MySQL查询优化
Mysql存储引擎
最常使用的2种存储引擎:
- Myisam是Mysql的默认存储引擎,当create创建新表时,未指定新表的存储引擎时,默认使用Myisam。
- 每个MyISAM在磁盘上存储成三个文件。文件名都和表名相同,扩展名分别是.frm(存储表定义)、.MYD (MYData,存储数据)、.MYI (MYIndex,存储索引)。数据文件和索引文件可以放置在不同的目录,获得更快的速度。
- InnoDB存储引擎提供了具有提交、回滚和崩溃恢复能力的事务安全。但是对比Myisam的存储引擎,InnoDB写的处理效率差一些并且会占用更多的磁盘空间以保留数据和索引。
- 聚簇索引(innodb)和非聚簇索引(myisam)。
- 页分裂:聚簇索引乱序插入造成页分裂现象,因为插入的时候需要找位置
- innodb除主键外的索引都保存了一个到主键的引用(也就是说,通过普通索引查找,也需要回行到主键索引树上查找数据)
- MyISAM:默认的MySQL插件式存储引擎,它是在Web、数据仓储和其他应用环境下最常使用的存储引擎之一
- InnoDB:用于事务处理应用程序,具有众多特性,事务支持。
选择数据类型
- MyISAM数据表,最好使用固定长度的数据列代替可变长度的数据列。
- 对于InnoDB数据表,内部的行存储格式没有区分固定长度和可变长度列。
- mysql的字符集包括字符集(CHARACTER)和校对规则(COLLATION)两个概念。字符集是用来定义mysql存储字符串的方式,校对规则则是定义了比较字符串的方式。字符集和校对规则是一对多的关系。
设计索引
- 使用惟一索引。考虑到数据库某列中值的分布。不存在重复的值时,索引的效果最好,而且某列数据重复的过多,区分小,其索引效果最差。
- 使用短索引。如果对字符串的列进行索引,mysql字符串截取,substring、right、left,应该指定一个前缀长度,这样可以通过索引使用效率。
- 利用最左前缀。在创建一个n 列的索引时,实际是创建了MySQL可利用的n 个索引。多列索引可起几个索引的作用,因为可利用索引中最左边的列集来匹配行。这样的列集称为最左前缀。
- 不要过多索引。不要以为索引越多越好,每个额外的索引都要占用额外的磁盘空间,并降低写的操作性能。
btree索引与hash索引
- hash索引还有一些其它特征:它们只用于使用=或<=>操作符的等式比较(但很快)。
- 对于BTREE索引,当使用>、<、>=、<=、BETWEEN、!=或者<>,或者LIKE ‘pattern‘(其中 ‘pattern‘不以通配符开始)操作符时,关键元素与常量值的比较关系对应一个范围条件。
- 索引的左前缀原则
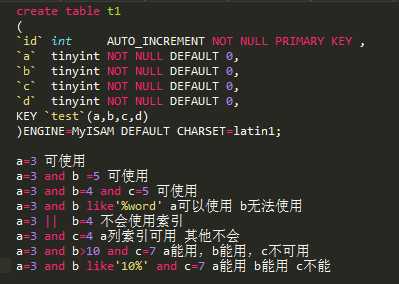
优化SQL
- 通过SHOW STATUS可以提供服务器状态信息
以下几个参数对Myisam和Innodb存储引擎都计数:
- Com_select 执行select操作的次数,一次查询只累加1;
- Com_insert 执行insert操作的次数,对于批量插入的insert操作,只累加一次;
- Com_update 执行update操作的次数;
- Com_delete 执行delete操作的次数;
以下几个参数是针对Innodb存储引擎计数的:
- Innodb_rows_read select查询返回的行数;
- Innodb_rows_inserted执行Insert操作插入的行数;
- Innodb_rows_updated 执行update操作更新的行数;
- Innodb_rows_deleted 执行delete操作删除的行数;
Slow_queries 慢查询的次数
show status like ‘%tmp%‘; 查看临时表的创建
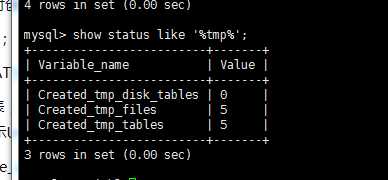
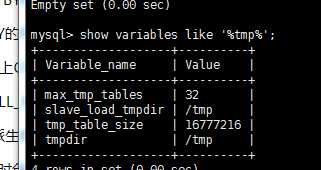
show global variables like ‘%tmp%‘;
show global variables like ‘%table_size%‘;
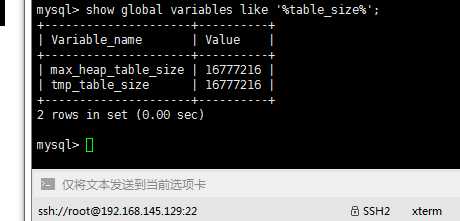
- MySQL内部参数tmp_table_size表示内部的临时表的最大值,其实生效的是tmp_table_size和max_heap_table_size这两个值之间的最小的那个值。当创建的临时表超过这个值(或者max_heap_table_size)时,MySQL将会在磁盘上创建临时表。
- 当创建内部临时表(会增加Created_tmp_tables状态变量。在磁盘上创建临时表,会增加Created_tmp_disk_tables状态。
- 强制使用某个索引

