1、没有多任务的程序
import time def sing(): for i in range(5): print("啊啊啊啊~~%d" % i) time.sleep(1) def dance(): for i in range(5): print("当当当当~~%d" % i) time.sleep(1) def main(): sing() dance() if __name__ == "__main__": main()
并发:指的是任务数多于cpu核数,通过操作系统的各种任务调度算法,实现用多个任务“一起”执行(实际上总有一些任务不在执行,因为切换任务的速度相当快,看上去一起执行而已)
并行:指的是任务数小于等于cpu核数,即任务真的是一起执行的
2、线程
python的thread模块是比较底层的模块,python的threading模块是对thread做了一些包装的,可以更加方便的被使用
import time import threading def sing(): for i in range(5): print("啊啊啊啊~~%d" % i) time.sleep(1) def dance(): for i in range(5): print("当当当当~~%d" % i) time.sleep(1) def main(): t1 = threading.Thread(target=sing) t2 = threading.Thread(target=dance) t1.start() t2.start() if __name__ == "__main__": main()
使用了多线程并发的操作,花费时间要短很多
当调用start()时,才会真正的创建线程,并且开始执行
主线程会等待所有的子线程结束后才结束
线程执行顺序是不确定的,可以通过延时的方式保证顺序执行
import threading import time def sing(): for i in range(4): print("啊啊啊啊~~%s" % i) time.sleep(1) def dance(): for i in range(8): print("当当当当~~%s" % i) time.sleep(1) def main(): t1 = threading.Thread(target=sing) t2 = threading.Thread(target=dance) t1.start() t2.start() while True: time.sleep(1) # 每秒查看一次正在运行的线程 print(threading.enumerate()) if __name__ == ‘__main__‘: main()
if len(threading.enumerate()) <= 1: break
3、通过继承Thread类来完成创建线程
import threading import time class MyThread(threading.Thread): def run(self): # 必须有run方法 for i in range(5): time.sleep(1) msg = "i‘m " + self.name + " @" + str(i) # name表示当前线程的名字,str()把i转成string类型才能拼接 print(msg) def main(): t = MyThread() t.start() if __name__ == ‘__main__‘: main()
4、多线程共享全局变量
所有子线程和主线程共享全局变量
import threading import time g_num = 100 def test1(): global g_num g_num += 1 print("----in test1 g_num = %d ----" % g_num) def test2(): print("----in test2 g_num = %d ----" % g_num) def main(): t1 = threading.Thread(target=test1) t2 = threading.Thread(target=test2) t1.start() time.sleep(1) t2.start() time.sleep(1) print("----in main g_num = %d ----" % g_num) if __name__ == ‘__main__‘: main()
