 异步IO
在异步IO中,用户进程调用aio_read立即返回,直到内核将数据拷贝到进程缓冲区,然后通知进程完成,整个过程完全没阻塞,连recvfrom都不用用户进程调用。其它的IO模型都属于同步IO。
在异步非阻塞 I/O 中,可以同时发起多个传输操作。这需要每个传输操作都有惟一的上下文,这样才能在它们完成时区分到底是哪个传输操作完成了。在 AIO 中,这是一个 aiocb(AIO I/O Control Block)结构。这个结构包含了有关传输的所有信息,包括为数据准备的用户缓冲区。在产生 I/O (称为完成)通知时,aiocb 结构就被用来惟一标识所完成的 I/O 操作。这个 API 的展示显示了如何使用它[10]。
aiocb结构如下:
struct aiocb { int aio_fildes; // File Descriptor int aio_lio_opcode; // Valid only for lio_listio (r/w/nop) volatile void *aio_buf; // Data Buffer size_t aio_nbytes; // Number of Bytes in Data Buffer struct sigevent aio_sigevent; // Notification Structure /* Internal fields */ ... };
sigevent 结构告诉 AIO 在 I/O 操作完成时应该执行什么操作。Aio api如下:
1) int aio_read( struct aiocb *aiocbp ) 请求异步读操作
2) aio_error 检查异步请求的状态
3) aio_return 获得完成的异步请求的返回状态
4) aio_write 请求异步写操作
5) aio_suspend 挂起调用进程,直到一个或多个异步请求已经完成(或失败)
6) aio_cancel 取消异步 I/O 请求
7) lio_listio 发起一系列 I/O 操作
为了便于理解,这里使用c语言,使用 aio_read 进行异步读操作c实例如下:
//使用aio api读实例
#include <aio.h> ... int fd, ret; struct aiocb my_aiocb; fd = open( "file.txt", O_RDONLY ); if (fd < 0) perror("open"); /* Zero out the aiocb structure (recommended) */ bzero( (char *)&my_aiocb, sizeof(struct aiocb) ); /* Allocate a data buffer for the aiocb request */ my_aiocb.aio_buf = malloc(BUFSIZE+1);// 清空了 aiocb 结构,分配一个数据缓冲区 if (!my_aiocb.aio_buf) perror("malloc"); /* Initialize the necessary fields in the aiocb */ my_aiocb.aio_fildes = fd; //文件描述符 my_aiocb.aio_nbytes = BUFSIZE;//缓冲区大小 my_aiocb.aio_offset = 0;// // 将 aio_offset 设置成 0(该文件中的第一个偏移量) ret = aio_read( &my_aiocb );//发起异步读请求 if (ret < 0) perror("aio_read"); while ( aio_error( &my_aiocb ) == EINPROGRESS ) ;//检查异步请求是否完成 if ((ret = aio_return( &my_iocb )) > 0) {//所传输的字节数,如果发生错误,返回值就为 -1 /* got ret bytes on the read */ } else { /* read failed, consult errno */ }
当异步请求完成时,内核有两种方式通知进程,一种是通过信号,另一种是调用回调函数。
使用信号作为AIO通知demo如下,应用程序对指定信号注册信号处理函数, 在产生指定的信号时就会调用这个处理程序。并指定AIO操作完成时,由内核发出指定信号,将aiocb作为信号的上下文,用来分辨多个IO请求。
AIO完成通知-信号 void setup_io( ... ) { int fd; struct sigaction sig_act; struct aiocb my_aiocb; ... /* Set up the signal handler */ sigemptyset(&sig_act.sa_mask); sig_act.sa_flags = SA_SIGINFO; sig_act.sa_sigaction = aio_completion_handler; /* Set up the AIO request */ bzero( (char *)&my_aiocb, sizeof(struct aiocb) ); my_aiocb.aio_fildes = fd; my_aiocb.aio_buf = malloc(BUF_SIZE+1); my_aiocb.aio_nbytes = BUF_SIZE; my_aiocb.aio_offset = next_offset; /* Link the AIO request with the Signal Handler */ my_aiocb.aio_sigevent.sigev_notify = SIGEV_SIGNAL;//指定信号作为通知方法 my_aiocb.aio_sigevent.sigev_signo = SIGIO; my_aiocb.aio_sigevent.sigev_value.sival_ptr = &my_aiocb; /* Map the Signal to the Signal Handler */ ret = sigaction( SIGIO, &sig_act, NULL ); ... ret = aio_read( &my_aiocb ); } void aio_completion_handler( int signo, siginfo_t *info, void *context ) { struct aiocb *req; /* Ensure it‘s our signal */ if (info->si_signo == SIGIO) { req = (struct aiocb *)info->si_value.sival_ptr; /* Did the request complete? */ if (aio_error( req ) == 0) { /* Request completed successfully, get the return status */ ret = aio_return( req ); } } return; }
使用回调函数作为异步请求通知demo如下, 这种机制不会为通知而产生一个信号,而是会调用用户空间的一个函数来实现通知功能.
