HBase是什么
最近学习了HBase,正常来说写这篇文章,应该从DB有什么缺点,HBase如何弥补DB的缺点开始讲会更有体感,但是本文这些暂时不讲,只讲HBase,把HBase相关原理和使用讲清楚,后面有一篇文章会专门讲DB与NoSql各自的优缺点以及使用场景。
HBase是谷歌Bigtable的开源版本,2006年谷歌发布《Bigtable:A Distributed Storage System For Structured Data》论文之后,Powerset公司就宣布HBase在Hadoop项目中成立,作为子项目存在。后来,在2010年左右逐渐成为Apache旗下的一个顶级项目,因此HBase名称的由来就是由于其作为Hadoop Database存在的,用于存储非结构化、半结构化的数据。
下图展示了HBase在Hadoop生态中的位置:
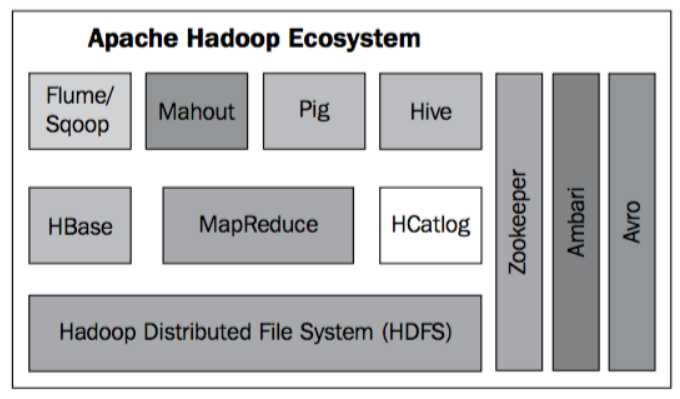
可以看到HBase建立在HDFS上,HBase内部管理的文件全部都是存储在HDFS中,同时MapReduce这个计算框架在HBase之上又提供了高性能的计算能力来处理海量数据。
HBase的特点与不足
HBase的基本特点概括大致如下:
当然事事不是完美的,HBase也存在着以下两个最大的不足:
总的来说,对于HBase需要了解以上的一些个性应该大致上就可以了,根据HBase的特点与不足,在合适的场景下选择使用HBase,接下来针对HBase的一些知识点逐一解读。
HBase的基本架构
下图是HBase的基本架构:
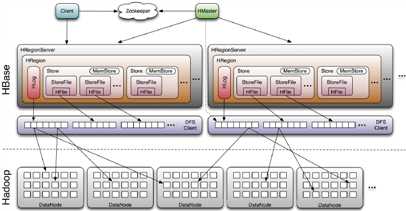
从图上可以看到,HBase中包含的一些组件如下:
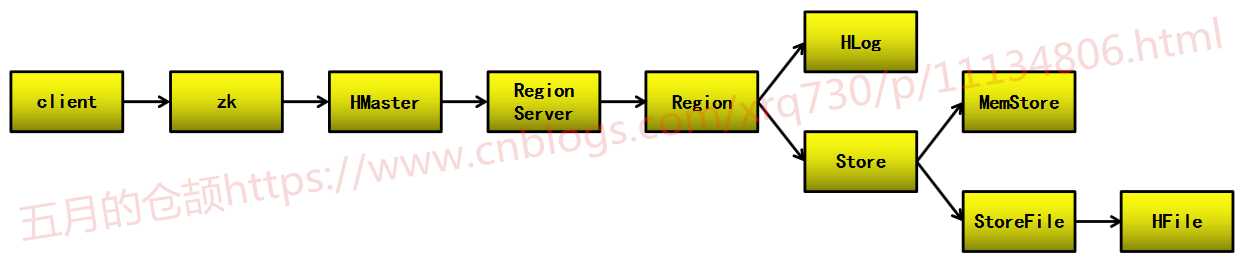
其中,Region是分布式存储和负载均衡中的最小单元,不过并不是存储的最小单元。Region由一个或者多个Store组成,每个Store保存一个列簇;每个Store又由一个memStore和0~N个StoreFile组成,StoreFile包含HFile,StoreFile只是对HFile做了轻量级封装,底层就是HFile。
介于上图元素有点多,我这边画了一张图,把HBase架构中涉及的元素的关系理了一下:
HBase的基本概念
接着看一下HBase的一些基本概念,HBase是以Table(表)组织数据的,一个Table中有着以下的一些元素:
另外一个概念就是,访问HBase Table中的行,只有三种方式:
这部分介绍的Table、RowKey、Column Family、Column等都属于逻辑概念,而上部分中的Region Server、Region、Store等都属于物理概念,下图展示了逻辑概念与物理概念之间的关系:
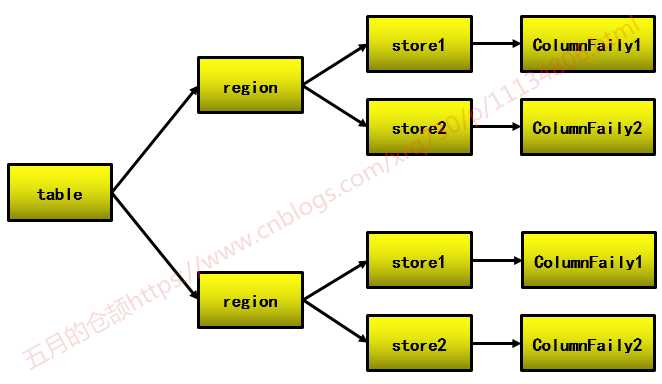
即:table和region是一对多的关系,因为table的数据可能被打在多个region中;region和columnFamily是一对多的关系,一个store对应一个columnFamily,一个region可能对应多个store。
HBase的逻辑表视图与物理表视图
接着看一下HBase中的表逻辑视图与物理视图。首先是逻辑表视图:
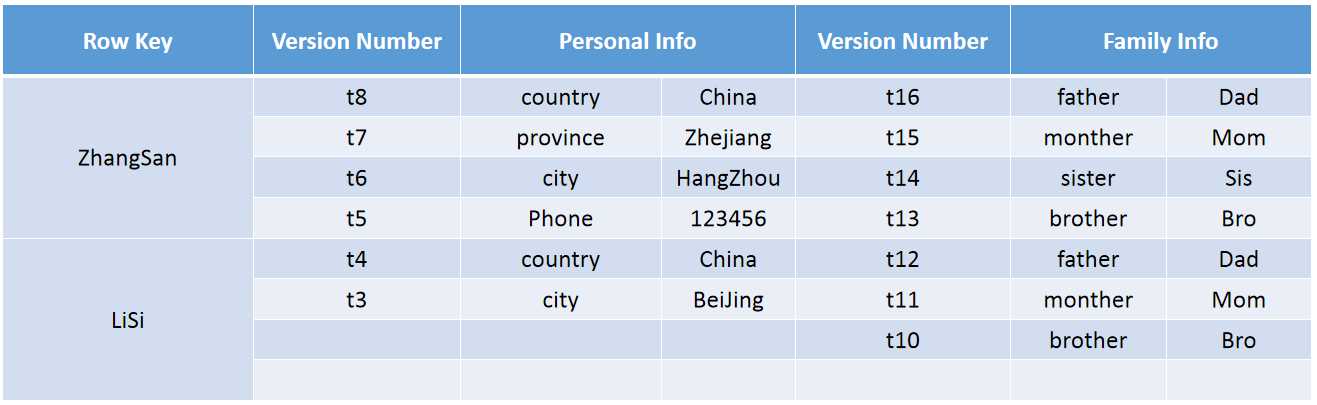
看到这里定义了2个列族,一个Personal Info、一个Family Info,对应到数据库中,相当于把两张表合并到一个一起。
从逻辑视图看,上图由ZhangSan、LiSi两行组成,但是在实际物理存储上却不是按照这种方式进行的存储:
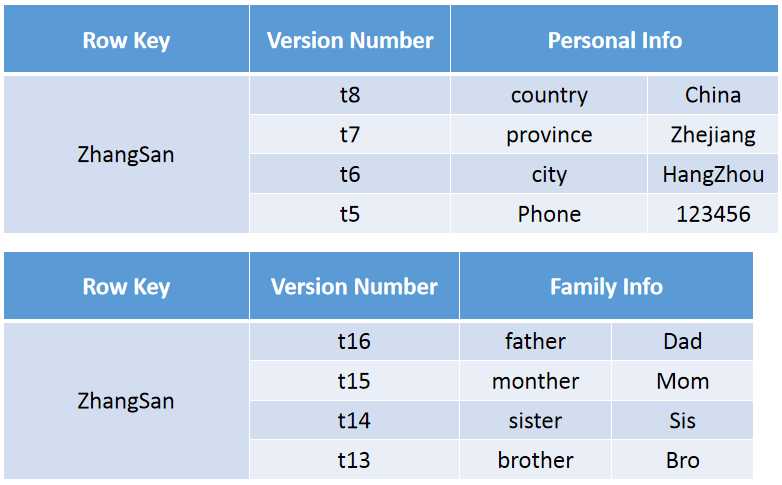
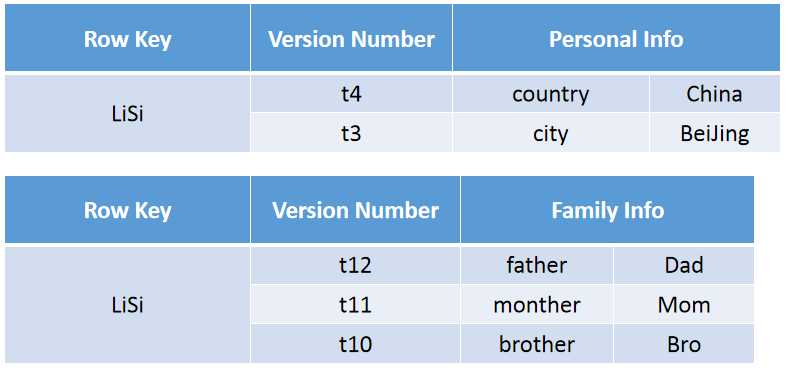
看到主要是有两点差别:
HBase的增删改查
光说不练假把式,不能光讲理论,代码也是要有的,为了方便起见,我用的是阿里云HBase,和HBase一样,只是省去了运维成本。当然虽然本人是内部员工,但是工作之外的学习是不会占用公司资源的^_^悄悄告诉大家,阿里云HBase有个福利,第一个月免费试用,想同样玩一下HBase的可以去阿里云搞一个。
首先添加一下pom依赖,用阿里云指定的HBase,使用上和原生的HBase API一模一样:
<dependency> <groupId>com.aliyun.hbase</groupId> <artifactId>alihbase-client</artifactId> <version>2.0.3</version> </dependency> <dependency> <groupId>jdk.tools</groupId> <artifactId>jdk.tools</artifactId> <version>1.8</version> <scope>system</scope> <systemPath>${JAVA_HOME}/lib/tools.jar</systemPath> </dependency>