传递参数:列表当做实参传递到线程中
import threading import time def test1(temp): temp.append(33) print("----in test1 temp = %s ----" % str(temp)) def test2(temp): print("----in test2 temp = %s ----" % str(temp)) g_nums = [11, 22] def main(): # target指定这个线程去哪个函数执行代码 # args指定调用函数时传递的数据,单个参数要加逗号 t1 = threading.Thread(target=test1, args=(g_nums,)) t2 = threading.Thread(target=test2, args=(g_nums,)) t1.start() time.sleep(1) t2.start() time.sleep(1) print("----in main g_nums = %s ----" % str(g_nums)) if __name__ == ‘__main__‘: main()
在一个进程内的所有线程共享全局变量,很方便在多个线程间共享数据
缺点就是,线程是对全局变量随意遂改可能造成多线程之间对全局变量的混乱(即线程非安全)
5、资源竞争与同步
import threading import time g_num = 0 def test1(num): global g_num for i in range(num): g_num += 1 print("----in test1 g_num = %d ----" % g_num) def test2(num): global g_num for i in range(num): g_num += 1 print("----in test2 g_num = %d ----" % g_num) def main(): t1 = threading.Thread(target=test1, args=(1000000,)) t2 = threading.Thread(target=test2, args=(1000000,)) t1.start() t2.start() # 等待两个线程执行完毕 time.sleep(5) print("----in main g_num = %d ----" % g_num) if __name__ == ‘__main__‘: main()
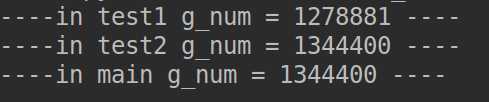
如果多个线程同时对同一个全局变量操作,会出现资源竞争问题,从而数据结果会不正确
假设两个线程t1和t2都要对全局变量g_num(默认是0)进行加1运算,t1和t2都各对g_num加10次,g_num的最终的结果应该为20。但是由于是多线程同时操作,有可能出现下面情况:
同步的概念:同步就是协同步调,按预定的先后次序进行运行。如:你说完,我再说。
"同"字从字面上容易理解为一起动作。其实不是,"同"字应是指协同、协助、互相配合。
如进程、线程同步,可理解为进程或线程A和B一块配合,A执行到一定程度时要依靠B的某个结果,于是停下来,示意B运行;B执行,再将结果给A;A再继续操作。
对于刚刚提出的那个计算错误的问题,可以通过线程同步来进行解决,思路如下:
6、互斥锁
当多个线程几乎同时修改某一个共享数据的时候,需要进行同步控制
线程同步能够保证多个线程安全访问竞争资源,最简单的同步机制是引入互斥锁。
互斥锁为资源引入一个状态:锁定/非锁定
某个线程要更改共享数据时,先将其锁定,此时资源的状态为“锁定”,其他线程不能更改;直到该线程释放资源,将资源的状态变成“非锁定”,其他的线程才能再次锁定该资源。互斥锁保证了每次只有一个线程进行写入操作,从而保证了多线程情况下数据的正确性。
threading模块中定义了Lock类,可以方便的处理锁定:
