在word2vec原理中讲到如果每个词向量由300个元素组成,并且一个单词表中包含了10000个单词。回想神经网络中有两个权重矩阵——一个在隐藏层,一个在输出层。这两层都具有300 x 10000 = 3,000,000个权重!使用梯度下降法在这种巨大的神经网络下面进行训练是很慢的。并且可能更糟糕的是,你需要大量的训练数据来调整这些权重来避免过拟合。上百万的权重乘以上十亿的训练样本,意味着这个模型将会是一个超级大怪兽!这时就要采用负样本和层级softmax来优化。
word2vec的C代码中使用了一个公式来计算给出特定单词时候单词表中的单词出现的概率。
wi代表单词,z(wi)代表在总的语料库中的一个概率。比如说,如果单词”peanut”在1十亿的单词库中出现了1000次,那么z(‘peanut’) = 1e-6。
这也是代码中名为“采样”的一个来控制重采样频率的一个参数,它的默认值为0.001。更小的“采样”参数意味着单词被保存下来的几率更小。
1. 负样本
训练一个神经网络意味着使用一个训练样本就要稍微调整一下所有的神经网络权重,这样才能够确保预测训练样本更加精确。换句话说,每个训练样本都会改变神经网络中的权重。
单词表的大小意味着我们的skip-gram神经网络拥有非常庞大的权重数,所有权重都会被十亿个样本中的一个稍微地进行更新!
负采样通过使每一个训练样本仅仅改变一小部分的权重而不是所有权重,从而解决这个问题。下面介绍它是如何进行工作的。
当通过(”fox”, “quick”)词对来训练神经网络时,我们回想起这个神经网络的“标签”或者是“正确的输出”是一个one-hot向量。也就是说,对于神经网络中对应于”quick”这个单词的神经元对应为1,而其他上千个的输出神经元则对应为0。
使用负采样,我们通过随机选择一个较少数目(比如说5个)的“负”样本来更新对应的权重。(在这个条件下,“负”单词就是我们希望神经网络输出为0的神经元对应的单词)。并且我们仍然为我们的“正”单词更新对应的权重(也就是当前样本下”quick”对应的神经元)。
论文说选择5~20个单词对于较小的样本比较合适,而对于大样本,我们可以选择2~5个单词。
如果我们模型的输出层有大约300 x 10,000维度的权重矩阵。所以我们只需要更新正确的输出单词”quick”的权重,加上额外的5个其他应该输出为0的单词的权重。也就是总共6个输出神经元,和总共1800个的权重值。这些总共仅仅是输出层中3百万个权重中的0.06%。
2. 层次softmax
softmax需要对每个词语都计算输出概率,并进行归一化,计算量很大;
进行softmax的目的是多分类,那么是否可以转成多个二分类问题呢, 如SVM思想? 从而引入了层次softmax
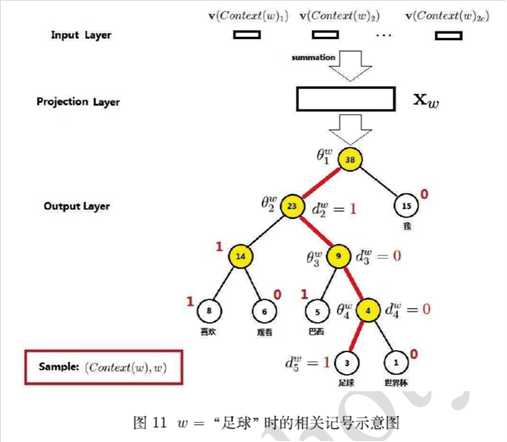
为什么有效?
1)用huffman编码做词表示
2)把N分类变成了log(N)个2分类。 如要预测的term(足球)的编码长度为4,则可以把预测为‘足球‘,转换为4次二分类问题,在每个二分类上用二元逻辑回归的方法(sigmoid);
3)逻辑回归的二分类中,sigmoid函数导数有很好的性质,σ′(x)=σ(x)(1−σ(x))σ′(x)=σ(x)(1−σ(x))
4)采用随机梯度上升求解二分类,每计算一个样本更新一次误差函数
注:gensim的word2vec 默认已经不采用分层softmax了, 因为log21000=10log21000=10也挺大的;如果huffman的根是生僻字,则分类次数更多。
参考文献:
https://blog.csdn.net/qq_28444159/article/details/77514563
http://flyrie.top/2018/10/31/Word2vec_Hierarchical_Softmax/
https://www.cnblogs.com/liyuxia713/p/11185028.html
原文:https://www.cnblogs.com/cymx66688/p/11223087.html