注意一下第二个dependency,jdk.tools不添加pom文件可能会报错"Missing artifact jdk.tools:jdk.tools:jar:1.8",错误原因是tools.jar包是JDK自带的,pom.xml中以来的包隐式依赖tools.jar包,而tools.jar并未在库中,因此需要将tools.jar包添加到jdk库中。
首先写个HBaseUtil,用单例模式来写,好久没写了,顺便练习一下:
1 /** 2 * 五月的仓颉https://www.cnblogs.com/xrq730/p/11134806.html 3 */ 4 public class HBaseUtil { 5 6 private static HBaseUtil hBaseUtil; 7 8 private Configuration config = null; 9 10 private Connection connection = null; 11 12 private Map<String, Table> tableMap = new HashMap<String, Table>(); 13 14 private HBaseUtil() { 15 16 } 17 18 public static HBaseUtil getInstance() { 19 if (hBaseUtil == null) { 20 synchronized (HBaseUtil.class) { 21 if (hBaseUtil == null) { 22 hBaseUtil = new HBaseUtil(); 23 } 24 } 25 } 26 27 return hBaseUtil; 28 } 29 30 /** 31 * 初始化Configuration与Connection 32 */ 33 public void init(String zkAddress) { 34 config = HBaseConfiguration.create(); 35 config.set(HConstants.ZOOKEEPER_QUORUM, zkAddress); 36 37 try { 38 connection = ConnectionFactory.createConnection(config); 39 } catch (IOException e) { 40 e.printStackTrace(); 41 System.exit(0); 42 } 43 } 44 45 /** 46 * 创建table 47 */ 48 public void createTable(String tableName, byte[]... columnFamilies) { 49 // HBase创建表的时候必须创建指定列族 50 if (columnFamilies == null || columnFamilies.length == 0) { 51 return ; 52 } 53 54 TableDescriptorBuilder tableDescriptorBuilder = TableDescriptorBuilder.newBuilder(TableName.valueOf(tableName)); 55 for (byte[] columnFamily : columnFamilies) { 56 tableDescriptorBuilder.setColumnFamily(ColumnFamilyDescriptorBuilder.newBuilder(columnFamily).build()); 57 } 58 59 try { 60 Admin admin = connection.getAdmin(); 61 admin.createTable(tableDescriptorBuilder.build()); 62 // 这个Table连接存入内存中 63 tableMap.put(tableName, connection.getTable(TableName.valueOf(tableName))); 64 } catch (Exception e) { 65 e.printStackTrace(); 66 System.exit(0); 67 } 68 69 } 70 71 public Table getTable(String tableName) { 72 Table table = tableMap.get(tableName); 73 if (table != null) { 74 return table; 75 } 76 77 try { 78 table = connection.getTable(TableName.valueOf(tableName)); 79 if (table != null) { 80 // table对象存入内存 81 tableMap.put(tableName, table); 82 } 83 84 return table; 85 } catch (IOException e) { 86 e.printStackTrace(); 87 return null; 88 } 89 } 90 91 }