# 创建锁 mutex = threading.Lock() # 锁定 mutex.acquire() # 释放 mutex.release()
import threading import time g_num = 0 def test1(num): global g_num # 上锁,如果之前没有被上锁,此时上锁成功 # 如果上锁之前已经上过锁,那么此时堵塞,直到这个锁被解开 for i in range(num): mutex.acquire() g_num += 1 mutex.release() print("----in test1 g_num = %d ----" % g_num) def test2(num): global g_num for i in range(num): mutex.acquire() g_num += 1 mutex.release() print("----in test2 g_num = %d ----" % g_num) # 创建一个互斥锁,默认是没有上锁的 mutex = threading.Lock() def main(): t1 = threading.Thread(target=test1, args=(1000000,)) t2 = threading.Thread(target=test2, args=(1000000,)) t1.start() t2.start() time.sleep(3) print("----in main g_num = %d ----" % g_num) if __name__ == ‘__main__‘: main()
7、死锁与银行家算法
在线程间共享多个资源的时候,如果两个线程分别占有一部分资源并且同时等待对方的资源,就会造成死锁。
死锁案例:
import threading import time class MyThreadA(threading.Thread): def run(self): mutexA.acquire() print("1 start") time.sleep(1) mutexB.acquire() print("1 end") mutexB.release() mutexA.release() class MyThreadB(threading.Thread): def run(self): mutexB.acquire() print("2 start") time.sleep(1) mutexA.acquire() print("2 end") mutexA.release() mutexB.release() mutexA = threading.Lock() mutexB = threading.Lock() def main(): t1 = MyThreadA() t2 = MyThreadB() t1.start() t2.start() if __name__ == ‘__main__‘: main()
银行家算法:
[背景知识]
一个银行家如何将一定数目的资金安全地借给若干个客户,使这些客户既能借到钱完成要干的事,同时银行家又能收回全部资金而不至于破产,这就是银行家问题。这个问题同操作系统中资源分配问题十分相似:银行家就像一个操作系统,客户就像运行的进程,银行家的资金就是系统的资源。
[问题的描述]
一个银行家拥有一定数量的资金,有若干个客户要贷款。每个客户须在一开始就声明他所需贷款的总额。若该客户贷款总额不超过银行家的资金总数,银行家可以接收客户的要求。客户贷款是以每次一个资金单位(如1万RMB等)的方式进行的,客户在借满所需的全部单位款额之前可能会等待,但银行家须保证这种等待是有限的,可完成的。
例如:有三个客户C1,C2,C3,向银行家借款,该银行家的资金总额为10个资金单位,其中C1客户要借9各资金单位,C2客户要借3个资金单位,C3客户要借8个资金单位,总计20个资金单位。某一时刻的状态如图所示。
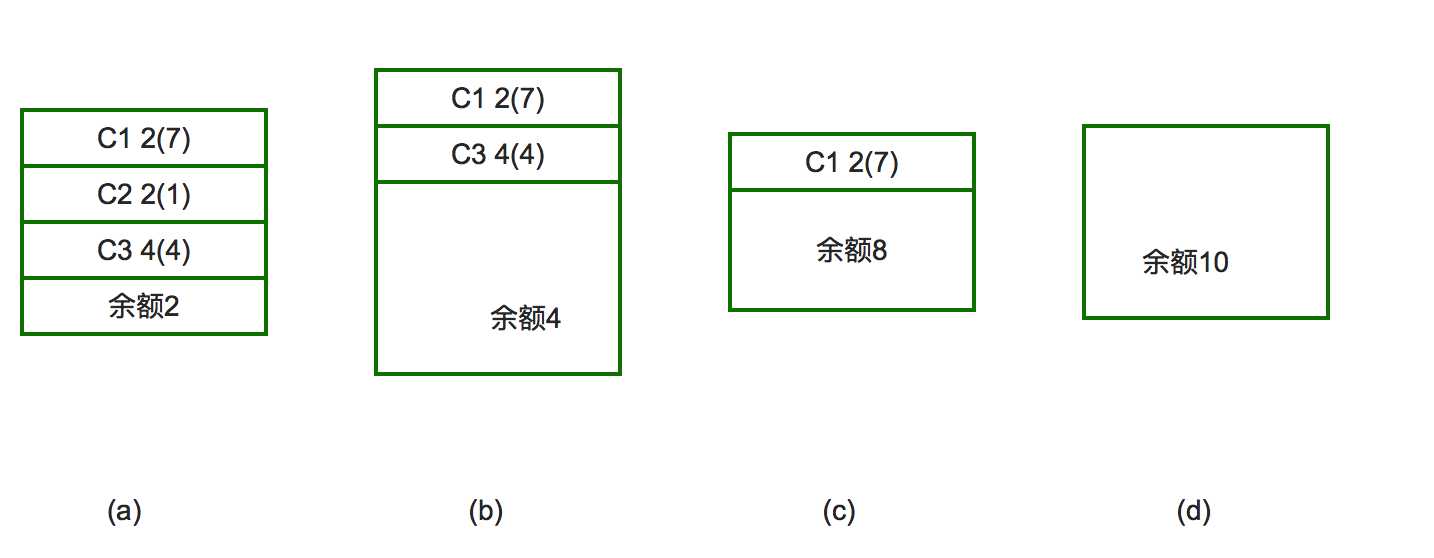

对于a图的状态,按照安全序列的要求,我们选的第一个客户应满足该客户所需的贷款小于等于银行家当前所剩余的钱款,可以看出只有C2客户能被满足:C2客户需1个资金单位,小银行家手中的2个资金单位,于是银行家把1个资金单位借给C2客户,使之完成工作并归还所借的3个资金单位的钱,进入b图。同理,银行家把4个资金单位借给C3客户,使其完成工作,在c图中,只剩一个客户C1,它需7个资金单位,这时银行家有8个资金单位,所以C1也能顺利借到钱并完成工作。最后(见图d)银行家收回全部10个资金单位,保证不赔本。那麽客户序列{C1,C2,C3}就是个安全序列,按照这个序列贷款,银行家才是安全的。否则的话,若在图b状态时,银行家把手中的4个资金单位借给了C1,则出现不安全状态:这时C1,C3均不能完成工作,而银行家手中又没有钱了,系统陷入僵持局面,银行家也不能收回投资。
