OCR,即Optical Character Recognition,光学字符识别,是指通过扫描字符,然后通过其形状将其翻译成电子文本的过程。对于图形验证码来说,它们都是一些不规则的字符,这些字符确实是由字符稍加扭曲变换得到的内容。
pip install pytesseract
继续安装tesseract.exe
tesseract下载地址:https://digi.bib.uni-mannheim.de/tesseract/
为了在全局使用方便,比如安装路径为C:\Program Files (x86)\Tesseract-OCR\Tesseract-OCR,将该路径添加到环境变量的path中.
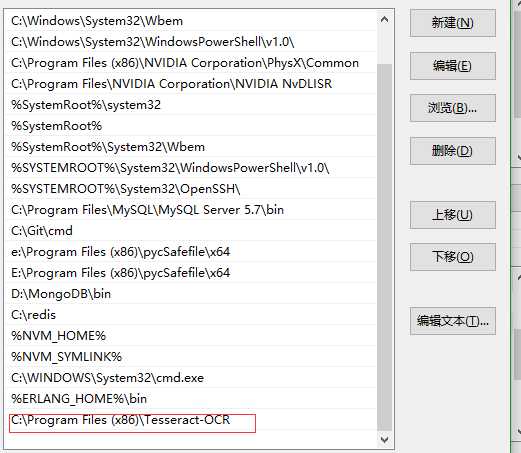
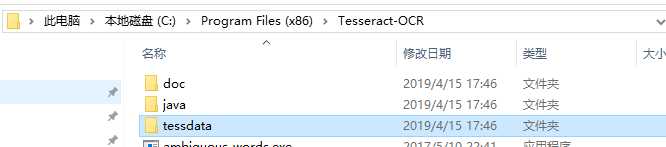
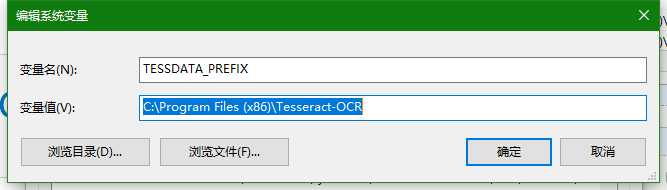
官网 :http://tesseract.gg/
from PIL import Image import pytesseract
#Image去除噪点 img=Image.open(‘tim.png‘) text=pytesseract.image_to_string(img) print(text)
结果
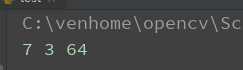

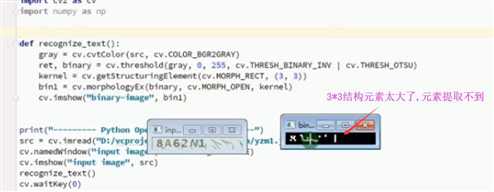
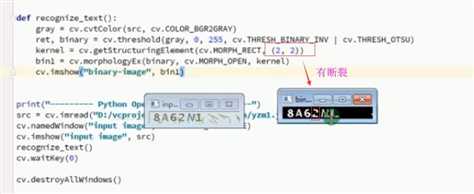
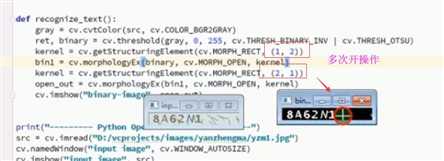
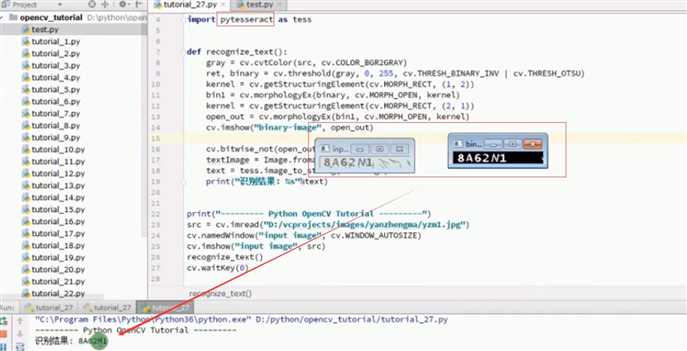
import cv2 as cv from PIL import Image import pytesseract def recognize_text(src): gray=cv.cvtColor(src,cv.COLOR_BGR2GRAY) blurer=cv.GaussianBlur(gray,(9,9),0) ret,binary=cv.threshold(blurer,0,255,cv.THRESH_BINARY_INV|cv.THRESH_OTSU) res=cv.bitwise_not(binary) cv.imshow(‘res‘, res) #开操作 kernel=cv.getStructuringElement(cv.MORPH_RECT,(2,2)) bin=cv.morphologyEx(binary,cv.MORPH_OPEN,kernel) bin2=cv.morphologyEx(bin,cv.MORPH_CLOSE,kernel) cv.imshow(‘bin‘,bin2) textImage=Image.fromarray(bin2) word=pytesseract.image_to_string(textImage) print(‘识别出来:‘,word) src=cv.imread(‘./numcode.jpg‘) cv.imshow(‘before‘,src) recognize_text(src) cv.waitKey(0) cv.destroyAllWindows()
结果

学习的素材


原文:https://www.cnblogs.com/angle6-liu/p/10712910.html