In Week 6, you will be learning about systematically improving your learning algorithm. The videos for this week will teach you how to tell when a learning algorithm is doing poorly, and describe the ‘best practices‘ for how to ‘debug‘ your learning algorithm and go about improving its performance.
如何改进算法?
但是,选择一种有效的方法是困难的
所以,我们需要评估一个机器学习算法的性能的方法
Machine learning diagnostic
定义:

如何评估假设函数以及避免过拟合和欠拟合?
如何评价假设函数?
将数据分割:按照某个比例
1.常用训练集
2.测试集
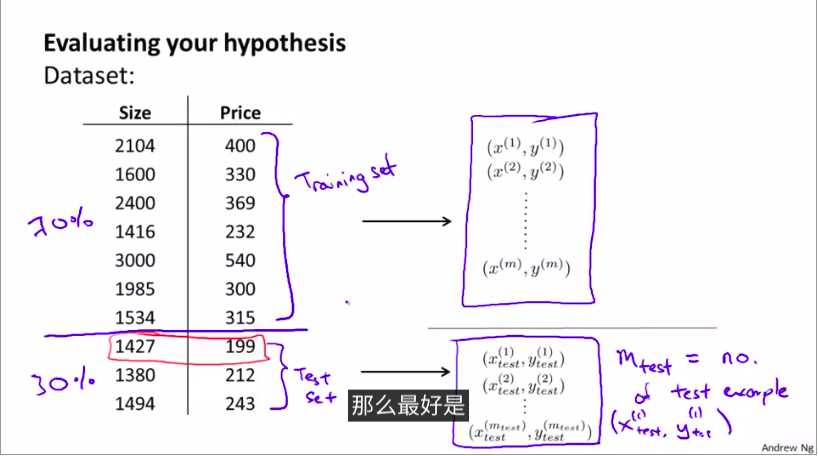
基本步骤:

(分类问题):(逻辑回归)
差不多,用测试集评估。
问题是:如何计算error(0/1)?
其实和之前差不多,要定义决策界限

用0/1错分率来定义error
总结:

模型选择问题//训练集//验证集//测试集
模型选择:

还需要选择一个参数d. 也就是最高次数。
可以逐个选择,然后逐个算出测试集的误差函数。
然后观察哪个最小。
而且,这样选出的模型,可能仅仅是可以很好的拟合测试集,但是其他的说不定。所以,我们仅仅是用测试集来拟合样本。不公平!
所以,我们可以用 交叉验证集!cross validation set
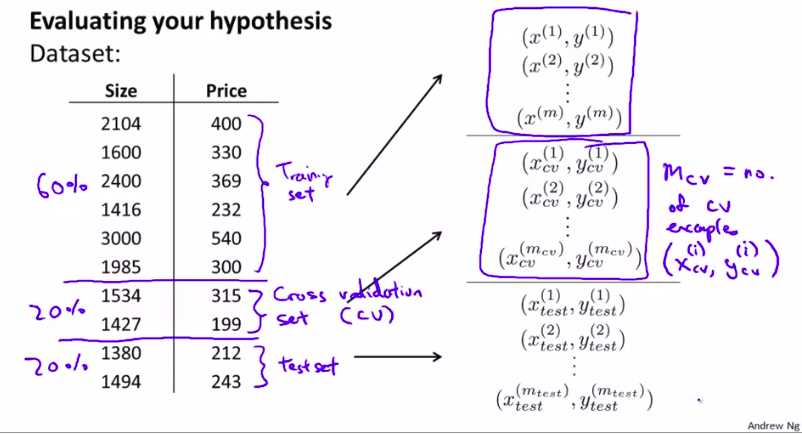
现在把数据集分为3个部分:

就是说,验证是最好的模型,可以用交叉验证集来检验!然后,就没有和测试集进行拟合,回避了测试集的嫌疑

一般的比例为:

如何判断一个算法,是和方差有问题还是和偏差有问题?
用图像来直观理解
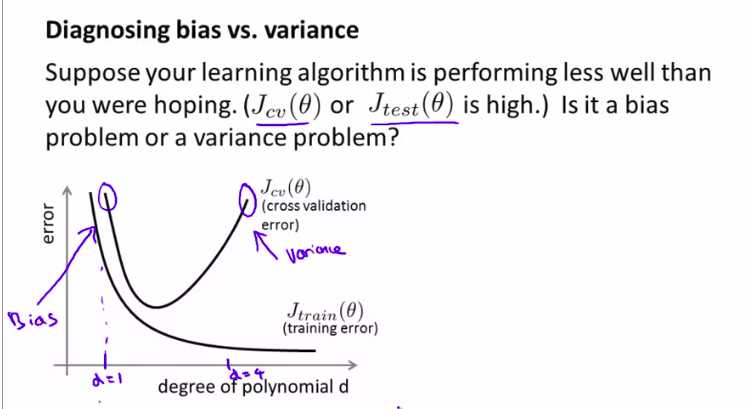
注意理解bias error 和 variance error
也就是,区分过拟合和欠拟合的情况

