上一节写了ReentrantLock, 那这一节就正好来写积蓄已久的1.7 concurrentHashMap了。因为1.7里面concurrentHashMap里面的segment是继承自ReentrantLock的。
我认为理解这个类有几个重点:
我们知道hashmap最基本的就是有一个entry数组,其中每个数组值代表着hash表容量内的每个key值,然后如果冲突的话那就是用链表法来解决,就是每个entry往后叠加构成链表。
Hashtable的并发核心思想是synchronized,就是整个map加锁,那这样的话能够保证并发安全,但是就牺牲了很多读的时间了。
那1.7的concurrentHashMap的核心就是在保证并发安全的情况下,利用了分段锁来提升并发效率。
我们先看第一个问题
/**
* The minimum capacity for per-segment tables. Must be a power
* of two, at least two to avoid immediate resizing on next use
* after lazy construction.
*/
static final int MIN_SEGMENT_TABLE_CAPACITY = 2;
/**
* The maximum number of segments to allow; used to bound
* constructor arguments. Must be power of two less than 1 << 24.
*/
static final int MAX_SEGMENTS = 1 << 16; // slightly conservative
/**
* Number of unsynchronized retries in size and containsValue
* methods before resorting to locking. This is used to avoid
* unbounded retries if tables undergo continuous modification
* which would make it impossible to obtain an accurate result.
*/
static final int RETRIES_BEFORE_LOCK = 2;我们看看hashmap中没有的变量
MIN_SEGMENT_TABLE_CAPACITY:最小的段的表容量;
MAX_SEGMENTS: 最大的段数量
RETRIES_BEFORE_LOCK:在调用lock方法前的最大非重试次数
/**
* Mask value for indexing into segments. The upper bits of a
* key's hash code are used to choose the segment.
*/
final int segmentMask;
/**
* Shift value for indexing within segments.
*/
final int segmentShift;
/**
* The segments, each of which is a specialized hash table.
*/
final Segment<K,V>[] segments;segmentMask:检索到段的掩码值;
segmentShift:检索到段的偏移量
segments:段数组,每个段都是一个特殊的hashtable
记住这个东西是继承了ReentrantLock的,因此他是一把锁!所以叫做分段锁!
static final class Segment<K,V> extends ReentrantLock implements Serializable /**
* The number of elements. Accessed only either within locks
* or among other volatile reads that maintain visibility.
*/
transient int count;
/**
* The total number of mutative operations in this segment.
* Even though this may overflows 32 bits, it provides
* sufficient accuracy for stability checks in CHM isEmpty()
* and size() methods. Accessed only either within locks or
* among other volatile reads that maintain visibility.
*/
transient int modCount;
/**
* The table is rehashed when its size exceeds this threshold.
* (The value of this field is always <tt>(int)(capacity *
* loadFactor)</tt>.)
*/
transient int threshold;这几个东西都是transient的,这个修饰词之前没有研究,之后要研究一下。
count:元素的个数,只能通过锁来访问或者通过其他可以保证可见性的volatile读来访问。
modCount: 对当前分段锁的可变操作数的总和,只能通过锁来访问或者通过其他可以保证可见性的volatile读来访问。
threshold:capacity *loadFactor,size超过这个限度就会rehash。
从这里我们看出重要的逻辑应该都是要通过segment来实现了,因为哈希表都是存在这里的。
我们通过初始化方法和get方法来解释这个问题(假设以下变量都是默认情况)
/**
* Creates a new, empty map with the specified initial
* capacity, load factor and concurrency level.
*
* @param initialCapacity the initial capacity. The implementation
* performs internal sizing to accommodate this many elements.
* @param loadFactor the load factor threshold, used to control resizing.
* Resizing may be performed when the average number of elements per
* bin exceeds this threshold.
* @param concurrencyLevel the estimated number of concurrently
* updating threads. The implementation performs internal sizing
* to try to accommodate this many threads.
* @throws IllegalArgumentException if the initial capacity is
* negative or the load factor or concurrencyLevel are
* nonpositive.
