大数据的特点:
1、Volume 大量
数据大量 个人硬盘TB级 大企业数据量接近EB级
2、Velocity 高速
效率决定一切(当然还有准确)
3、Variety 多样
结构化数据(数据库、文本)
非结构化数据(音频、视频)
4、Value 低价值密度
数据越多 价值密度越低
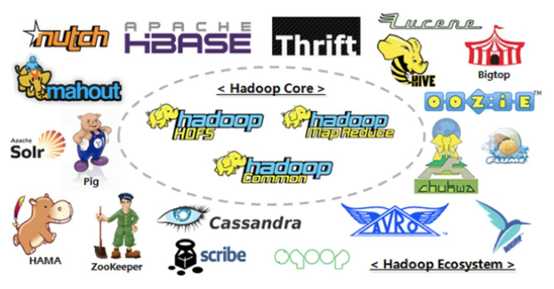
hadoop的生态圈
hadoop的来源:
来自于Google个三篇论文(GFS、MapReduce、BigTable)衍生出HDFS、MR、Hbase
Hadoop三大发行版本:Apache Cloudera Hortonworks
新手选Apache入门
大型企业用Cloudera
第三个文档较好
1)高可靠性:Hadoop底层维护多个数据副本,所以即使Hadoop某个计算元素或存储出现故障,也不会导致数据的丢失。
2)高扩展性:在集群间分配任务数据,可方便的扩展数以千计的节点。
3)高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。
4)高容错性:能够自动将失败的任务重新分配。
Hadoop的组成
MapReduce、Yarn、HDFS
1.HDFS:
NameNode:储存文件属性信息的元数据 是HDFS的老大管理其他的DataNode
DataNode:在本地文件系统存储文件块数据以及数据校验和
Secondary NameNode:辅助NameNode,是一段时间元数据的快照
2.YARN:
ResourceManager:是yarn的老大主要的是资源的分配合处理请求,资源调度分配
NodeManager:单个节点上的资源管理,处理来自RM上的命令处理ApplicationMaster的命令
ApplicationMaster:数据切分分配给内部任务
Container:封装了各种资源以及环境变量,启动命令等任务运行相关的信息
3.MApReduce:
Map:处理数据
Reduce:对Map阶段的结果汇总
原文:https://www.cnblogs.com/suyz/p/11192314.html