当然,这两种情况都是不好的!
更深入地 探讨一下偏差和方差的问题 讨论一下两者之间 是如何相互影响的 以及和算法的正则化之间的相互关系
首先,我们来看一下正则项:
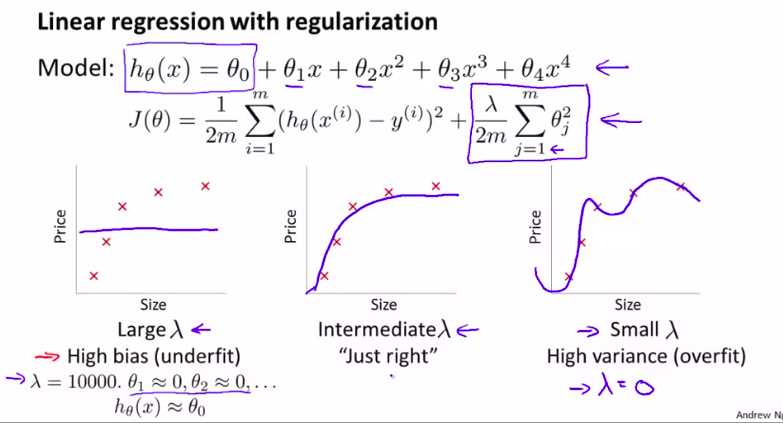
当然,我们需要先用交叉验证集上进行选择模型
再试着用哪一个正则项更好。来得到最小的J_train_
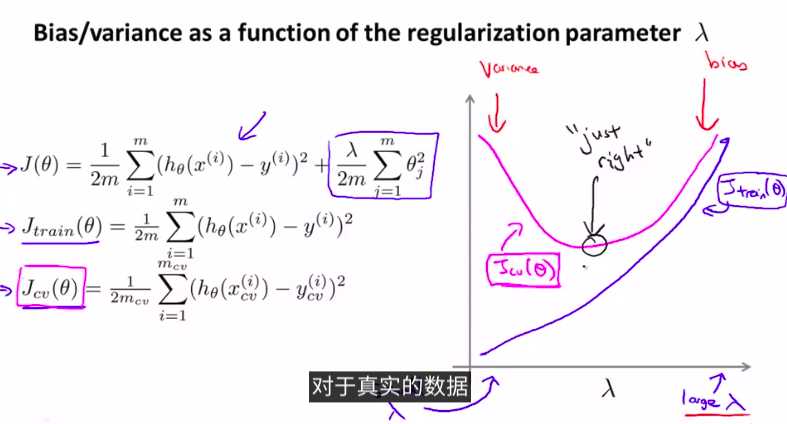
如图:
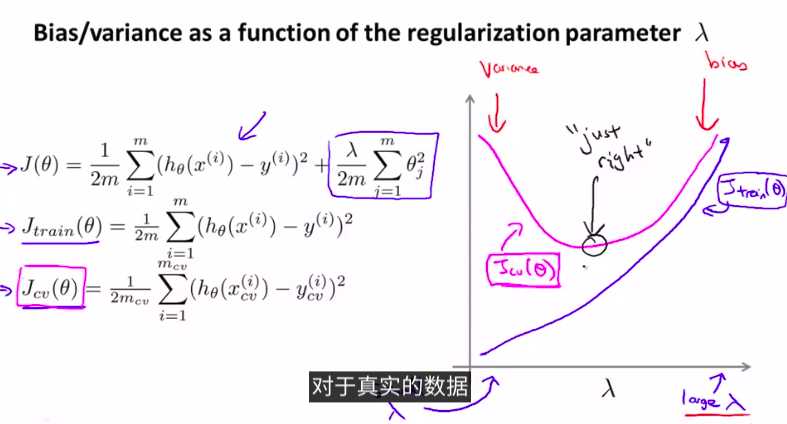
总结步骤:

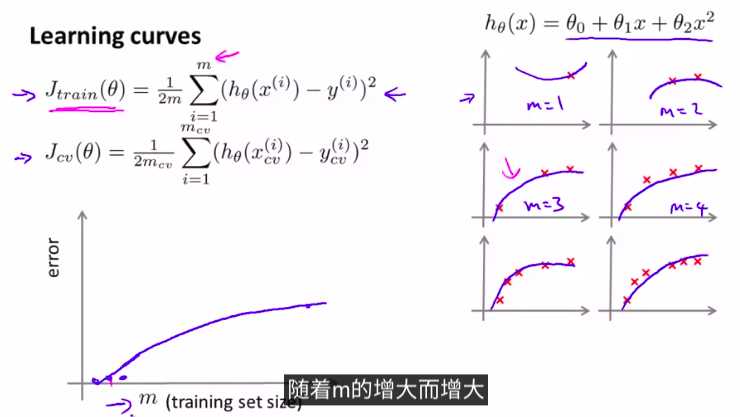
一种模型,当训练集的样本增加的时候,error是越来越大的
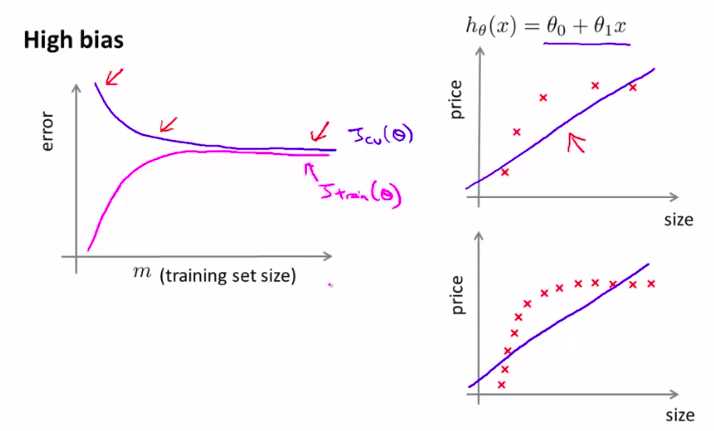
结论:

所以,如果模型是高偏差,再多的样本来拟合,也不太会管用
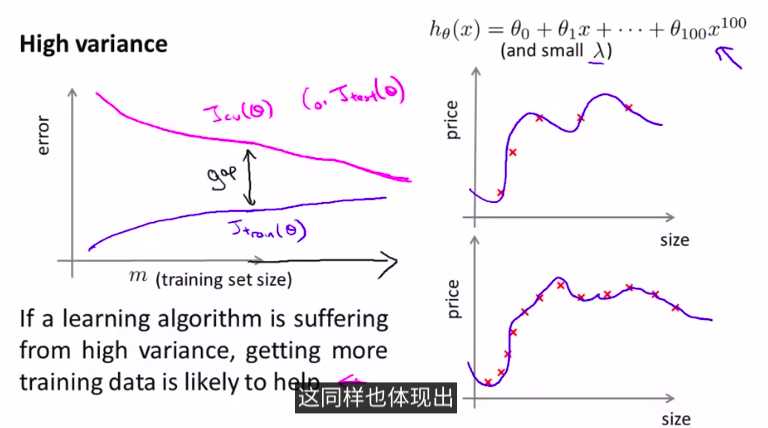
这种情况下,使用更多的样本是有帮助的
总结:
画出曲线,可以更容易看出是高偏差还是高方差的问题,然后来选择改进算法




当我们发现方差或者偏差出了问题,我们应该怎么做?

如何和神经网络联系/
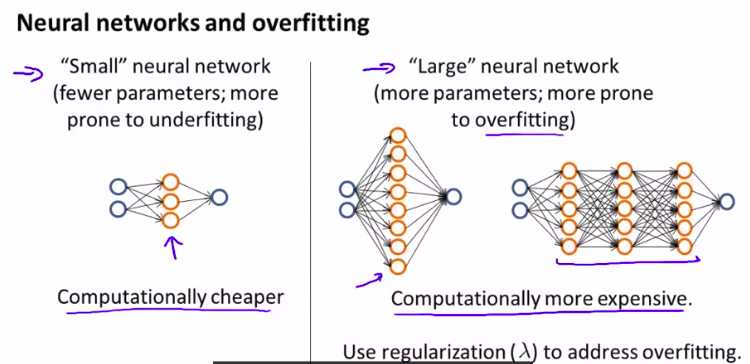
如何选择hiding layer?
想用多个隐藏层。可以尝试着数据分割。
总结:
Our decision process can be broken down as follows:
Getting more training examples: Fixes high variance
Trying smaller sets of features: Fixes high variance
Adding features: Fixes high bias
Adding polynomial features: Fixes high bias
Decreasing λ: Fixes high bias
Increasing λ: Fixes high variance.
Diagnosing Neural Networks
Using a single hidden layer is a good starting default. You can train your neural network on a number of hidden layers using your cross validation set. You can then select the one that performs best.
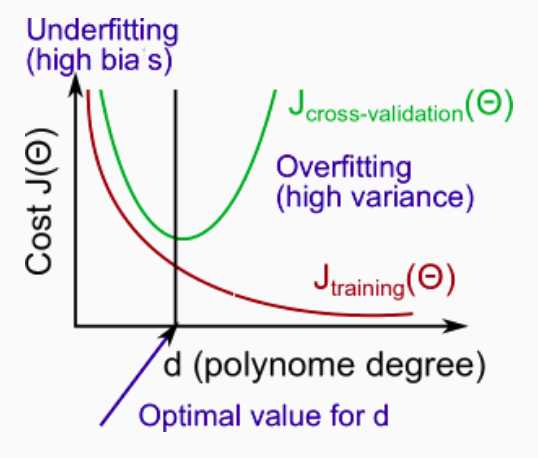
Model Complexity Effects:
原文:https://www.cnblogs.com/orangestar/p/11219391.html