这里说的Spark Thrift JDBCServer并不是网上大部分写到的Spark数据结果落地到RDB数据库中所使用的JDBC方式,而是指Spark启动一个名为thriftserver的进程以供客户端提供JDBC连接,进而使用SQL语句进行查询分析。
http://spark.apache.org/docs/2.3.3/sql-programming-guide.html#running-the-thrift-jdbcodbc-server
后面的文章分析中,我会先说明一个基本的演进过程,即为什么会使用到Spark Thrift JDBCServer,其在大数据生态栈中大致是处于一个什么样的位置?我想理解了这些之后,使用Spark Thrift JDBCServer会显得更加“自然”。不过如果读者本身已经经历过MapReduce、Hive、Spark On Yarn、Spark On Yarn With Hive、Spark SQL等的一些使用历程,相信只要看过官方文档的介绍,应该就能知道其定位以及出现的原因。因此这部分实际上是介绍一些相关大数据组件的作用以及演进,通过这些介绍来理解Spark Thrift JDBCServer所处在的位置。
在实际工作场景中,可能这些环境都不是你自己搭建的,可能你只是需要去连接Spark Thrift JDBCServer以使用Spark SQL的分析能力,或者基于Spark Thrift JDBCServer开发一些服务中间件,但仍然可以确定的是,你还是需要掌握其原理,并且热切希望能自己搭个简单的环境体验一下。我会在已经搭建的Hadoop伪分布式环境下,大致说明如何应用Spark Thrift JDBCServer,以及有哪些注意事项。
文章多数是按照个人的理解进行说明,如有相关错误,还望批评指正。
大数据产品或大数据平台,不管底层的技术使用多么复杂,其最终都是希望产品交到用户手中,能够快速简单地使用起来进行大数据分析,尽快和尽可能地处理大量数据,以更好地挖掘数据的价值。而进行数据分析最好用的工具或语言之一显然就是SQL了,因此大多数据大数据产品、框架或技术,一般都会提供SQL接口。放眼来看现在的比较主流的大数据框架,也是如此,比如有Hive、Spark SQL、Elasticsearch SQL、Druid SQL等。
这里会简要介绍
MapReduce是Hadoop的分布式计算框架,结合Hadoop的分布式存储HDFS,使得大规模的批量数据处理成为可能。通过MapReduce提供的简单接口,用户可以在不了解其底层的情况下,快速构建分布式应用程序,大大提高了开发分布式数据处理程序的效率。
但由于MapReduce在数据处理过程中,中间生成结果都是存放在磁盘,因此其处理速度很慢,尽管如此,对于大规模的离线数据处理,MapReduce仍然会是一个不错的选择。
尽管基于MapReduce提供的接口开发分布式程序已经比较简单了,但由于仍然需要进行编码,这对于一些从来没有接触过编程的数据分析人员或运维人员,其还是会有不少的学习成本。于是Hive便出现了。
Hive被称为SQL On Hadoop或者SQL On MapReduce,是一款建立在Hadoop之上的数据仓库的基础框架,简单理解,在Hive上,你可以像在RDB中一样,编写SQL语句来对你的数据进行分析,Hive的解释器会把SQL语句转换为MapRedcue作业,提交到Yarn上去运行,这样一来,只要会写SQL语句,你就能构建强大的MapReduce分布式应用程序。
Hive提供了一个命令行终端,在安装了Hive的机器上,配置好了元数据信息数据库和指定了Hadoop的配置文件之后输入hive命令,就可以进入到hive的交互式终端,接下来只要编写SQL语句即可,这跟传统RDB数据库提供的终端是类似的。
我们知道传统的RDB数据库,比如MySQL,不仅提供了交互式终端操作,也可以在编码在代码中去连接MySQL以进行操作,比如在Java中可以通过JDBC进行连接,毕竟在实际业务中,更多时候是使用其提供的编程接口,而不是仅仅是交互式终端。
Hive也是类似的。Hive除了提供前面的cli用户接口,还提供了jdbc的用户接口,但是如果需要使用该接口,则需要先启动hiveserver2服务,启动该服务后,可以通过hive提供的beeline继续以cli的方式操作hive(不过需要注意的是,此时是通过jdbc接口进行操作hive的),也可以通过手工编写java代码来进行操作。
通过hiverserver2,就可以通过Java JDBC进行连接,这样以实现更多更复杂的业务逻辑。
Spark也是一个分布式计算引擎,其将处理的数据抽象为RDD或Dataset保存到内存中,中间处理结果也保存到内存中,因此其速度比MapReduce要快10到100倍。
基于Spark提供的接口和各种算子,可以十分轻易地开发出功能强大的分布式数据处理程序。
使用Spark的基本功能时,也是需要使用代码进行操作的,为了更方便地使用Spark,其也提供了SQL相关接口——Spark SQL。
这似乎跟Hive在MapReduce中提供的CLI功能很相似,不过与Hive不同的在于,使用Spark SQL,仍然需要一定程序地使用代码进行相关表的创建和元数据设置,之后才可以继续使用SQL语句进行表的操作,这点使用过Spark SQL的同学应该很清楚。而使用Hive时,直接编写SQL语句创建表、写入数据、分析数据即可,不需要额外的代码操作。
如何避免前面Spark SQL中的这种尴尬?Spark SQL的其中一个分支就是Spark on Hive,也就是使用Hive中HQL的解析、逻辑执行计划翻译、执行计划优化等逻辑,可以近似认为仅将物理执行计划从MR作业替换成了Spark作业。SparkSql整合hive就是获取hive表中的元数据信息,然后通过SparkSql来操作数据。
跟hiveserver2的作用一样,Spark Thrift JDBCServer是Spark的一个进程,启动之后就可以通过Java JDBC代码进行连接操作,该进程本质上是Spark的一个Application。