综上所述,银行家算法是从当前状态出发,逐个按安全序列检查各客户谁能完成其工作,然后假定其完成工作且归还全部贷款,再进而检查下一个能完成工作的客户,......。如果所有客户都能完成工作,则找到一个安全序列,银行家才是安全的。
此外,还可以通过 添加超时时间 的方法解决死锁
8、udp聊天器(多线程版)
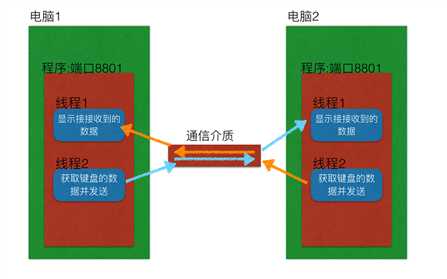
import socket import threading def receive(udp_socket): while True: recv_data = udp_socket.recvfrom(1024) print(recv_data[0].decode(‘gbk‘)) def send(udp_socket): while True: send_data = input() udp_socket.sendto(send_data.encode(‘gbk‘), (‘192.168.0.105‘, 8080)) def main(): udp_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) udp_socket.bind((‘‘, 9876)) recv_thread = threading.Thread(target=receive, args=(udp_socket, )) send_thread = threading.Thread(target=send, args=(udp_socket, )) recv_thread.start() send_thread.start() if __name__ == ‘__main__‘: main()
1、进程及状态
程序:例如xxx.py这是程序,是一个静态的
进程:一个程序运行起来后,代码+用到的资源 称之为进程,它是操作系统分配资源的基本单元。
不仅可以通过线程完成多任务,进程也是可以的
工作中,任务数往往大于cpu的核数,即一定有一些任务正在执行,而另外一些任务在等待cpu进行执行,因此导致了有了不同的状态
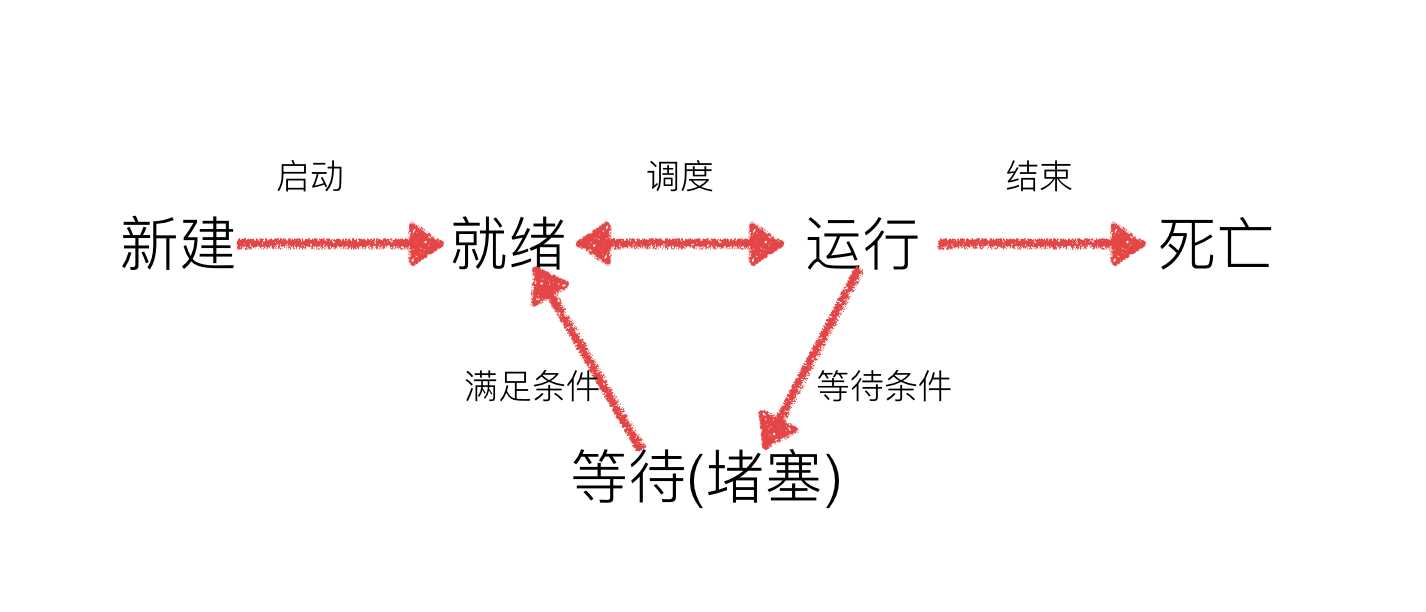
就绪态:运行的条件都已经满足,正在等在cpu执行
执行态:cpu正在执行其功能
等待态:等待某些条件满足,例如一个程序sleep了,此时就处于等待态
2、进程的创建
multiprocessing模块就是跨平台版本的多进程模块,提供了一个Process类来代表一个进程对象,这个对象可以理解为是一个独立的进程,可以执行另外的事情
import multiprocessing import time def test1(): for i in range(5): print("t1:%d" % i) time.sleep(1) def test2(): for i in range(5): print("t2:%d" % i) time.sleep(1) def main(): p1 = multiprocessing.Process(target=test1) p2 = multiprocessing.Process(target=test2) p1.start() p2.start() if __name__ == ‘__main__‘: main()
创建子进程时,只需要传入一个执行函数和函数的参数,创建一个Process实例,用start()方法启动
Process语法结构:
Process([group [, target [, name [, args [, kwargs]]]]])
Process创建的实例对象的常用方法:
Process创建的实例对象的常用属性:
注意:
每个进程都会占用一份资源
进程间不共享全局变量
3、线程与进程对比
进程,能够完成多任务,比如 在一台电脑上能够同时运行多个QQ
线程,能够完成多任务,比如 一个QQ中的多个聊天窗口
进程是系统进行资源分配和调度的一个独立单位.
