Momentum 从平地到了下坡的地方,加速了他的行走
AdaGrad 让每一个参数都有学习率,相当给人穿了一双鞋子
RMSProp 是两者的结合
----
import torch
import torch.nn.functional as F
import torch.utils.data as Data
from torch.autograd import Variable
import matplotlib.pyplot as plt### 定义神经网络
class Net(torch.nn.Module):
def __init__(self):
super(Net,self).__init__()
self.hidden = torch.nn.Linear(1,20) # hidden layer
self.predict = torch.nn.Linear(20,1) # output layer
def forward(self,x):
x = F.relu(self.hidden(x))
x = self.predict(x)
return x# hyper parameters 超参数
LR = 0.01
BATCH_SIZE = 32
EPOCH = 12
x = torch.unsqueeze(torch.linspace(-1,1,1000),dim=1)
y = x.pow(2) + 0.1*torch.normal(torch.zeros(x.size()))
#plot dataset
# plt.scatter(x.numpy() , y.numpy())
# plt.show()
torch_dataset = Data.TensorDataset(x,y)
loader = Data.DataLoader(dataset=torch_dataset,batch_size=BATCH_SIZE,shuffle=True)# different nets
net_SGD = Net()
net_Momentum = Net()
net_RMSprop = Net()
net_Adam = Net()
nets = [net_SGD ,net_Momentum,net_RMSprop,net_Adam]
opt_SGD = torch.optim.SGD(net_SGD.parameters(),lr=LR)
opt_Momentum = torch.optim.SGD(net_Momentum.parameters(),lr=LR,momentum=0.8)
opt_RMSprop = torch.optim.RMSprop(net_RMSprop.parameters(),lr=LR,alpha=0.9)
opt_Adam = torch.optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.9, 0.99))
optimizers = [opt_SGD, opt_Momentum, opt_RMSprop, opt_Adam]# 记录误差
loss_func = torch.nn.MSELoss()
losses_his = [[], [], [], []] # record loss # training
plt.figure(figsize=(10,10))
for epoch in range(EPOCH):
print('Epoch: ', epoch)
for step, (b_x, b_y) in enumerate(loader): # for each training step
for net, opt, l_his in zip(nets, optimizers, losses_his):
output = net(b_x) # get output for every net
loss = loss_func(output, b_y) # compute loss for every net
opt.zero_grad() # clear gradients for next train
loss.backward() # backpropagation, compute gradients
opt.step() # apply gradients
l_his.append(loss.data.numpy()) # loss recoder
labels = ['SGD', 'Momentum', 'RMSprop', 'Adam']
for i, l_his in enumerate(losses_his):
plt.plot(l_his, label=labels[i])
plt.legend(loc='best')
plt.xlabel('Steps')
plt.ylabel('Loss')
plt.ylim((0, 0.2))
plt.show()Epoch: 0
Epoch: 1
Epoch: 2
Epoch: 3
Epoch: 4
Epoch: 5
Epoch: 6
Epoch: 7
Epoch: 8
Epoch: 9
Epoch: 10
Epoch: 11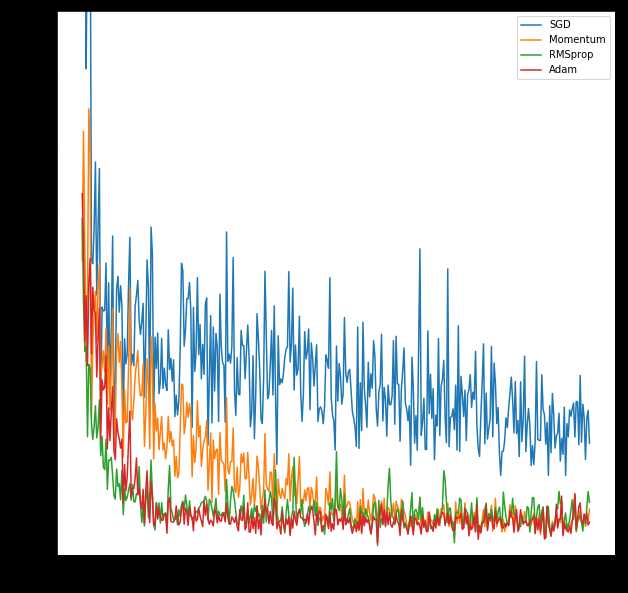
原文:https://www.cnblogs.com/liu247/p/11152923.html