注意,HBase中的数据一切皆二进制,因此从上面代码到后面代码,字符串全部都转换成了二进制。
接着定义一个BaseHBaseUtilTest类,把一些基本的定义放在里面,保持主测试类清晰:
1 /** 2 * 五月的仓颉https://www.cnblogs.com/xrq730/p/11134806.html 3 */ 4 public class BaseHBaseUtilTest { 5 6 protected static final String TABLE_NAME = "student"; 7 8 protected static final byte[] COLUMN_FAMILY_PERSONAL_INFO = "personalInfo".getBytes(); 9 10 protected static final byte[] COLUMN_FAMILY_FAMILY_INFO = "familyInfo".getBytes(); 11 12 protected static final byte[] COLUMN_NAME = "name".getBytes(); 13 14 protected static final byte[] COLUMN_AGE = "age".getBytes(); 15 16 protected static final byte[] COLUMN_PHONE = "phone".getBytes(); 17 18 protected static final byte[] COLUMN_FATHER = "father".getBytes(); 19 20 protected static final byte[] COLUMN_MOTHER = "mother".getBytes(); 21 22 protected HBaseUtil hBaseUtil; 23 24 }
第一件事情,创建Table,注意前面说的,HBase必须Table和列族一起创建:
1 /** 2 * 五月的仓颉https://www.cnblogs.com/xrq730/p/11134806.html 3 */ 4 public class HBaseUtilTest extends BaseHBaseUtilTest { 5 6 @Before 7 public void init() { 8 hBaseUtil = HBaseUtil.getInstance(); 9 hBaseUtil.init("xxx"); 10 } 11 12 /** 13 * 创建表 14 */ 15 @Test 16 public void testCreateTable() { 17 hBaseUtil.createTable(TABLE_NAME, COLUMN_FAMILY_PERSONAL_INFO, COLUMN_FAMILY_FAMILY_INFO); 18 } 19 20 }
我自己申请的HBase,zk地址就不给大家看啦,如果同样申请了的,替换一下就好了。testCreateTable方法运行一下,就创建好了student表。接着利用put创建四条数据,多创建几条,等下scan可以测试:
1 /** 2 * 添加数据 3 */ 4 @Test 5 public void testPut() throws Exception { 6 Table table = hBaseUtil.getTable(TABLE_NAME); 7 // 用户1,用户id:12345 8 Put put1 = new Put("12345".getBytes()); 9 put1.addColumn(COLUMN_FAMILY_PERSONAL_INFO, COLUMN_NAME, "Lucy".getBytes()); 10 put1.addColumn(COLUMN_FAMILY_PERSONAL_INFO, COLUMN_AGE, "18".getBytes()); 11 put1.addColumn(COLUMN_FAMILY_PERSONAL_INFO, COLUMN_PHONE, "13511112222".getBytes()); 12 put1.addColumn(COLUMN_FAMILY_FAMILY_INFO, COLUMN_FATHER, "LucyFather".getBytes()); 13 