线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位.线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源.
线程和进程在使用上各有优缺点:线程执行开销小,但不利于资源的管理和保护;而进程正相反。
一个程序至少有一个进程,一个进程至少有一个线程.
线程的划分尺度小于进程(资源比进程少),使得多线程程序的并发性高。
进程在执行过程中拥有独立的内存单元,而多个线程共享内存,从而极大地提高了程序的运行效率
线程不能够独立执行,必须依存在进程中
可以将进程理解为工厂中的一条流水线,而其中的线程就是这个流水线上的工人
4、进程间通信 Queue
可以使用multiprocessing模块的Queue实现多进程之间的数据传递,Queue是一个消息列队程序
import multiprocessing q = multiprocessing.Queue(3) # 最多接收三条put消息 q.put("1") q.put(2) # 队列已满会堵塞 q.put_nowait([3, 4]) # 队列已满就会报错 print(q.full()) # 判断消息队列是否已满 q.get() q.get() print(q.qsize()) # 返回当前队列包含的消息数量 q.get() print(q.empty()) # 判断是否为空
import multiprocessing import time def download(q): """从网上下载数据""" data = [11, 22, 33] for temp in data: q.put(temp) time.sleep(1) print("下载器已经下完数据并存入队列中") def analyse(q): """分析数据""" while True: temp = q.get() print(temp) if q.empty(): break def main(): # 创建一个队列 q = multiprocessing.Queue(3) p1 = multiprocessing.Process(target=download, args=(q, )) p2 = multiprocessing.Process(target=analyse, args=(q, )) p1.start() p1.join() # 等待子进程结束 p2.start() if __name__ == ‘__main__‘: main()
5、进程池
当需要创建的子进程数量不多时,可以直接利用multiprocessing中的Process动态成生多个进程,但如果是上百甚至上千个目标,手动的去创建进程的工作量巨大,此时就可以用到multiprocessing模块提供的Pool方法。
初始化Pool时,可以指定一个最大进程数,当有新的请求提交到Pool中时,如果池还没有满,那么就会创建一个新的进程用来执行该请求;但如果池中的进程数已经达到指定的最大值,那么该请求就会等待,直到池中有进程结束,才会用之前的进程来执行新的任务,请看下面的实例:
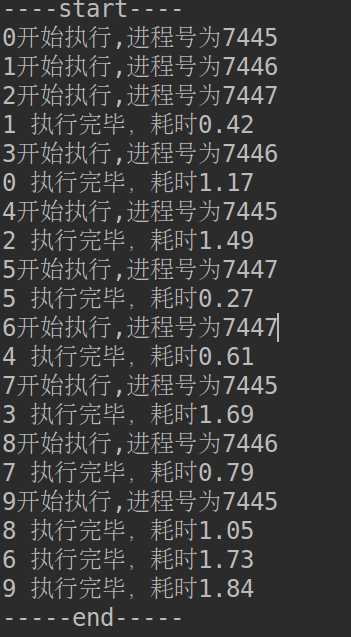
from multiprocessing import Pool import os import time import random def worker(msg): t_start = time.time() print("%s开始执行,进程号为%d" % (msg,os.getpid())) # random.random()随机生成0~1之间的浮点数 time.sleep(random.random()*2) t_stop = time.time() print(msg,"执行完毕,耗时%0.2f" % (t_stop-t_start)) po = Pool(3) # 定义一个进程池,最大进程数3 for i in range(0,10): # Pool().apply_async(要调用的目标,(传递给目标的参数元祖,)) # 每次循环将会用空闲出来的子进程去调用目标 po.apply_async(worker,(i,)) print("----start----") po.close() # 关闭进程池,关闭后po不再接收新的请求 po.join() # 等待po中所有子进程执行完成,必须放在close语句之后 print("-----end-----")
6、文件夹copy器(多进程版)
原文:https://www.cnblogs.com/ysysyzz/p/11143881.html