# 创建项目 scrapy startproject downimg
# settings.py 67行 ITEM_PIPELINES = { #‘downimg.pipelines.DownimgPipeline‘: 300, ‘scrapy.pipelines.images.ImagesPipeline‘: 1 } MAGES_STORE = ‘images‘ # 存储图片文件位置 IMAGES_URLS_FIELD = ‘src‘ # 下载URL上面的SRC
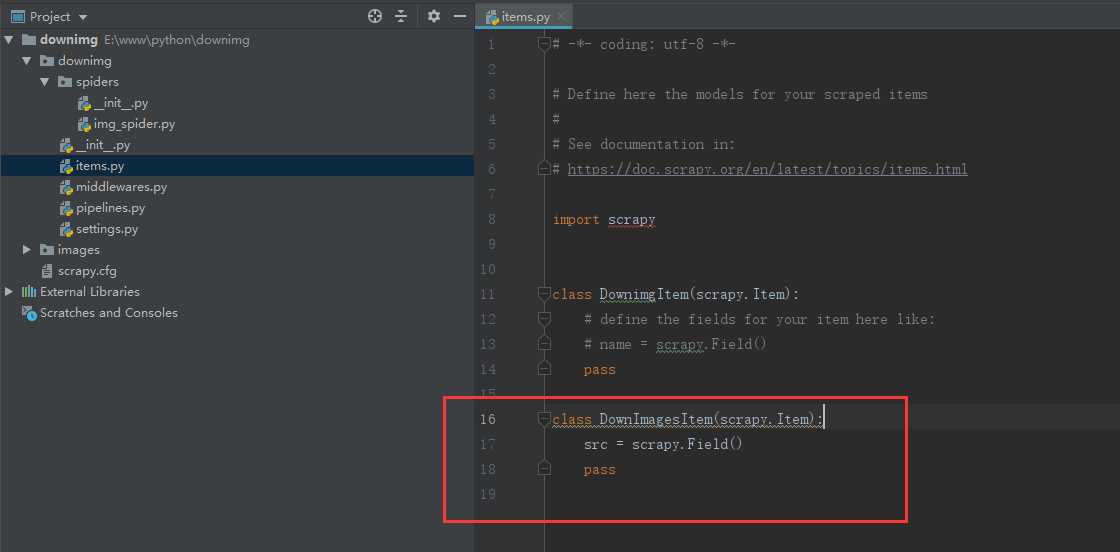
# items.py 新增 class DownImagesItem(scrapy.Item): src = scrapy.Field() pass
# 创建爬虫文件 spiders/img_spider.py import scrapy from ..items import DownImagesItem class ImgSpider(scrapy.Spider): # 爬虫名称 name = ‘img‘ # 指定域名 爬虫不会访问其他域名 allowed_domains = [‘ivsky.com‘] # 需要采集的页面 start_urls = [‘https://www.ivsky.com/tupian/tiankong_t811/‘] def parse(self, response): # 获取列表全部图片 img_url = response.css("ul.pli li a img::attr(src)").getall() for img in img_url: item = DownImagesItem() # 拼接完整URL放入item item[‘src‘] = [‘https:‘+img] yield item next_url = response.css("div.pagelist a.page-next::attr(href)").get() if next_url: # 拼接完成下一页路径 url = ‘https://www.ivsky.com‘+next_url yield scrapy.Request(url=url, callback=self.parse)
# 执行爬虫 # scrapy.cfg 目录下执行 scrapy crawl img


原文:https://www.cnblogs.com/phper8/p/11215635.html