put1.addColumn(COLUMN_FAMILY_FAMILY_INFO, COLUMN_MOTHER, "LucyMother".getBytes()); 14 // 用户2,用户id:12346 15 Put put2 = new Put("12346".getBytes()); 16 put2.addColumn(COLUMN_FAMILY_PERSONAL_INFO, COLUMN_NAME, "Lily".getBytes()); 17 put2.addColumn(COLUMN_FAMILY_PERSONAL_INFO, COLUMN_AGE, "19".getBytes()); 18 put2.addColumn(COLUMN_FAMILY_PERSONAL_INFO, COLUMN_PHONE, "13522223333".getBytes()); 19 put2.addColumn(COLUMN_FAMILY_FAMILY_INFO, COLUMN_FATHER, "LilyFather".getBytes()); 20 put2.addColumn(COLUMN_FAMILY_FAMILY_INFO, COLUMN_MOTHER, "LilyMother".getBytes()); 21 // 用户3,用户id:12347 22 Put put3 = new Put("12347".getBytes()); 23 put3.addColumn(COLUMN_FAMILY_PERSONAL_INFO, COLUMN_NAME, "James".getBytes()); 24 put3.addColumn(COLUMN_FAMILY_PERSONAL_INFO, COLUMN_AGE, "22".getBytes()); 25 put3.addColumn(COLUMN_FAMILY_FAMILY_INFO, COLUMN_FATHER, "JamesFather".getBytes()); 26 put3.addColumn(COLUMN_FAMILY_FAMILY_INFO, COLUMN_MOTHER, "JamesMother".getBytes()); 27 // 用户4,用户id:12447 28 Put put4 = new Put("12447".getBytes()); 29 put4.addColumn(COLUMN_FAMILY_PERSONAL_INFO, COLUMN_NAME, "Micheal".getBytes()); 30 put4.addColumn(COLUMN_FAMILY_PERSONAL_INFO, COLUMN_AGE, "22".getBytes()); 31 put2.addColumn(COLUMN_FAMILY_PERSONAL_INFO, COLUMN_PHONE, "13533334444".getBytes()); 32 put4.addColumn(COLUMN_FAMILY_FAMILY_INFO, COLUMN_MOTHER, "MichealMother".getBytes()); 33 34 table.put(Lists.newArrayList(put1, put2, put3, put4)); 35 }
同样的,运行一下testPut方法,四条数据就创建完毕了。注意为了提升处理效率,HBase的get、put这些API都提供的批量处理方式,这样一次提交可以提交多条数据,发起一次请求即可,不用发起请求。
接着看一下利用Get API查询数据:
1 /** 2 * 获取数据 3 */ 4 @Test 5 public void testGet() throws Exception { 6 Table table = hBaseUtil.getTable(TABLE_NAME); 7 // get1,拿到全部数据 8 Get get1 = new Get("12345".getBytes()); 9 // get2,只拿personalInfo数据 10 Get get2 = new Get("12346".getBytes()); 11 get2.addFamily(COLUMN_FAMILY_PERSONAL_INFO); 12 13 Result[] results = table.get(Lists.newArrayList(get1, get2)); 14 if (results == null || results.length == 0) { 15 return ; 16 } 17 18 for (Result result : results) { 19 printResult(result); 20 } 21 } 22 23 private void printResult(Result result) { 24 System.out.println("====================分隔符===================="); 