Spark Thrift JDBCServer本身也是可以和Hive整合使用。
Spark Thrift JDBCServer的使用是基于下面和个方面的考虑:
现在一般Spark应用程序会部署到Hadoop的Yarn上进行调度,虽然Spark本身也提供了standalone的部署模式。
而在使用Spark SQL时,因为大部分数据一般都是保存在HDFS上,而Hive本身就是操作HDFS上的数据,因此一般会将Spark SQL和Hive整合使用,即如2.6中所提到的,元数据信息是使用Hive表的,而真正处理数据时使用的计算引擎是Spark的。
当希望通过Java JDBC的方式使用Spark SQL的能力时,就可以使用Spark Thrift JDBCServer,并且其本身也是可以和Hive整合使用。
其使用非常简单,几乎不用做任何操作,这里使用spark-2.3.3-bin-hadoop2.6.tgz版本,下载链接如下:
https://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-2.3.3/spark-2.3.3-bin-hadoop2.6.tgz
这里使用国内的Apache镜像源,下载速度非常快!推荐大家使用:https://mirrors.tuna.tsinghua.edu.cn/apache/
将下载的安装包解压缩之后,直接启动:
$ cd sbin/
$ ./start-thriftserver.sh默认侦听10000端口:
$ lsof -i:10000
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
java 1414 yeyonghao 407u IPv6 0x3cb645c07427abbb 0t0 TCP *:ndmp (LISTEN)前面说过了,其本质上是Spark的一个Application,因此可以看到这时4040端口也启动了:
$ lsof -i:4040
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
java 1414 yeyonghao 270u IPv6 0x3cb645c07427d3fb 0t0 TCP *:yo-main (LISTEN)使用jps命令查看,可以看到有SparkSubmit进程:
$ jps
901 SecondaryNameNode
1445 Jps
806 DataNode
1414 SparkSubmit
729 NameNode
1132 NodeManager
1053 ResourceManager我这里另外还启动了Hadoop的伪分布式环境。
不妨打开浏览器看一下4040端口的页面:

可以说是相当熟悉的页面了,注意右上角其名称为:Thrift JDBC/ODBC Server,启动Thriftserver,其本质上就是提交了Spark的一个Application!(如果有使用过Spark Shell的同学也应该知道,Spark Shell也是Spark的一个Application)
那么如何进行连接操作呢?Spark提供了一个beeline连接工具。
$ cd bin/
$ ./beeline然后连接上Thriftserver:
Beeline version 1.2.1.spark2 by Apache Hive
beeline> !connect jdbc:hive2://localhost:10000
Connecting to jdbc:hive2://localhost:10000
Enter username for jdbc:hive2://localhost:10000:
Enter password for jdbc:hive2://localhost:10000:
2019-07-13 15:58:40 INFO Utils:310 - Supplied authorities: localhost:10000
2019-07-13 15:58:40 INFO Utils:397 - Resolved authority: localhost:10000
2019-07-13 15:58:40 INFO HiveConnection:203 - Will try to open client transport with JDBC Uri: jdbc:hive2://localhost:10000
Connected to: Spark SQL (version 2.3.3)
Driver: Hive JDBC (version 1.2.1.spark2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://localhost:10000>之后就可以进行各种SQL操作:
0: jdbc:hive2://localhost:10000> create table person
0: jdbc:hive2://localhost:10000> (
0: jdbc:hive2://localhost:10000> id int,
0: jdbc:hive2://localhost:10000> name string
0: jdbc:hive2://localhost:10000> );
+---------+--+
| Result |
+---------+--+
+---------+--+
No rows selected (1.116 seconds)
0: jdbc:hive2://localhost:10000> insert into person values(1,‘xpleaf‘);
+---------+--+
| Result |
+---------+--+
+---------+--+
No rows selected (1.664 seconds)
