Solr 是一个 Java 开发的基于 Lucene 的企业级开源全文搜索平台,它采用的是反向索引,即从关键字到文档的映射过程。Solr 的资源以文档为对象进行存储,每个文档由一系列的字段构成,每个字段表示资源的一个属性。文档的字段可以被索引,以提供高性能的搜索效率。一般情况下文档都包含一个能唯一表示该文档的 id 字段??
讲述倒排索引之前,先来解释几个关于倒排索引的术语:
假设文档集合包含五个文档,每个文档内容如图所示,在图中最左端一栏是每个文档对应的文档编号。我们的任务就是对这个文档集合建立倒排索引。
中文和英文等语言不同,单词之间没有明确分隔符号,所以首先要用分词系统将文档自动切分成单词序列。solr 中有一种分词器就是 IK Analyzer 中文分词器。这样每个文档就转换为由单词序列构成的数据流,为了系统后续处理方便,需要对每个不同的单词赋予唯一的单词编号,同时记录下哪些文档包含这个单词,在如此处理结束后,我们可以得到倒排索引。
简单总结:倒排索引它记录的是词,和词所存在的文档 id 的所有列表。通过这种索引结构的存储方式,其查询速率可想而知。
将文档内容用用 solr 自带分词器进行分词,然后作为索引,用二分法将关键字与排序号的索引进行匹配,静儿查找到对应文档。
| 排序法 | 最差时间分析 | 平均时间复杂度 | 稳定度 | 空间复杂度 |
|---|---|---|---|---|
| 冒泡排序 | O(n2) | O(n2) | 稳定 | O(1) |
| 插入排序 | O(n2) | O(n2) | 稳定 | O(1) |
| 选择排序 | O(n2) | O(n2) | 稳定 | O(1) |
| 二叉树排序 | O(n2) | O(nlog2n) | 不一定 | O(n) |
| 快速排序 | O(n2) | O(nlog2n) | 不稳定 | O(log2n)~O(n) |
| 堆排序 | O(nlog2n) | O(nlog2n) | 不稳定 | O(1) |
| 希尔排序 | O | O | 不稳定 | O(1) |
| 查找 | 平均时间复杂度 | 查找条件 | 算法描述 |
|---|---|---|---|
| 顺序查找 | O(n) | 无序或有序队列 | 按顺序比较每个元素,直到找到关键字为止 |
| 二分查找(折半查找) | O(logn) | 有序数组 | 查找过程从数组的中间元素开始,如果中间元素正好是要查找的元素,则搜素过程结束;如果某一特定元素大于或者小于中间元素,则在数组大于或小于中间元素的那一半中查找,而且跟开始一样从中间元素开始比较。 如果在某一步骤数组为空,则代表找不到。 |
| 二叉排序树查找 | O(logn) | 二叉排序树 | 在二叉查找树b中查找x的过程为:1. 若b是空树,则搜索失败;2. 若x等于b的根节点的数据域之值,则查找成功;3. 若x小于b的根节点的数据域之值,则搜索左子树;4. 查找右子树。 |
| 哈希表法(散列表) | O(1) | 先创建哈希表(散列表) | 根据键值方式(Key value)进行查找,通过散列函数,定位数据元素。 |
| 分块查找 | O(logn) | 无序或有序队列 | 将n个数据元素"按块有序"划分为m块(m ≤ n)。每一块中的结点不必有序,但块与块之间必须"按块有序";即第1块中任一元素的关键字都必须小于第2块中任一元素的关键字;而第2块中任一元素又都必须小于第3块中的任一元素,然后使用二分查找及顺序查找。 |
当我们访问项目邮轮旅游模块的热门航线搜索时的时候,我们可以根据我们随意所想的内容输入关键字就可以查找到相关的内容。之所以能够如愿查找出来,是因为 solr 全文检索工具的实现。由于 solr 是基于 Lucene 实现的,而 Lucene 采用了次元匹配和切分词。举个例子:厦门-日本,Lucene 的切分词可以切分成:厦门、日本、厦日、日门等词,所以我们搜索的时候都是能够所搜得到的。solr 还有一种专门是切分中文的分词器叫 IKAnalyzer。
Solr 和 Elasticsearch 都是基于全文搜索引擎 Lucene 实现的。
实时搜索是说用户对于搜索的结果是实时变化的。
传统搜索是从静态数据库中筛选出符合条件的结果,这种结果往往是不可变的、静态的。
许多 Web 应用都将数据保存到数据库中,应用服务器从中读取数据并在浏览器中显示。随着应用系统业务量的增长和用户的增加,对数据库的访问更加频繁和集中,服务器的压力越来越大、性能逐渐下降,会出现网页显示延迟甚至服务器崩溃等重大影响。这时就该是用 Memcached 了,通过减少数据库的访问次数,以提高动态 Web 应用的速度、提高可扩展性。