25 printBytes(result.getValue(COLUMN_FAMILY_PERSONAL_INFO, COLUMN_NAME)); 26 printBytes(result.getValue(COLUMN_FAMILY_PERSONAL_INFO, COLUMN_AGE)); 27 printBytes(result.getValue(COLUMN_FAMILY_PERSONAL_INFO, COLUMN_PHONE)); 28 printBytes(result.getValue(COLUMN_FAMILY_FAMILY_INFO, COLUMN_FATHER)); 29 printBytes(result.getValue(COLUMN_FAMILY_FAMILY_INFO, COLUMN_MOTHER)); 30 } 31 32 private void printBytes(byte[] bytes) { 33 if (bytes != null && bytes.length != 0) { 34 System.out.println(new String(bytes)); 35 } 36 }
HBase查询数据比较灵活的是,可以查询RowKey下对应的所有数据、可以按照RowKey-Column Family的维度查询数据、可以按照RowKey-Column Family-Column的维度查询数据,也可以按照RowKey-Column Family-Column-Timestamp的维度查询数据,可以查询Timestamp区间内的数据,也可以查询RowKey-Column Family-Column下所有Timestamp数据。上面的代码执行结果为:
====================分隔符==================== Lucy 18 13511112222 LucyFather LucyMother ====================分隔符==================== Lily 19 13533334444
和我们的预期相符,即"12345"这个RowKey查询出了所有数据,"12346"这个RowKey只查了personalInfo这个列族的数据。
最后这一部分我们看一下更新,更新的API和新增的API都是一样的,都是Put:
@Test public void testUpdate() throws Exception { Table table = hBaseUtil.getTable(TABLE_NAME); // 用户1,用户id:12345 Put put = new Put("12346".getBytes()); put.addColumn(COLUMN_FAMILY_PERSONAL_INFO, COLUMN_AGE, 1, "22".getBytes()); table.put(put); }
Get看一下执行12346这条数据的值:
Lily 19 13533334444
看到12346对应的数据,原本Age是19,更新到22,依然是19,这就是一个值得注意的点了。HBase的更新其实是往Table里面新增一条记录,按照Timestamp进行排序,最新的数据在前面,每次Get的时候将第一条数据取出来。在这里我们指定的Timestamp=1,这个值落后于先前插入的Timestamp,自然就排在后面,因此读取出来的Age依然是原值19,这个细节特别注意一下。
HBase的Scan
感觉前面篇幅有点大,所以这里专门抽一个篇幅出来写一下Scan,Scan是HBase扫描数据的方式。
首先可以看一下最基本的Scan:
1 /** 2 * 扫描 3 */ 4 @Test 5 public void testScan() throws Exception { 6 Table table = hBaseUtil.getTable(TABLE_NAME); 7 Scan scan = new Scan().withStartRow("12345".getBytes(), true).withStopRow("12347".getBytes(), true); 8 9 ResultScanner rs = table.getScanner(scan); 10 if (rs != null) { 11 for (Result result : rs) { 12 printResult(result); 13 } 14 } 15 }
执行结果为:
====================分隔符==================== Lucy 19 13511112222 LucyFather LucyMother ====================分隔符==================== Lily 19 13533334444 LilyFather LilyMother ====================分隔符==================== James 22 JamesFather JamesMother