0: jdbc:hive2://localhost:10000> select * from person;
+-----+---------+--+
| id | name |
+-----+---------+--+
| 1 | xpleaf |
+-----+---------+--+
1 row selected (0.449 seconds)这时再去前面说的4040页面看一下:
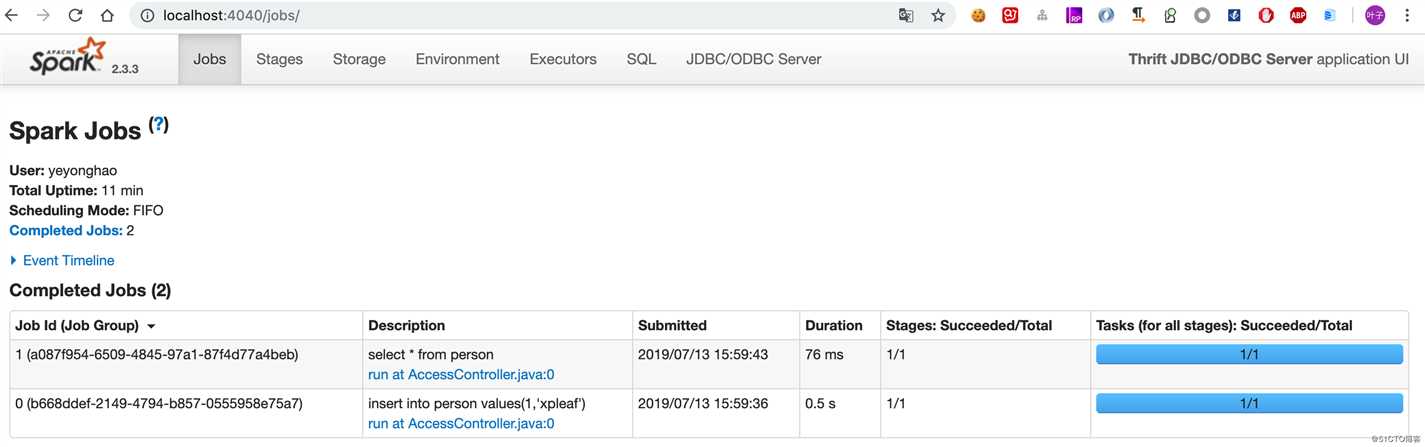
可以看到我们的操作其实都是被转换为了Spark Application中的一个个Job进行操作。
既然其是一个JDBC服务,那么当然可以通过Java代码来进行操作。
创建一个Maven工程,添加下面的依赖:
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>1.2.1</version>
</dependency>编写代码如下:
package cn.xpleaf.spark;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
/**
* @author xpleaf
* @date 2019/7/13 4:06 PM
*/
public class SampleSparkJdbcServer {
public static void main(String[] args) throws Exception {
Class.forName("org.apache.hive.jdbc.HiveDriver");
Connection connection = DriverManager.getConnection("jdbc:hive2://localhost:10000");
Statement statement = connection.createStatement();
String sql = "select * from person";
ResultSet resultSet = statement.executeQuery(sql);
while (resultSet.next()) {
int id = resultSet.getInt("id");
String name = resultSet.getString("name");
System.out.println(String.format("id: %s, name: %s", id, name));
}
}
}启动后运行结果如下:
id: 1, name: xpleaf前面的方式创建表和写入的数据,都是保存在内存中,因此只要thirfserver退出,数据就会丢失,所以为了持久化这些数据,后面我们为与Hive进行整合。
整合Hive的一个明显好处是,我们既可以借助了HDFS进行分布式存储,持久化我们的数据,也可以借助Spark本身的快速计算能力以快速处理数据,而这中间,需要借助Hive来做“中间人”,本质上我们是使用了Hive创建的各种元数据信息表。
安装Hive前需要先搭建Hadoop环境,这里不介绍Hadoop环境如何搭建,在我的机器上,已经搭建了一个Hadoop的伪分布式环境。
$ jps
901 SecondaryNameNode
1557 RemoteMavenServer
806 DataNode
729 NameNode
1834 Jps
1547
1132 NodeManager
1053 ResourceManager实际上Hive安装的三个前提条件为:
JDK // Java环境
HADOOP // Hadoop环境
MySQL // 关系型数据库,持久化存储Hive的元数据信息这里是假设这三个步骤都已经完成。
Hive的下载依然可以使用前面介绍的国内Apache镜像源:
https://mirrors.tuna.tsinghua.edu.cn/apache/hive/hive-2.3.5/apache-hive-2.3.5-bin.tar.gz
即这里使用的版本为2.3.5。
下载完成后,解压缩到指定目录,然后再配置相关文件。
(1)配置hive-env.sh
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_181.jdk/Contents/Home
export HADOOP_HOME=/Users/yeyonghao/app/hadoop
export HIVE_HOME=/Users/yeyonghao/app2/hive(2)配置hive-site.xml
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
<property>
<name>hive.querylog.location</name>
<value>/Users/yeyonghao/app2/hive/tmp</value>
</property>
<property>
<name>hive.exec.local.scratchdir</name>
<value>/Users/yeyonghao/app2/hive/tmp</value>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/Users/yeyonghao/app2/hive/tmp</value>
</property>(3)将mysql驱动拷贝到$HIVE_HOME/lib目录下
直接从maven中下载:
~/app2/hive/lib$ wget https://repo1.maven.org/maven2/mysql/mysql-connector-java/5.1.39/mysql-connector-java-5.1.39.jar(4)初始化Hive元数据库
~/app2/hive/bin$ ./schematool -initSchema -dbType mysql -userName root -passWord root成功后可以在mysql中看到创建的hive数据库和相关表:
mysql> use hive;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> show tables;
+---------------------------+
| Tables_in_hive |
+---------------------------+
| AUX_TABLE |
| BUCKETING_COLS |
| CDS |
| COLUMNS_V2 |
| COMPACTION_QUEUE |
| COMPLETED_COMPACTIONS |
| COMPLETED_TXN_COMPONENTS |
| DATABASE_PARAMS |
| DBS |
| DB_PRIVS |
| DELEGATION_TOKENS |
| FUNCS |
| FUNC_RU |
| GLOBAL_PRIVS |
| HIVE_LOCKS |
| IDXS |
| INDEX_PARAMS |
| KEY_CONSTRAINTS |
| MASTER_KEYS |
| NEXT_COMPACTION_QUEUE_ID |
| NEXT_LOCK_ID |
| NEXT_TXN_ID |
| NOTIFICATION_LOG |
| NOTIFICATION_SEQUENCE |
| NUCLEUS_TABLES |
| PARTITIONS |
| PARTITION_EVENTS |
| PARTITION_KEYS |
| PARTITION_KEY_VALS |
| PARTITION_PARAMS |
| PART_COL_PRIVS |
| PART_COL_STATS |
| PART_PRIVS |
| ROLES |
| ROLE_MAP |
| SDS |
| SD_PARAMS |
| SEQUENCE_TABLE |
| SERDES |
| SERDE_PARAMS |
| SKEWED_COL_NAMES |
| SKEWED_COL_VALUE_LOC_MAP |
| SKEWED_STRING_LIST |
| SKEWED_STRING_LIST_VALUES |
| SKEWED_VALUES |
| SORT_COLS |
| TABLE_PARAMS |
| TAB_COL_STATS |
| TBLS |
| TBL_COL_PRIVS |
| TBL_PRIVS |
| TXNS |
| TXN_COMPONENTS |
| TYPES |
| TYPE_FIELDS |
| VERSION |
| WRITE_SET |
+---------------------------+
57 rows in set (0.00 sec)(5)Hive测试
启动Hive Cli:
~/app2/hive/bin$ ./hive创建相关表并写入数据:
hive> show databases;
OK
default
Time taken: 0.937 seconds, Fetched: 1 row(s)
hive> show tables;
OK
Time taken: 0.059 seconds
hive> create table person
> (
> id int,
> name string
> );
OK
Time taken: 0.284 seconds
hive> insert into person values(1,‘xpleaf‘);
...省略提交MapReduce作业信息...
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 HDFS Read: 4089 HDFS Write: 79 SUCCESS
Total MapReduce CPU Time Spent: 0 msec
OK
Time taken: 17.54 seconds
hive> select * from person;
OK
1 xpleaf
Time taken: 0.105 seconds, Fetched: 1 row(s)官方文档关于这部分的说明:
Configuration of Hive is done by placing your hive-site.xml, core-site.xml and hdfs-site.xml files in conf/.
其实也就是将Hive的配置文件hive-site.xml,Hadoop的配置文件core-site.xml和hdfs-site.xml放到Spark的配置目录下。
之后再启动Thirftserver:
~/app2/spark/sbin$ ./start-thriftserver.sh
starting org.apache.spark.sql.hive.thriftserver.HiveThriftServer2, logging to /Users/yeyonghao/app2/spark/logs/spark-yeyonghao-org.apache.spark.sql.hive.thriftserver.HiveThriftServer2-1-yeyonghaodeMacBook-Pro.local.out但是后面会看到其并没有启动:
$ lsof -i:10000查看启动日志,看到其报错信息如下:
980 Caused by: org.datanucleus.store.rdbms.connectionpool.DatastoreDriverNotFoundException: The specified datastore driver ("com.mysql.jdbc.Driver") was not found in the CLASSPATH. Please check your CLASS PATH specification, and the name of the driver.