*/
@SuppressWarnings("unchecked")
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
//默认值:loadFactor=0.75f initialCapacity=16 concurrencyLevel=16 以下重要变量
//我们会用默认值来分析
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// Find power-of-two sizes best matching arguments
int sshift = 0;
int ssize = 1;
//如果concurrencyLevel=16 则ssize(segment_size)会置为16 sshift(segment_shift)会置为4
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
//segmentShift=28 segmentMask = 15 1111
this.segmentShift = 32 - sshift;
this.segmentMask = ssize - 1;
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
//这个c变量是为了获取初始key值容量(entry数组的总size)和segment的size的一个比值,目的是能够初始化出每个segment里面有的entry数组的size
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
int cap = MIN_SEGMENT_TABLE_CAPACITY;
while (cap < c)
cap <<= 1;
// create segments and segments[0]
Segment<K,V> s0 =
new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
(HashEntry<K,V>[])new HashEntry[cap]);
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
//以第一个数组为模板来初始化segment数组,注意这里只初始化了里面的第一个segment
UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
this.segments = ss;
}这个方法信息量比较大,因此主要信息都写在注释里面了。注意新建的segment是懒加载的
Segment(float lf, int threshold, HashEntry<K,V>[] tab) {
this.loadFactor = lf;
this.threshold = threshold;
this.table = tab;
}初始化好了之后看有点难度的get方法
/**
* Returns the value to which the specified key is mapped,
* or {@code null} if this map contains no mapping for the key.
*
* <p>More formally, if this map contains a mapping from a key
* {@code k} to a value {@code v} such that {@code key.equals(k)},
* then this method returns {@code v}; otherwise it returns
* {@code null}. (There can be at most one such mapping.)
*
* @throws NullPointerException if the specified key is null
*/
public V get(Object key) {
Segment<K,V> s; // manually integrate access methods to reduce overhead
HashEntry<K,V>[] tab;
//这个hash算法十分复杂,没有仔细研究,应该是为了均摊效应更加而设计
int h = hash(key);
//default值来说,segmentShift=28 segmentMask = 15(1111)SSHIFT SBASE是调用本地方法赋值,意思是每个segment的偏移量和segment的基本内存地址
//(h >>> segmentShift) & segmentMask)取得是哈希值的高四位来作为选取的segment的indexcode!
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
//然后就用UNSAFE包去取得整个数组
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
//上面将s.table赋给了tab
//下面是还有一个映射的过程,就是用tab.length-1来作为掩码进行映射(这也是为什么每个segment里面的table值的size都需要是2的整数次幂的原因),然后TSHIFT和TBASE是和上面同理的
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
}大致的逻辑上面已经讲了,通过当前key的hash高N位值来取得是哪个segment,然后再和这个segment
里面的tab数组的size做映射来取得具体是哪个entry,然后一步步来继续找。
一般来说,大部分的容器或者说是锁,或者是业务代码的增删改,都是添加的时候是最麻烦的。
/**
* Maps the specified key to the specified value in this table.
* Neither the key nor the value can be null.
*
* <p> The value can be retrieved by calling the <tt>get</tt> method
* with a key that is equal to the original key.
*
* @param key key with which the specified value is to be associated
* @param value value to be associated with the specified key
* @return the previous value associated with <tt>key</tt>, or
* <tt>null</tt> if there was no mapping for <tt>key</tt>
* @throws NullPointerException if the specified key or value is null
*/
@SuppressWarnings("unchecked")
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
int hash = hash(key);
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j);
return s.put(key, hash, value, false);
}如果是第一次添加元素,那就会有可能进入ensureSegment,传入的值是segment的数组index。
/**
* Returns the segment for the given index, creating it and
* recording in segment table (via CAS) if not already present.
*
* @param k the index
* @return the segment
*/
@SuppressWarnings("unchecked")
private Segment<K,V> ensureSegment(int k) {
final Segment<K,V>[] ss = this.segments;
long u = (k << SSHIFT) + SBASE; // raw offset
Segment<K,V> seg;
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) {
Segment<K,V> proto = ss[0]; // use segment 0 as prototype
int cap = proto.table.length;
float lf = proto.loadFactor;
int threshold = (int)(cap * lf);
HashEntry<K,V>[] tab = (HashEntry<K,V>[])new HashEntry[cap];
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))
== null) { // recheck
Segment<K,V> s = new Segment<K,V>(lf, threshold, tab);
while ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))
== null) {
if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s))
break;
}
}
}
return seg;
}我们看到这里有两个重点:
然后我们看Segment.put
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
//这一步是为了保证一定要获取到锁
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
if (node != null)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
//释放锁
unlock();
}
return oldValue;
}其实scanAndLockForPut这个方法是整个concurrentHashMap中最难的方法。
注释很难,很抽象,读了无数次也翻译不过来。
核心意思就是,这个方法如果返回了就肯定能够获取锁。
/**
* Scans for a node containing given key while trying to
* acquire lock, creating and returning one if not found. Upon
* return, guarantees that lock is held. UNlike in most
* methods, calls to method equals are not screened: Since
* traversal speed doesn't matter, we might as well help warm
* up the associated code and accesses as well.