表示查询12345~12347这个范围内的所有RowKey,withStartRow的第二个参数true表示包含,如果为false那么12345这个RowKey就查不出来了。
进阶的,HBase为我们提供了带过滤器的Scan,一共有十来种,我这边只演示两种以及组合的情况,其他的查询一下HBase API文档即可,2.1版本的API文档地址为http://hbase.apache.org/2.1/apidocs/index.html。演示代码如下:
1 @Test 2 public void testScanFilter() throws Exception { 3 Table table = hBaseUtil.getTable(TABLE_NAME); 4 5 System.out.println("********************RowFilter测试********************"); 6 Scan scan0 = new Scan().withStartRow("12345".getBytes(), true); 7 scan0.setFilter(new RowFilter(CompareOperator.EQUAL, new BinaryComparator("12346".getBytes()))); 8 ResultScanner rs0 = table.getScanner(scan0); 9 printResultScanner(rs0); 10 11 System.out.println("********************PrefixFilter测试********************"); 12 Scan scan1 = new Scan().withStartRow("12345".getBytes(), true); 13 scan1.setFilter(new PrefixFilter("124".getBytes())); 14 ResultScanner rs1 = table.getScanner(scan1); 15 printResultScanner(rs1); 16 17 System.out.println("********************两种Filter同时满足测试********************"); 18 Scan scan2 = new Scan().withStartRow("12345".getBytes(), true); 19 Filter filter0 = new RowFilter(CompareOperator.EQUAL, new BinaryComparator("12447".getBytes())); 20 Filter filter1 = new PrefixFilter("124".getBytes()); 21 FilterList filterList = new FilterList(FilterList.Operator.MUST_PASS_ALL, filter0, filter1); 22 scan2.setFilter(filterList); 23 ResultScanner rs2 = table.getScanner(scan2); 24 printResultScanner(rs2); 25 }
执行结果为:
********************RowFilter测试******************** ====================分隔符==================== Lily 19 13533334444 LilyFather LilyMother ********************PrefixFilter测试******************** ====================分隔符==================== Micheal 22 MichealMother ********************两种Filter同时满足测试******************** ====================分隔符==================== Micheal 22 MichealMother
总的来说,HBase本质上是KV型NoSql,根据Key查询Value是最高效的,Scan这个API还是慎用,范围里面的数据量小倒无所谓,一旦RowKey设计不合理,StartRow和EndRow没有指定好,可能会造成大范围的扫描,降低HBase整体能力。
HBase和KV型缓存的区别
看了上面的代码演示,不知道大家有没有和我一开始有一样的疑问:HBase看上去也是K-V形式的,那么它和支持KV型数据的缓存(例如Redis、MemCache、Tair)有什么区别?