通过EXPLAIN分析SQL
23. 通过以上步骤查询到效率低的SQL后,我们可以通过explain 获取MySQL如何执行SELECT语句。
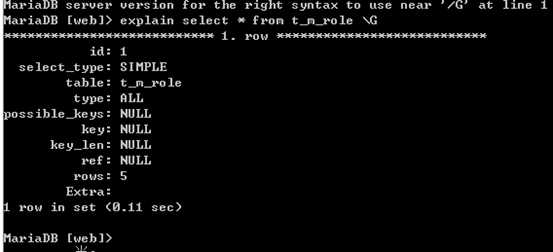


id:查询语句的id
select_type: 简单查询:simple 复合查询:subquery(非from子查询) ,derived(from型子查询), (union, union result:结果的那次)
table:查询的表,derived(from子查询的表),null
type:搜索的数据范围:
ALL(全表扫描)<
index(全索引扫描)<
range(范围索引查找)<
ref(通过索引列,可以直接饮用某些数据行)
<eq_ref(通过索引列,引用某一行数据)
<const system null 精准查询
pssible_keys:可能使用的key
key:使用的key
key_len:使用的key长度
ref:连接查询时,表之间的字段引用关系
rows:可能扫描的行数
Extra:描述
using filesort:文件排序<
using temporary:使用了临时表<
using where:使用索引还不能完全定位,还需要where判断一下<
index:使用到了索引覆盖
24. 索引覆盖:查询数据不进行回行,提高查询速度。
25. 优化group by查询
Group by中只有最左前缀列,没有其他列
只支持max和min聚合函数等,要聚合的列必须是group by中列所在的索引
使用group的时候 会自动进行排序
指定ORDER BY NULL禁止排序


26. 优化order by
给排序字段建立索引,并所取字段在索引中

多字段排序,要遵循索引的左前缀原则
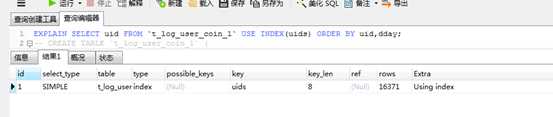
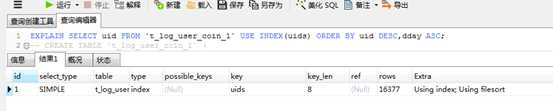
order by中的升降序和索引中的默认升降不一致,无法使用索引排序
MySQL查询优化
原文:https://www.cnblogs.com/yehuisir/p/11191382.html