利用SIFT特征进行简单的花朵识别
现在得到的是所有图像的128维特征,每个图像的特征点数目还不一定相同(大多有差异)。现在要做的是构建一个描述图像的特征向量,也就是将每一张图像的特征点转换为特征向量。这儿用到了词袋模型,词袋模型源自文本处理,在这儿用在图像上,本质上是一样的。词袋的本质就是用一个袋子将所有维度的特征装起来,在这儿,词袋模型的维度需要我们手动指定,这个维度也就确定了视觉单词的聚类中心数。
SIFT提取每幅图像的特征点:
import csv
import os
from sklearn.cluster import KMeans
import cv2
import numpy as np
def knn_detect(file_list,cluster_nums, randomState = None):
content = []
input_x = []
labels=[]
features = []
count = 0
csv_file = csv.reader(open(file_list,'r'))
for line in csv_file:
if(line[2] !='label'):
subroot = 'F:\\train\\g' + str(line[2])
filename =os.path.join(subroot, line[1])
sift = cv2.xfeatures2d.SIFT_create(200)
img = cv2.imdecode(np.fromfile(filename,dtype=np.uint8),-1)
if img is not None:
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
kpG, desG = sift.detectAndCompute(gray, None)#关键点描述符
if desG is None:
continue
print(count)
count+=1
ll = np.array(line[2]).flatten()
labels.append(ll)
features.append(desG)
input_x.extend(desG)
print(len(input_x))
return features,labels,input_x
des_list = []
labelG = []
input_x1 = []
des_list,labelG,input_x1 = knn_detect('E:\\py\\train.csv',50)
festures_test = []
labels_test = []
input_x2 = []
features_test,labels_test,input_x2 = knn_detect('E:\\py\\test.csv',50)结果截图:

保存中间变量:
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import pickle
output = open('input_x2.pkl', 'wb')
pickle.dump(input_x2, output)
output.close()
output = open('features_test.pkl', 'wb')
pickle.dump(features_test, output)
output.close()
output = open('labels_test.pkl', 'wb')
pickle.dump(labels_test, output)
output.close()
output = open('input_x22.pkl', 'wb')
pickle.dump(input_x2, output,protocol=2)
output.close()将图像特征点映射到视觉单词上,得到图像特征:
df=open('input_x2.pkl','rb')#注意此处是rb
#此处使用的是load(目标文件)
input_x1=pickle.load(df)
df.close()
kmeans = KMeans(n_clusters = 50, n_jobs =4,random_state = None).fit(input_x1)
centers = kmeans.cluster_centers_将图像特征点映射到视觉单词上,得到图像的特征向量:
def des2feature(des,num_words,centures):
'''
des:单幅图像的SIFT特征描述
num_words:视觉单词数/聚类中心数
centures:聚类中心坐标 num_words*128
return: feature vector 1*num_words
'''
img_feature_vec=np.zeros((1,num_words),'float32')
for i in range(des.shape[0]):
feature_k_rows=np.ones((num_words,128),'float32')
feature=des[i]
feature_k_rows=feature_k_rows*feature
feature_k_rows=np.sum((feature_k_rows-centures)**2,1)
index=np.argmax(feature_k_rows)
img_feature_vec[0][index]+=1
return img_feature_vec
def get_all_features(des_list,num_words):
# 获取所有图片的特征向量
allvec=np.zeros((len(des_list),num_words),'float32')
for i in range(len(des_list)):
if des_list[i].any()!=None:
allvec[i]=des2feature(centures=centers,des=des_list[i],num_words=num_words)
return allvec
df=open('des_list.pkl','rb')#注意此处是rb
#此处使用的是load(目标文件)
des_list=pickle.load(df)
df.close()
a =get_all_features(des_list,50)
print(len(a))
output = open('特征向量.pkl', 'wb')
pickle.dump(a, output)
output.close()svm训练,查看准确率:
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(a)
X_test = sc.fit_transform(b)
from sklearn.svm import SVC
classifier = SVC( random_state = 0)
classifier.fit(X_train,labelG)
y_pred = classifier.predict(X_test)
print(classifier.score(X_test,labels_test))
from sklearn.metrics import classification_report
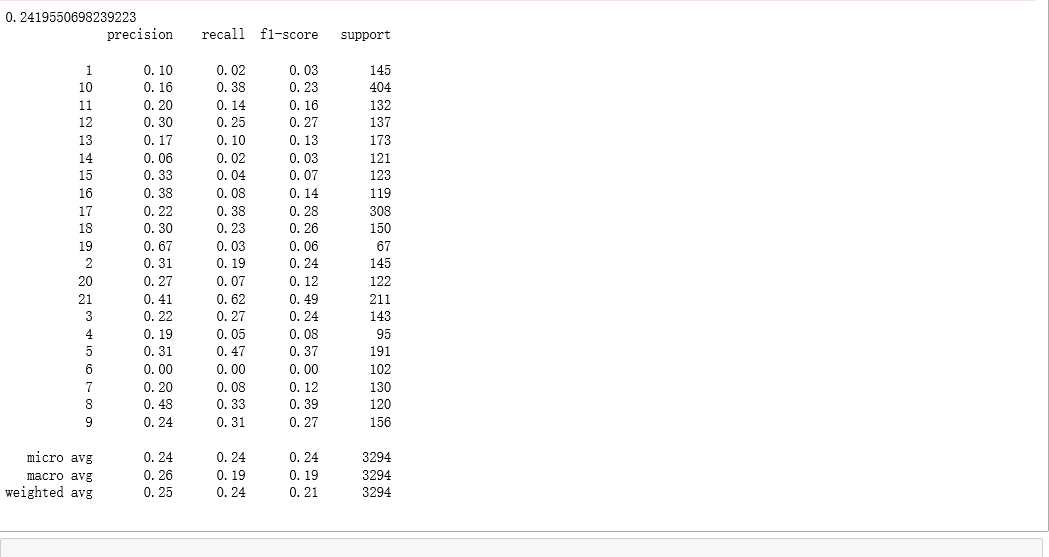
print(classification_report(labels_test,y_pred))结果截图:
原文:https://www.cnblogs.com/gzyc/p/11221963.html