我用一张表格总结一下二者的区别:
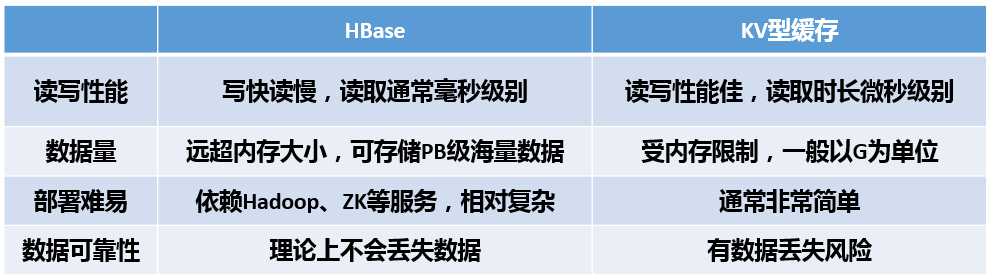
总的来说,同样作为数据库的NoSql替代方案,HBase更加适合用于海量数据的持久化场景,KV型缓存更加适合用于对数据的高性能读写上。
HBase的Region分裂及会导致的热点问题
经典问题,首先看一下什么是Region分裂,只把Region分裂讲清楚,不讲具体Region分裂的实现方式,理由也很简单,Region分裂细节学得再清楚,对工作中的帮助也不大,没必要太过于追根究底。
Region分裂是HBase能够拥有良好扩张性的最重要因素之一,也必然是所有分布式系统追求无限扩展性的一副良药。通过前面的部分我们知道HBase的数据以行为单位存储在HBase表中,HBase表按照多行被分割为多个Region,这个Region分布在HBase集群中,并且由Region Server进程负责讲这些Region提供给Client访问。一个Region中,RowKey是一个连续的范围,也就是说表中的记录在Region中是按照startKey到endKey的范围为RowKey进行排序存储的。通常一个表由多个Region构成,这些Region分布在多个Region Server上,也就是说,Region是在Region Server中插入和查询数据时负载均衡的物理机制。一张HBase表在刚刚创建的时候默认只有一个Region,所以关于这张表的请求都被路由到同一个Region Server,无论集群中有多少Region Server,而一旦某个Region的大小达到一定值,就会自动分裂为两个Region,这也就是为什么HBase表在刚刚创建的阶段不能充分利用整个集群吞吐量的原因。
在HBase管理界面可以查看每个Region,startKey与endKey的范围,例如(图片来自网络):
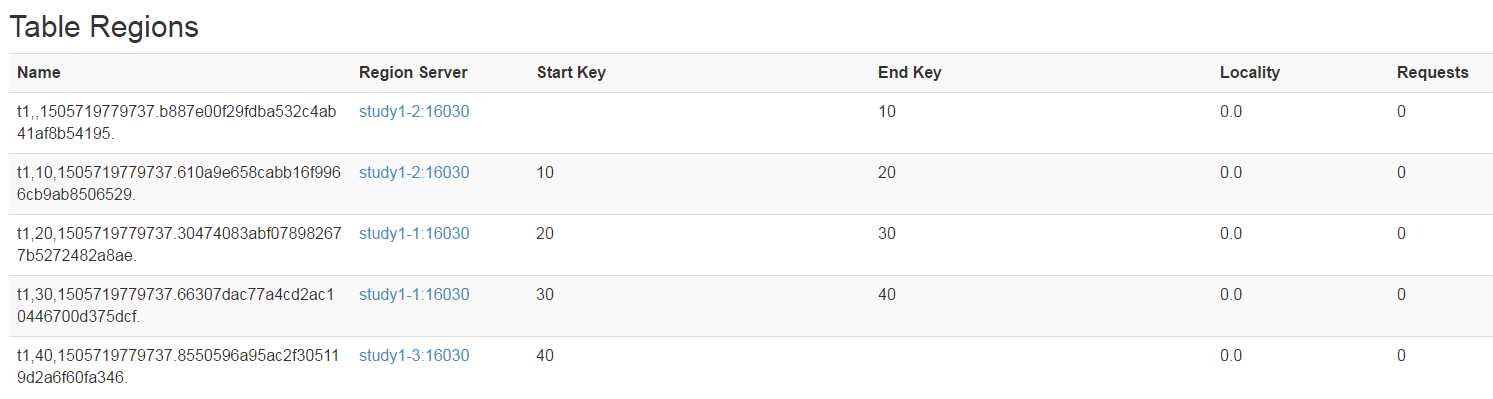
这里特别注意一个点,RowKey是按照Key的字符自然顺序进行排序的,因此RowKey=9的Key,会落在最后一个Region Server中而不是第一个Region Server中。
