python , scrapy框架入门 , xpath解析, json 存储.
涉及到详情页爬取,
目录结构:
kaoshi_bqg.py
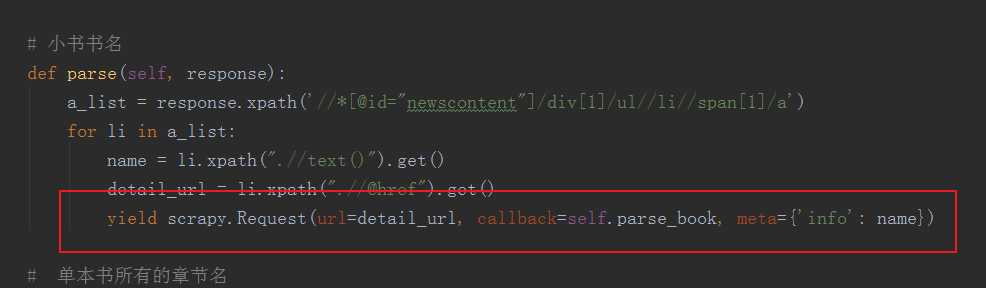
import scrapy from scrapy.spiders import Rule from scrapy.linkextractors import LinkExtractor from ..items import BookBQGItem class KaoshiBqgSpider(scrapy.Spider): name = ‘kaoshi_bqg‘ allowed_domains = [‘biquge5200.cc‘] start_urls = [‘https://www.biquge5200.cc/xuanhuanxiaoshuo/‘] rules = ( # 编写匹配文章列表的规则 Rule(LinkExtractor(allow=r‘https://www.biquge5200.cc/xuanhuanxiaoshuo/‘), follow=True), # 匹配文章详情 Rule(LinkExtractor(allow=r‘.+/[0-9]{1-3}_[0-9]{2-6}/‘), callback=‘parse_item‘, follow=False), ) # 小书书名 def parse(self, response): a_list = response.xpath(‘//*[@id="newscontent"]/div[1]/ul//li//span[1]/a‘) for li in a_list: name = li.xpath(".//text()").get() detail_url = li.xpath(".//@href").get() yield scrapy.Request(url=detail_url, callback=self.parse_book, meta={‘info‘: name}) # 单本书所有的章节名 def parse_book(self, response): name = response.meta.get(‘info‘) list_a = response.xpath(‘//*[@id="list"]/dl/dd[position()>20]//a‘) for li in list_a: chapter = li.xpath(".//text()").get() url = li.xpath(".//@href").get() yield scrapy.Request(url=url, callback=self.parse_content, meta={‘info‘: (name, chapter)}) # 每章节内容 def parse_content(self, response): name, chapter = response.meta.get(‘info‘) content = response.xpath(‘//*[@id="content"]//p/text()‘).getall() item = BookBQGItem(name=name, chapter=chapter, content=content) yield item
item.py
import scrapy # 笔趣阁字段 class BookBQGItem(scrapy.Item): name = scrapy.Field() chapter = scrapy.Field() content = scrapy.Field() # 喜马拉雅 字段 class BookXMLYItem(scrapy.Item): book_name = scrapy.Field() book_id = scrapy.Field() book_url = scrapy.Field() book_author = scrapy.Field() # 喜马拉雅详情字段 class BookChapterItem(scrapy.Item): book_id = scrapy.Field() chapter_id = scrapy.Field() chapter_name = scrapy.Field() chapter_url = scrapy.Field()
pipelines.py
from scrapy.exporters import JsonLinesItemExporter class BqgPipeline(object): def __init__(self): self.fp = open("biquge.json", ‘wb‘) # JsonLinesItemExporter 调度器 self.exporter = JsonLinesItemExporter(self.fp, ensure_ascii=False) def process_item(self, item, spider): self.exporter.export_item(item) return item def close_item(self): self.fp.close() print("爬虫结束") # class XmlyPipeline(object): # def __init__(self): # self.fp = open("xmly.json", ‘wb‘) # # JsonLinesItemExporter 调度器 # self.exporter = JsonLinesItemExporter(self.fp, ensure_ascii=False) # # def process_item(self, item, spider): # self.exporter.export_item(item) # return item # # def close_item(self): # self.fp.close() # print("爬虫结束")
starts.py
from scrapy import cmdline cmdline.execute("scrapy crawl kaoshi_bqg".split()) # cmdline.execute("scrapy crawl xmly".split())
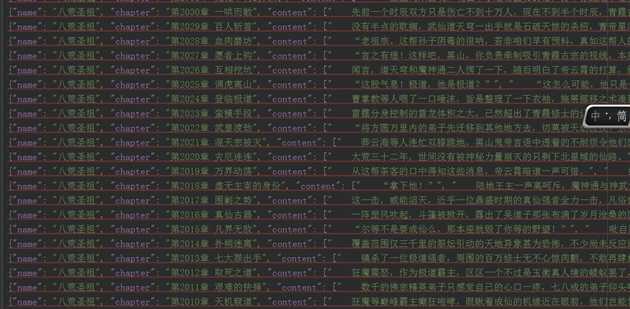
然后是爬取到的数据
biquge.json
xmly.json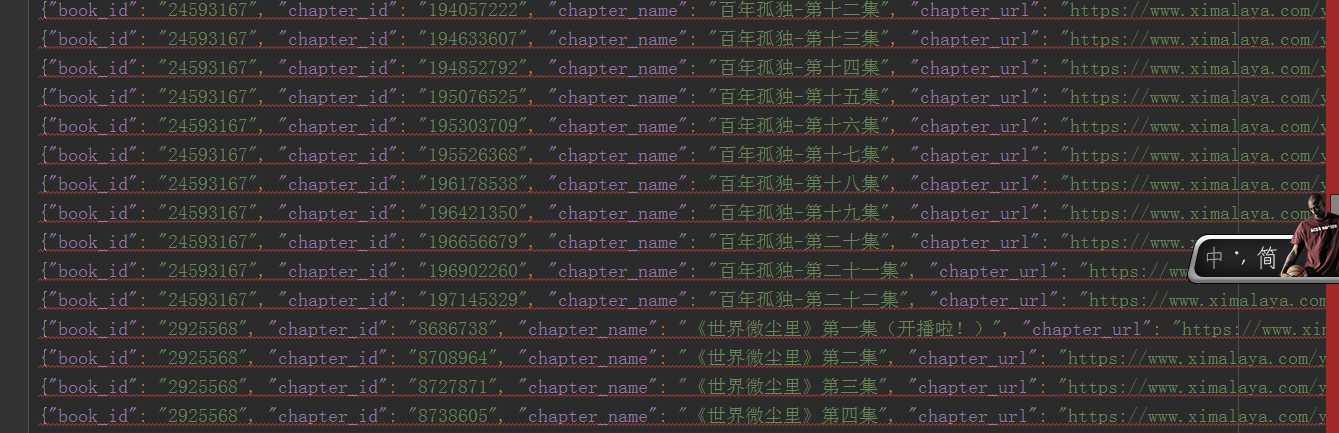
原文:https://www.cnblogs.com/longpy/p/11180956.html