*
* @return a new node if key not found, else null
*/
private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) {
HashEntry<K,V> first = entryForHash(this, hash);
HashEntry<K,V> e = first;
HashEntry<K,V> node = null;
//这个-1是基础数,每次重来的时候都会置为-1
int retries = -1; // negative while locating node
//不停地尝试cas拿锁,有幸拿到了就直接返回null,靠put方法来入链表
while (!tryLock()) {
HashEntry<K,V> f; // to recheck first below
//在while中一边试着cas拿锁,一边试着找到这个key该有的位置等待retries能够被置为1
if (retries < 0) {
if (e == null) {
if (node == null) // speculatively create node
node = new HashEntry<K,V>(hash, key, value, null);
retries = 0;
}
else if (key.equals(e.key))
retries = 0;
else
e = e.next;
}
//如果是找到当前的节点的定位才能有++retries的权利
//如果是单核的机器的话那就是MAX_SCAN_RETRIES=1,否则这个MAX_SCAN_RETRIES=64,不太明白为什么差距这么大
else if (++retries > MAX_SCAN_RETRIES) {
lock();
break;
}
//这个应该是重试次数为单数的时候就会检查一下头结点有没有变化否则又要重新开始,因为当前的分段锁状态已经是变了的
else if ((retries & 1) == 0 &&
(f = entryForHash(this, hash)) != first) {
e = first = f; // re-traverse if entry changed
retries = -1;
}
}
return node;
}这里有个疑问就是为什么要有这个判断(retries & 1) == 0,而不是每次都是判定一下。
然后再回看put方法
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
//这个scanAndLockForPut出来的时候如果node非空那就是认为是没有找到key一致的节点的
V oldValue;
try {
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
//这个其实是和scanAndLockForPut类似的逻辑的,也是先找出node应该的定位
if (e != null) {
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
//进入第一个if的话就是在已有的节点找不到节点的情况了,那为什么不把这种情况直接写在一开始呢,个人理解这个东西是有可能在scanAndLockForPut中新建节点后和获取锁之前,这个位置的节点状态依然可能被改变,所以需要上述方法的复查。
if (node != null)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
//这个方法完成扩容
rehash(node);
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
unlock();
}
return oldValue;
}rehash方法很简单,其中有一小段可能会有点费解,注释也说了一下。
/**
* Doubles size of table and repacks entries, also adding the
* given node to new table
*/
@SuppressWarnings("unchecked")
private void rehash(HashEntry<K,V> node) {
/*
* Reclassify nodes in each list to new table. Because we
* are using power-of-two expansion, the elements from
* each bin must either stay at same index, or move with a
* power of two offset. We eliminate unnecessary node
* creation by catching cases where old nodes can be
* reused because their next fields won't change.
* Statistically, at the default threshold, only about
* one-sixth of them need cloning when a table
* doubles. The nodes they replace will be garbage
* collectable as soon as they are no longer referenced by
* any reader thread that may be in the midst of
* concurrently traversing table. Entry accesses use plain
* array indexing because they are followed by volatile
* table write.