那么什么是热点问题应该也很好理解了:
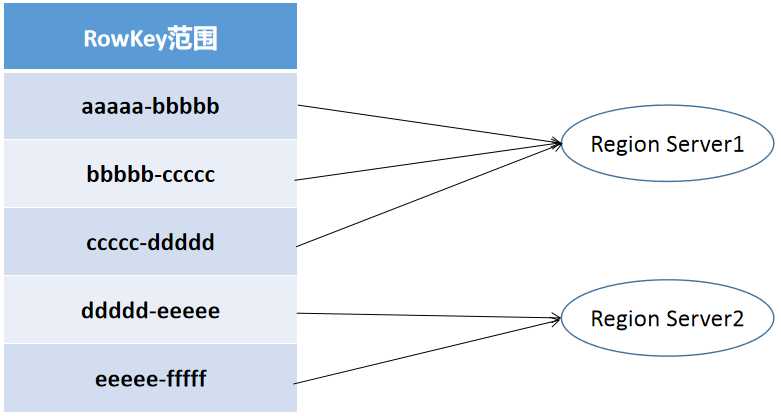
虽然HBase的单机读写性能强劲,但是当集群中成千上万的请求RowKey都落在aaaaa-ddddd之间,那么这成千上万请求最终落到Region Server1这台服务器上,一旦超出服务器自身承受能力,那么必然导致服务器不可用甚至宕机。因此我们说设计RowKey的时候千万把时间戳或者id自增的方式作为RowKey方案就是这个道理,时间戳或者id自增的方式,虽然最终可以让RowKey落到不同的Region中,但是在当下或者当下往后的一段时间内,RowKey一定是会落到同一个Region中的,数据热点问题将严重影响HBase集群能力。
解决热点问题通常有两个方案,最初级的方案是设置预分区,即在Table创建的时候就先设置几个Region,为每个Region划分不同的startKey与endKey,但这么做有以下两个缺点:
但是无论如何,设置预分区依然是一种解决热点问题的方案。
第二个解决方案是一劳永逸的解决方案也是使用HBase最核心的一个点:合理设计RowKey。即让RowKey均匀分布在Region中,大致有以下几个方案可供参考:
无论如何,还是那句话,合理设计RowKey是HBase使用的核心。
WAL机制
最后讲一下前面提到的WAL机制,WAL的全称为Write Ahead Log,它是HBase的RegionServer在处理数据插入和删除的过程中用来记录操作内容的一种日志,是用来做灾难恢复的。
其实WAL并不是什么新鲜思想,在分布式领域很常见:
其核心都是,变更数据前先写磁盘日志文件,在系统发生异常的时候,重放日志文件对数据进行恢复,HBase的WAL机制也是一样的思想,数据变更步骤为:
因为有了HLog,即使在MemStore中的数据还没有flush到hdfs的时候系统发生了宕机或者重启,数据都不会出现丢失。
原文:https://www.cnblogs.com/xrq730/p/11134806.html