集成学习方法
通过组合多个弱基分类器来实现强分类器目的,从而提高分类性能。集成学习是一类算法,并不是指一个算法。集成学习策略有非常多种,包括数据层面、模型层面和算法层面三个方面集成,这方面由于研究非常广泛,论文非常多,可以去知网下载硕博论文,论文总结非常全面。常用的两种集成学习方法是:bagging袋装法,典型代表随机森林(Random Forests)和boosting提升法,典型代表GBDT(Gradient Boosting Decision Tree)以及最近非常火热的XGBOOST。
AdaBoost算法原理和有缺点(1995年的算法了)
优点:泛化错误率低,易编码,可以应用在大部分分类器上,无参数调整
缺点:对离群点敏感(这一类都有这个缺点)
首先讲一下boosting的流程
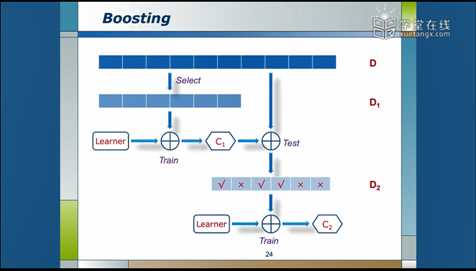
先从数据集D中随机选出一些数据得到数据集D1,通过训练得到分类器C1。
然后再从D中随机选出一些数据,用C1来进行测试,会得到D2,此时的D2中会有一些数据是C1分对了的,有一些是C1分错了的。然后用这些数据进行训练,会得到C2,。
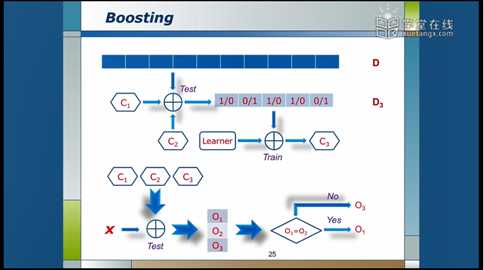
然后再从D中随机选出一些数据,用C1、C2一起来测试,丢弃两个分类器判断相同的结果,对于某个数据如果两个分类器的判断结果不一样则保留,这些保留下来的数据组成D3,然后对D3进行训练得到C3分类器。
预测时,将三个分类器同时作用在数据上,对于C1与C2得到的结果如果一样,就输出O1,如果不一样,则输出C3的结果O3。
以上就是一个简单的boosting算法
由于AdaBoost是boosting的改进方法,而且性能比较稳定,故而在实际中一般都直接使用AdaBoost而不会使用原始的boosting。
adaboost流程:
给定一个样本,例如标签只有-1和1
初始化样本权重,所有样本权重都是一样的
T为分类器的个数
首先训练第一个弱分类器,弱分类器输出后会得到一个错误率,利用错误率来得到一个α,错误率越高,α越小,因为这个分类器比较垃圾,在最后算结果时都是α乘以分类器。垃圾点的分类器肯定权重就要小一点。
根据错误率将样本权重更新,对分错的样本权重要加大,分对的样本权重要缩小,经过t轮之后就得到T个弱分类器。
最后将T个弱分类器乘以各自的权重α相加,经过激活函数的处理,得到结果。
构建单层决策树代码实现:
# -*-coding:utf-8 -*- import numpy as np import matplotlib.pyplot as plt def loadSimpData(): """ 创建单层决策树的数据集 Parameters: 无 Returns: dataMat - 数据矩阵 classLabels - 数据标签 """ datMat = np.matrix([[1., 2.1], #生成一个(5,2)的矩阵 [1.5, 1.6], [1.3, 1.], [1., 1.], [2., 1.]]) classLabels = [1.0, 1.0, -1.0, -1.0, 1.0] #生成一个(1,5)的矩阵 return datMat, classLabels def stumpClassify(dataMatrix, dimen, threshVal, threshIneq): """ 单层决策树分类函数 Parameters: dataMatrix - 数据矩阵 dimen - 第dimen列,也就是第几个特征 threshVal - 阈值 threshIneq - 标志 Returns: retArray - 分类结果 """ retArray = np.ones((np.shape(dataMatrix)[0], 1)) # np.shape(dataMatrix)得到(5,2)[0]为5,所以retArray.shape=(5,1),初始化retArray为1 if threshIneq == ‘lt‘: #因为每一个阈值有两种判断方式,小于阈值为-1或者大于阈值为-1 retArray[dataMatrix[:, dimen] <= threshVal] = -1.0 # 如果小于阈值,则赋值为-1 else: retArray[dataMatrix[:, dimen] > threshVal] = -1.0 # 如果大于阈值,则赋值为-1 return retArray def buildStump(dataArr, classLabels, D): """ 找到数据集上最佳的单层决策树 Parameters: dataArr - 数据矩阵 classLabels - 数据标签 D - 样本权重 Returns: bestStump - 最佳单层决策树信息 minError - 最小误差 bestClasEst - 最佳的分类结果 """ dataMatrix = np.mat(dataArr); #dataMatrix.shape=(5,2) labelMat = np.mat(classLabels).T #labelMat.shape = (5,1) m, n = np.shape(dataMatrix) #m=5,n=2 numSteps = 10.0; bestStump = {}; bestClasEst = np.mat(np.zeros((m, 1))) #初始化为(5,1),值为0 minError = float(‘inf‘) # 最小误差初始化为正无穷大 for i in range(n): # 遍历所有特征 rangeMin = dataMatrix[:, i].min(); #例如当i=0时,从第0列中取最小值 rangeMax = dataMatrix[:, i].max() # 找到特征中最小的值和最大值 stepSize = (rangeMax - rangeMin) / numSteps # 计算步长 for j in range(-1, int(numSteps) + 1): #对其中一个特征进行阈值划分 for inequal in [‘lt‘, ‘gt‘]: # 大于和小于的情况,均遍历。lt:less than,gt:greater than threshVal = (rangeMin + float(j) * stepSize) # 计算阈值,例如第一轮阈值为0.9=1+(-1)*10 predictedVals = stumpClassify(dataMatrix, i, threshVal, inequal) # 计算分类结果 errArr = np.mat(np.ones((m, 1))) # 初始化误差矩阵 errArr[predictedVals == labelMat] = 0 # 分类正确的,赋值为0 weightedError = D.T * errArr # 计算误差,第一轮0.4=0.2*2 print("split: dim %d, thresh %.2f, thresh ineqal: %s, the weighted error is %.3f" % ( i, threshVal, inequal, weightedError)) if weightedError < minError: # 找到误差最小的分类方式,然后将数据更新 minError = weightedError bestClasEst = predictedVals.copy() bestStump[‘dim‘] = i bestStump[‘thresh‘] = threshVal bestStump[‘ineq‘] = inequal return bestStump, minError, bestClasEst if __name__ == ‘__main__‘: dataArr, classLabels = loadSimpData() D = np.mat(np.ones((5, 1)) / 5) bestStump, minError, bestClasEst = buildStump(dataArr, classLabels, D) print(‘bestStump:\n‘, bestStump) print(‘minError:\n‘, minError) print(‘bestClasEst:\n‘, bestClasEst)
原文:https://www.cnblogs.com/roscangjie/p/11179348.html