981 at org.datanucleus.store.rdbms.connectionpool.AbstractConnectionPoolFactory.loadDriver(AbstractConnectionPoolFactory.java:58)
982 at org.datanucleus.store.rdbms.connectionpool.BoneCPConnectionPoolFactory.createConnectionPool(BoneCPConnectionPoolFactory.java:54)
983 at org.datanucleus.store.rdbms.ConnectionFactoryImpl.generateDataSources(ConnectionFactoryImpl.java:238)
984 ... 91 more也就是找不到mysql驱动,可以将之前hive下的该驱动拷贝到spark的jars目录下:
cp ~/app2/hive/lib/mysql-connector-java-5.1.39.jar ~/app2/spark/jars/然后再启动,看日志时发现其还是报错:
Caused by: MetaException(message:Hive Schema version 1.2.0 does not match metastore‘s schema version 2.1.0 Metastore is not upgraded or corrupt)原因,看spark jars目录下提供的jar包:
~/app2/spark/jars$ ls hive-
hive-beeline-1.2.1.spark2.jar hive-cli-1.2.1.spark2.jar hive-exec-1.2.1.spark2.jar hive-jdbc-1.2.1.spark2.jar hive-metastore-1.2.1.spark2.jar显然都是hive 1.x的版本。
但我安装的Hive是2.x版本,在mysql中有一个VERSION表保存其版本为2.1.0。
参考:https://yq.aliyun.com/articles/624494
这里我在spark的hive-site.xml中关闭版本验证:
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>修改完成后可以看到成功启动的日志信息:
...
2019-07-13 17:16:47 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@1774c4e2{/sqlserver/session,null,AVAILABLE,@Spark}
2019-07-13 17:16:47 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@f0381f0{/sqlserver/session/json,null,AVAILABLE,@Spark}
2019-07-13 17:16:47 INFO ThriftCLIService:98 - Starting ThriftBinaryCLIService on port 10000 with 5...500 worker threads看一下端口号:
~/app2/spark/sbin$ lsof -i:10000
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
java 5122 yeyonghao 317u IPv6 0x3cb645c07a5bcbbb 0t0 TCP *:ndmp (LISTEN)这里我们启动beeline进行操作:
~/app2/spark/bin$ ./beeline
Beeline version 1.2.1.spark2 by Apache Hive之前我们在Hive中创建了一张person表,如果跟Hive整合成功,那么这里也应该可以看到,因为共用的是同一个metastore,如下查看其中的数据:
beeline> !connect jdbc:hive2://localhost:10000
Connecting to jdbc:hive2://localhost:10000
Enter username for jdbc:hive2://localhost:10000:
Enter password for jdbc:hive2://localhost:10000:
2019-07-13 17:20:02 INFO Utils:310 - Supplied authorities: localhost:10000
2019-07-13 17:20:02 INFO Utils:397 - Resolved authority: localhost:10000
2019-07-13 17:20:02 INFO HiveConnection:203 - Will try to open client transport with JDBC Uri: jdbc:hive2://localhost:10000
Connected to: Spark SQL (version 2.3.3)
Driver: Hive JDBC (version 1.2.1.spark2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://localhost:10000> show tables;
+-----------+------------+--------------+--+
| database | tableName | isTemporary |
+-----------+------------+--------------+--+
| default | person | false |
+-----------+------------+--------------+--+
1 row selected (0.611 seconds)
0: jdbc:hive2://localhost:10000> select * from person;
+-----+---------+--+
| id | name |
+-----+---------+--+
| 1 | xpleaf |
+-----+---------+--+
1 row selected (1.842 seconds)可以看到,没有问题,再查看4040端口:
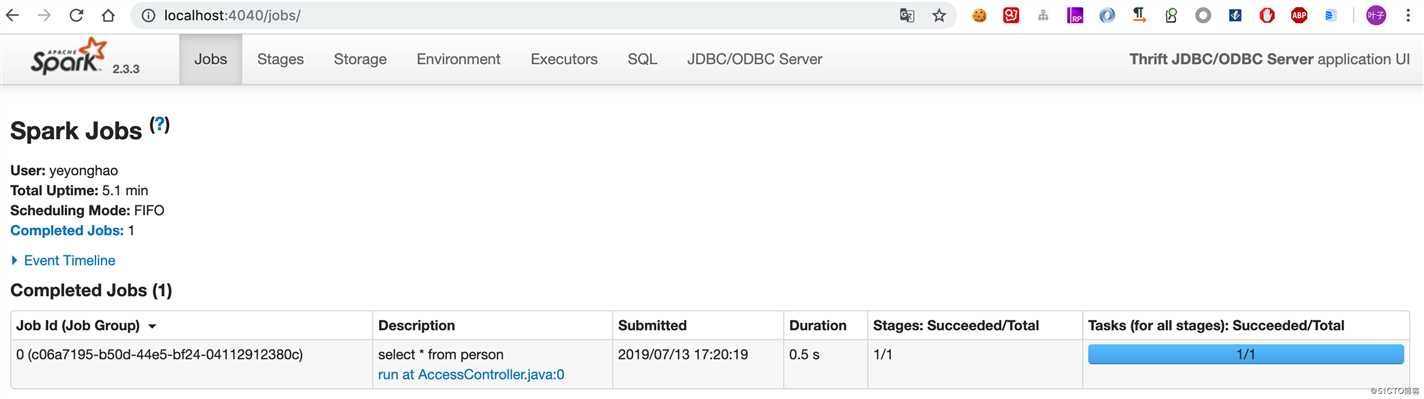
这里我们再创建一张person2表:
0: jdbc:hive2://localhost:10000> create table person2
0: jdbc:hive2://localhost:10000> (
0: jdbc:hive2://localhost:10000> id int,
0: jdbc:hive2://localhost:10000> name string
0: jdbc:hive2://localhost:10000> );
+---------+--+
| Result |
+---------+--+
+---------+--+
No rows selected (0.548 seconds)这时可以去保存元数据信息的mysql数据库中看一下,在tbls表中保存了我们创建的数据表信息:
mysql> select * from tbls;
+--------+-------------+-------+------------------+-----------+-----------+-------+----------+---------------+--------------------+--------------------+
| TBL_ID | CREATE_TIME | DB_ID | LAST_ACCESS_TIME | OWNER | RETENTION | SD_ID | TBL_NAME | TBL_TYPE | VIEW_EXPANDED_TEXT | VIEW_ORIGINAL_TEXT |
+--------+-------------+-------+------------------+-----------+-----------+-------+----------+---------------+--------------------+--------------------+
| 1 | 1563008351 | 1 | 0 | yeyonghao | 0 | 1 | person | MANAGED_TABLE | NULL | NULL |
| 6 | 1563009667 | 1 | 0 | yeyonghao | 0 | 6 | person2 | MANAGED_TABLE | NULL | NULL |
+--------+-------------+-------+------------------+-----------+-----------+-------+----------+---------------+--------------------+--------------------+
2 rows in set (0.00 sec)可以看到已经有person2表的信息了,说明Thirftserver与Hive整合成功。
前面3.2其实已经整合了Hive,这里再跟Yarn做整合。
前面说了,Thirftserver本质上就是Spark的一个Application,因此,我们也可以在启动Thirftserver时指定master为yarn,其实就是将Thirftserver这个Spark Application部署到Yarn上,让Yarn为其分配资源,调度其作业的执行。
官方文档关于这点说明如下:
his script accepts all bin/spark-submit command line options, plus a --hiveconf option to specify Hive properties. You may run ./sbin/start-thriftserver.sh --help for a complete list of all available options. By default, the server listens on localhost:10000. You may override this behaviour via either environment variables, i.e.:
……也就是说saprk-submit脚本接收的参数,start-thriftserver.sh也能接收。
现在,使用下面的启动方式:
~/app2/spark/sbin$ ./start-thriftserver.sh --master yarn
starting org.apache.spark.sql.hive.thriftserver.HiveThriftServer2, logging to /Users/yeyonghao/app2/spark/logs/spark-yeyonghao-org.apache.spark.sql.hive.thriftserver.HiveThriftServer2-1-yeyonghaodeMacBook-Pro.local.out
failed to launch: nice -n 0 bash /Users/yeyonghao/app2/spark/bin/spark-submit --class org.apache.spark.sql.hive.thriftserver.HiveThriftServer2 --name Thrift JDBC/ODBC Server --master yarn
Spark Command: /Library/Java/JavaVirtualMachines/jdk1.8.0_181.jdk/Contents/Home/bin/java -cp /Users/yeyonghao/app2/spark/conf/:/Users/yeyonghao/app2/spark/jars/* -Xmx1g org.apache.spark.deploy.SparkSubmit --master yarn --class org.apache.spark.sql.hive.thriftserver.HiveThriftServer2 --name Thrift JDBC/ODBC Server spark-internal
========================================
Exception in thread "main" java.lang.Exception: When running with master ‘yarn‘ either HADOOP_CONF_DIR or YARN_CONF_DIR must be set in the environment.