*/
HashEntry<K,V>[] oldTable = table;
int oldCapacity = oldTable.length;
int newCapacity = oldCapacity << 1;
threshold = (int)(newCapacity * loadFactor);
HashEntry<K,V>[] newTable =
(HashEntry<K,V>[]) new HashEntry[newCapacity];
int sizeMask = newCapacity - 1;
for (int i = 0; i < oldCapacity ; i++) {
HashEntry<K,V> e = oldTable[i];
if (e != null) {
HashEntry<K,V> next = e.next;
int idx = e.hash & sizeMask;
if (next == null) // Single node on list
newTable[idx] = e;
else { // Reuse consecutive sequence at same slot
HashEntry<K,V> lastRun = e;
int lastIdx = idx;
//一部分挺复杂的,我理解的意思是,由于新的扩容之后,capacity会比原来大一倍,原来的掩码是1111,新的掩码是11111,这样原来的hash值和新的掩码相与之后第五位会有1或者0,这样比如这个链表和newCapacity相与之后的值为1,0,1,0,1,0,1,1,1,1这样呢,那最后四个1就可以一次性添加进新的表里面了,然后再从第一个表到倒数第四个1之间的数字加进去这个链表里面,只是这么写会看起来高端一点,然后可以加速一些极端情况下的处理(参看上一条官方注释)
for (HashEntry<K,V> last = next;
last != null;
last = last.next) {
int k = last.hash & sizeMask;
if (k != lastIdx) {
lastIdx = k;
lastRun = last;
}
}
newTable[lastIdx] = lastRun;
// Clone remaining nodes
for (HashEntry<K,V> p = e; p != lastRun; p = p.next) {
V v = p.value;
int h = p.hash;
int k = h & sizeMask;
HashEntry<K,V> n = newTable[k];
newTable[k] = new HashEntry<K,V>(h, p.key, v, n);
}
}
}
}
int nodeIndex = node.hash & sizeMask; // add the new node
node.setNext(newTable[nodeIndex]);
newTable[nodeIndex] = node;
table = newTable;
}其他的一些方法例如都是用了类似的方法设计
思想其实和jdk1.6的锁升级有点像。
看了几次这个类,感觉有两个地方还是不理解,都是在scanAndLockForPut;
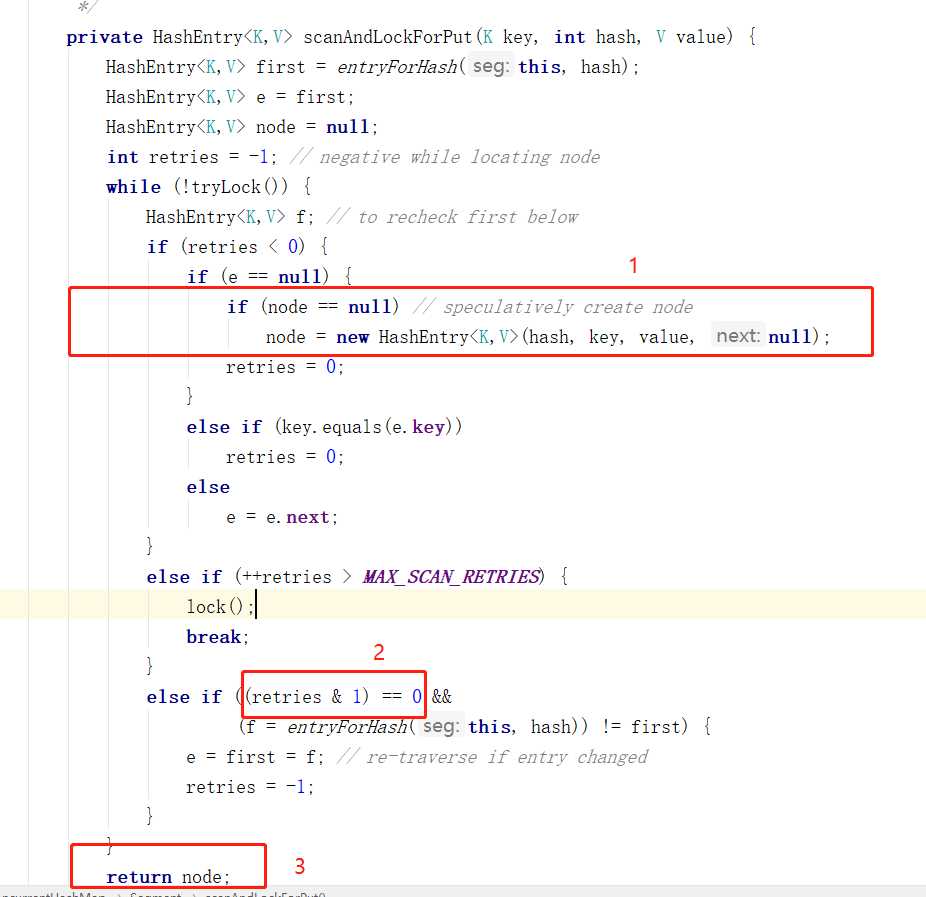
我认为可以改为如下(按照图中的标号所示):
希望有朋友可以给我解答这个问题,谢谢!
原文:https://www.cnblogs.com/kobebyrant/p/11291440.html