memcached 是一个高性能的分布式内存缓存服务器,用于动态 Web 应用以减轻数据库负载。它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高动态 Web 的速度、提高可扩展性。memcached 基于一个存储键/值对的 HashMap。

根据服务器台数的余数进行哈希,求得键的哈希值,再处理服务器台数,根据余数选择服务器。
缺点:当添加或者一处服务器时,缓存重组的代价太大。当添加服务器,要进行重哈希,会导致原来的服务器序号变了,下一次找不到访问数据,Memcached 命中率下降,那么就增加了数据库服务器的负载。
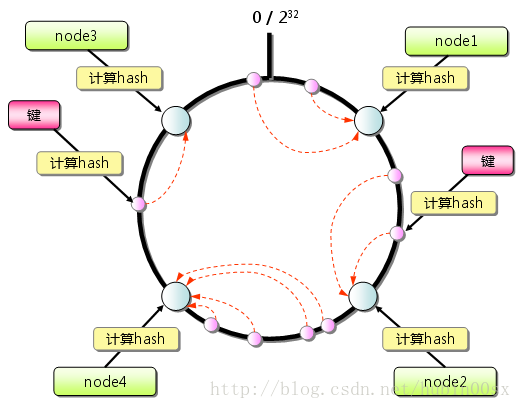
一致性哈希是将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数 H 的值空间是 0~(2^32 - 1) (即哈希值是一个 32 位的无符号整型),这个哈希空间为环。然后让每台机器站一个扇形空间。
先算每台服务器(节点)的hash值,然后将这些值映射到一个0到2^32次方的圆上。
计算存储数据的key的hash值,然后将这个值同样也映射到服务器分布的圆上,然后顺时针查找,将数据保存到查找到的第一个服务器。
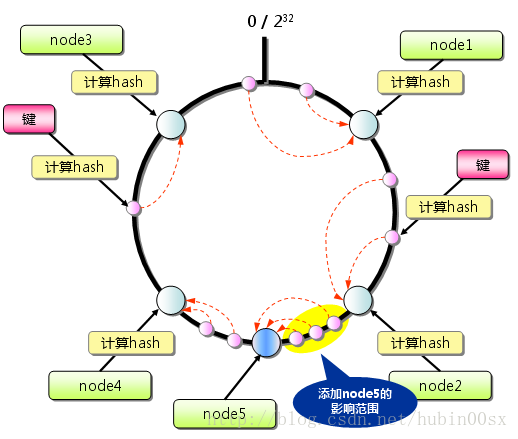
采用一致性Hash算法,这样在添加一个服务器节点的时候。就只会影响增加服务器的地点逆时针方向的第一台服务器受影响。
一致性Hash最大限度地抑制了键的重新分布。使用一般的hash函数的话,服务器的映射地点的分布非常不均匀。因此,使用虚拟节点的思想,为每个物理节点(服务器)在圆上分配 100~200 个点。这样就能抑制分布不均匀,最大限度地减小服务器增减时的缓存重新分布。
采用一致性Hash算法的情况下,由N台服务器增加M台服务器后,缓存的命中率为(1-N/(N+M))*100。
举例:
余数哈希相当于一个萝卜一个坑,刚好全部装下。这时候在中间新挖一个坑,下一次去拿的时候会按照原有的逻辑拿,会导致最后一个萝卜的坑没有被拿到,丢失了。一致性哈希就是在这 100 米以内都来挖这个坑,100 米之后的去下一个坑,这时候新挖一个坑,重新调整一些空间给新的坑就行,不至于数据全部丢失。
LRU。每个 slab 会维护一个队列,刚插入的数据在队头,经常 get 的数据也会移动到队头,这样较老或者访问较少的数据在队尾。该算法从队尾开始淘汰。当 slab 分配不到足够的内存是,首先会检查队尾是否有过期数据,如果有的话会直接将其覆盖为新的对象,如果没有,会开始淘汰队尾的对象。
slab 是一个内存块,它是 memcached 一次申请内存的最新单位。slab 的大小固定为 1M (1048576 Byte),一个 slab 由若干个大小相对的 chunk 组成。每个 chunk 都保存了一个 item 结构体、一堆 key 和 value。
Slab Allocation 的原理相当简单。它首先从操作系统申请一大块内存,并将其分割成各种尺寸的块 Chunk,并把尺寸相同的块分成组 Slab Class。其中,Chunk就是用来存储 key-value 数据的最小单位。每个 Slab Class 的大小,可以在 Memcached 启动的时候通过制定 Growth Factor 来控制。假定下图中 Growth Factor 的取值为 1.25,所以如果第一组 Chunk 的大小为 88 个字节,第二组 Chunk 的大小就为 112 个字节,依此类推。
当 Memcached 接收到客户端发送过来的数据时首先会根据收到数据的大小选择一个最合适的 Slab Class,然后通过查询 Memcached 保存着的该 Slab Class 内空闲 Chunk 的列表就可以找到一个可用于存储数据的Chunk。当一条数据库过期或者丢弃时,该记录所占用的 Chunk 就可以回收,重新添加到空闲列表中。从以上过程我们可以看出 Memcached 的内存管理制效率高,而且不会造成内存碎片,但是它最大的缺点就是会导致空间浪费。因为每个 Chunk都分配了特定长度的内存空间,所以变长数据无法充分利用这些空间。如图所示,将 100 个字节的数据缓存到 128 个字节的 Chunk 中,剩余的 28 个字节就浪费掉了。
有持久化需求或者对数据结构和处理有高级要求的应用,选择 Redis,其他简单的 key/value 存储,选择 Memcached。对于两者的选择需要看具体的应用场景,如果需要缓存的数据只是 key-value 这样简单的结构是,则还是采用 Memcached,它也足够的稳定可靠。如果涉及到存储、排序等一系列复杂的操作时,毫无疑问是 Redis。
原文:https://www.cnblogs.com/reformdai/p/11257379.html