at org.apache.spark.deploy.SparkSubmitArguments.validateSubmitArguments(SparkSubmitArguments.scala:288)
at org.apache.spark.deploy.SparkSubmitArguments.validateArguments(SparkSubmitArguments.scala:248)
at org.apache.spark.deploy.SparkSubmitArguments.<init>(SparkSubmitArguments.scala:120)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:130)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
full log in /Users/yeyonghao/app2/spark/logs/spark-yeyonghao-org.apache.spark.sql.hive.thriftserver.HiveThriftServer2-1-yeyonghaodeMacBook-Pro.local.out可以看到其报错信息,关键为:
When running with master ‘yarn‘ either HADOOP_CONF_DIR or YARN_CONF_DIR must be set in the environment.直接在spark-env.sh中添加:
HADOOP_CONF_DIR=/Users/yeyonghao/app/hadoop/etc/hadoop
YARN_CONF_DIR=/Users/yeyonghao/app/hadoop/etc/hadoop之后再启动就没有问题了,看日志可以知道,其本质上就是把Thirftserver作为Spark Application,然后提交到Yarn上去调度:
73 2019-07-13 17:35:22 INFO Client:54 - Application report for application_1563008220920_0002 (state: ACCEPTED)
74 2019-07-13 17:35:22 INFO Client:54 -
75 client token: N/A
76 diagnostics: N/A
77 ApplicationMaster host: N/A
78 ApplicationMaster RPC port: -1
79 queue: default
80 start time: 1563010521752
81 final status: UNDEFINED
82 tracking URL: http://192.168.1.2:8088/proxy/application_1563008220920_0002/
83 user: yeyonghao
84 2019-07-13 17:35:23 INFO Client:54 - Application report for application_1563008220920_0002 (state: ACCEPTED)
85 2019-07-13 17:35:24 INFO Client:54 - Application report for application_1563008220920_0002 (state: ACCEPTED)
86 2019-07-13 17:35:25 INFO Client:54 - Application report for application_1563008220920_0002 (state: ACCEPTED)
87 2019-07-13 17:35:26 INFO Client:54 - Application report for application_1563008220920_0002 (state: ACCEPTED)
88 2019-07-13 17:35:27 INFO Client:54 - Application report for application_1563008220920_0002 (state: ACCEPTED)
89 2019-07-13 17:35:28 INFO YarnClientSchedulerBackend:54 - Add WebUI Filter. org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter, Map(PROXY_HOSTS -> 192.168.1.2, PROXY_URI_BASES -> http://192.1 68.1.2:8088/proxy/application_1563008220920_0002), /proxy/application_1563008220920_0002