//AIO完成通知-回调函数 void setup_io( ... ) { int fd; struct aiocb my_aiocb; ... /* Set up the AIO request */ bzero( (char *)&my_aiocb, sizeof(struct aiocb) ); my_aiocb.aio_fildes = fd; my_aiocb.aio_buf = malloc(BUF_SIZE+1); my_aiocb.aio_nbytes = BUF_SIZE; my_aiocb.aio_offset = next_offset; /* Link the AIO request with a thread callback */ my_aiocb.aio_sigevent.sigev_notify = SIGEV_THREAD;// SIGEV_THREAD 指定线程回调函数来作为通知方法 my_aiocb.aio_sigevent.notify_function = aio_completion_handler; my_aiocb.aio_sigevent.notify_attributes = NULL; my_aiocb.aio_sigevent.sigev_value.sival_ptr = &my_aiocb; ... ret = aio_read( &my_aiocb ); } void aio_completion_handler( sigval_t sigval ) { struct aiocb *req; req = (struct aiocb *)sigval.sival_ptr; /* Did the request complete? */ if (aio_error( req ) == 0) { /* Request completed successfully, get the return status */ ret = aio_return( req ); } return; }
网络IO模型包括阻塞、非阻塞、IO复用、信号驱动IO和异步IO五种类型。阻塞IO无法应对多个连接的情形,单个socket操作阻塞会导致服务端无法接受其他连接,虽然可以用多线程、多进程的方式,将不同的连接放在不同的线程中和客户端交互,并利用线程池和连接池进行优化。但创建进程和线程会占用系统资源,当面对大规模连接时,系统资源浪费严重,系统响应效率不高。
非阻塞模型当socket读写操作未就绪时会立即返回,而不会阻塞等待,可以利用轮询的方式来进行读写操作,但当内核收到数据报到应用进程感知并处理会有时延。
利用IO复用,将监控socket读写操作是否就绪和进行读写操作分开,且IO复用可监控socket集合,IO复用包含select、poll、epoll三种模型。
select模型存在如下三种缺点:
1) 每次都需要将fd_set拷贝到内核空间,当fd_set较大时开销很大
2) 每次都需要在内核中遍历fd加入到等待队列,fd较多开销较大
3) select支持的文件描述符太小,默认为1024。
poll模型可同时监控的socket没有上线限制,取决于系统资源,但poll模型不能避免缺点1和2。epoll模型可以避免select和poll模型的缺点。select,poll每次调用都要把fd集合从用户态往内核态拷贝一次,并且要把current进程往设备等待队列中挂一次,而epoll只要一次拷贝,而且把current进程往等待队列上挂也只挂一次。这也能节省不少的开销。select,poll内部实现需要自己不断轮询所有fd集合,直到设备就绪,期间可能要睡眠和唤醒多次交替。而epoll其实也需要调用epoll_wait不断轮询就绪链表,期间也可能多次睡眠和唤醒交替,但是它是设备就绪时,调用回调函数,把就绪fd放入就绪链表中,并唤醒在epoll_wait中进入睡眠的进程。虽然都要睡眠和交替,但是select和poll在“醒着”的时候要遍历整个fd集合,而epoll在“醒着”的时候只要判断一下就绪链表是否为空就行了,这节省了大量的CPU时间。这就是回调机制带来的性能提升。
信号驱动式IO,当内核数据准备好时,发出信号,调用进程提前注册好的信号处理函数,但当存在多个socket操作时,无法分清是哪个socket准备好,因此实际应用中较少。
无论是阻塞IO、非阻塞IO、IO复用还是信号驱动IO模型,都是同步IO模型。其要么是监控socket就绪,要么是从内核拷贝数据到进程缓冲区,至少其中一个是阻塞的,不会立即返回。异步IO模型发起读写操作后,立即返回,可以接着进行其它操作,内核完成将数据拷贝到应用进程后,通过信号或者回调函数通知进程。
[1]. 阻塞IO(blocking IO). https://www.chenxie.net/archives/1956.html
[2]. Unix网络编程卷1.124~125.
[3]. linux select函数详解. https://blog.csdn.net/lingfengtengfei/article/details/12392449
[4]. select,poll,epoll实现分析—结合内核源代码. https://www.linuxidc.com/Linux/2012-05/59873.htm
[5]. Python网络编程中的select 和 poll I/O复用的简单使用. https://www.cnblogs.com/coser/archive/2012/01/06/2315216.html
[6]. socket选项总结(setsocketopt). https://blog.csdn.net/c1520006273/article/details/50420408
[7]. Linux下I/O多路复用系统调用(select, poll, epoll)介绍. https://zhuanlan.zhihu.com/p/22834126
[8]. IO多路复用:select、poll、epoll示例. https://blog.csdn.net/lisonglisonglisong/article/details/51328062
[9]. Linux I/O 模型. https://woshijpf.github.io/linux/2017/07/10/Linux-IO%E6%A8%A1%E5%9E%8B.html.
[10]. 使用异步 I/O 大大提高应用程序的性能. https://www.ibm.com/developerworks/cn/linux/l-async/
原文:https://www.cnblogs.com/killianxu/p/11148522.html