90 2019-07-13 17:35:28 INFO JettyUtils:54 - Adding filter org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter to /jobs, /jobs/json, /jobs/job, /jobs/job/json, /stages, /stages/json, /stages/stag e, /stages/stage/json, /stages/pool, /stages/pool/json, /storage, /storage/json, /storage/rdd, /storage/rdd/json, /environment, /environment/json, /executors, /executors/json, /executors/threadDump, /executors/threadDump/json, /static, /, /api, /jobs/job/kill, /stages/stage/kill.
91 2019-07-13 17:35:28 INFO YarnSchedulerBackend$YarnSchedulerEndpoint:54 - ApplicationMaster registered as NettyRpcEndpointRef(spark-client://YarnAM)
92 2019-07-13 17:35:28 INFO Client:54 - Application report for application_1563008220920_0002 (state: RUNNING)
93 2019-07-13 17:35:28 INFO Client:54 -
94 client token: N/A
95 diagnostics: N/A
96 ApplicationMaster host: 192.168.1.2
97 ApplicationMaster RPC port: 0
98 queue: default
99 start time: 1563010521752
100 final status: UNDEFINED
101 tracking URL: http://192.168.1.2:8088/proxy/application_1563008220920_0002/
102 user: yeyonghao
103 2019-07-13 17:35:28 INFO YarnClientSchedulerBackend:54 - Application application_1563008220920_0002 has started running.可以查看8088端口,看一下这个Application的信息:
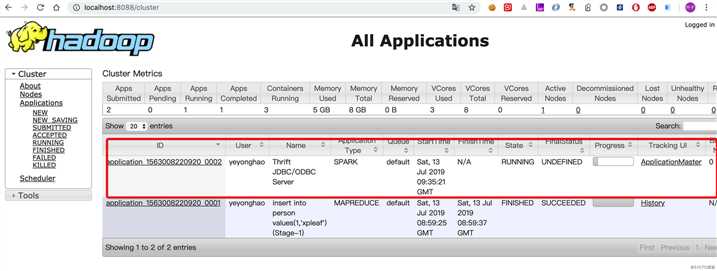
之后我们连接Thirftserver之后,所执行的操作,在Spark中会被转换为相应的Job(注意是Spark Application的Job,其又可能包含多个Stage,而Stage又会包含多个Task,对这部分不了解的同学可以先学习一下Spark Core相关内容),其资源调度都是由Yarn完成的。
这时如果访问原来的4040端口,会跳转到Yarn对该Application的监控,不过界面还是熟悉的Spark UI,如下:

之后通过beeline或者JDBC连接操作时,可以看到这里有job的运行信息:
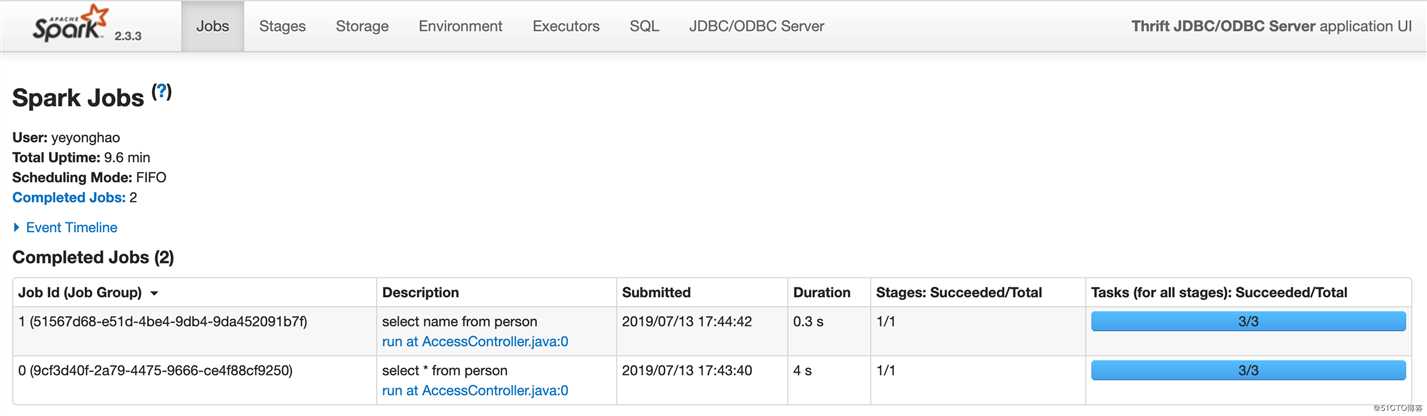
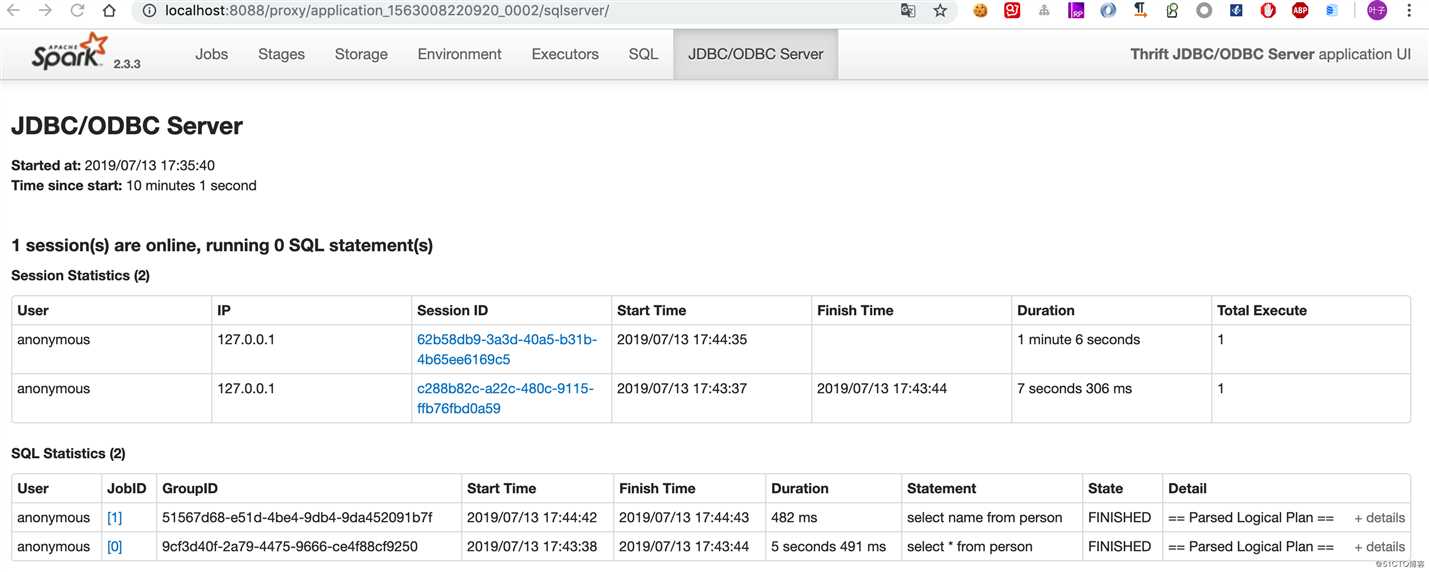
还可以看到session信息:
在生产环境中,可能更多会看到Spark SQL跟Hive的整合使用或3.3所提到的Spark Thirft JDBCServer On Yarn With Hive,不管哪一种情况,其都是出于下面的核心目的进行考虑的:
而当考虑是否需要提供JDBC的方式进行连接时,则可以考虑使用Spark Thirft JDBCServer。
除了前面提及的,其实可以使用SQL进行分析的大数据平台或者框架还有Storm SQL、Flink SQL,都是目前相当热门和流行的。
另外,还有Elasticsearch和Druid这些集数据存储和分析于一体的大数据框架,也是非常流行,同样支持SQL的查询。
根据笔者对Elasticsearch一直以来的使用和了解情况,虽然起初Elasticsearch是作为对标Solr的一个全文检索框架而诞生,但逐渐会发现随着版本的迭代更新,Elasticsearch加入了越来越多的数据分析算子,在6.0版本之后更是直接加入了SQL的数据分析查询能力,尽管目前该能力还相对薄弱,但随着时间的推移,Elasticsearch SQL也肯定会变得更强大!
Spark Thrift JDBCServer应用场景解析与实战案例
原文:https://blog.51cto.com/xpleaf/2419960