一篇很好的入门博客,http://mccormickml.com/2016/04/19/word2vec-tutorial-the-skip-gram-model/
他的翻译,https://www.jianshu.com/p/1405932293ea
可以作为参考的,https://blog.csdn.net/mr_tyting/article/details/80091842
有论文和代码,https://blog.csdn.net/mr_tyting/article/details/80091842
word2vector,顾名思义,就是将语料库中的词转化成向量,以便后续在词向量的基础上进行各种计算。
最常见的表示方法是counting 编码。假设我们的语料库中是如下三句话:
I like deep learning
I like NLP
I enjoy flying
利用counting编码,我们可以绘出如下矩阵:
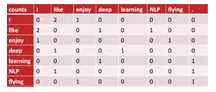
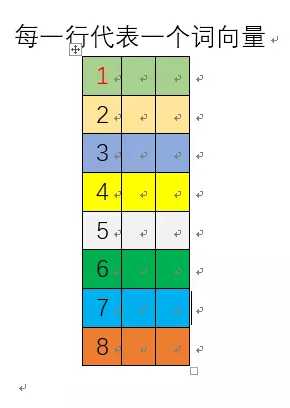
假设语料库中的单词数量是N,则上图矩阵的大小就是N*N,其中的每一行就代表一个词的向量表示。如第一行
0 2 1 0 0 0 0
是单词I的向量表示。其中的2代表I这个单词与like这个词在语料库中共同出现了2次。
但是这种办法至少有三个缺陷:
尽管我们可以通过SVD来降低向量的维度,但是SVD本身却是一个需要巨大计算量的操作。
很明显,这种办法在实际中并不好用。我们今天学习的skip gram算法可以成功克服以上三个缺陷。它的基本思想是首先将所有词语进行one-hot编码,输入只有一个隐藏层的神经网络,定义好loss后进行训练,后面我们会讲解如何定义loss,这里暂时按下不表。训练完成后,我们就可以用隐藏层的权重来作为词的向量表示!!
这个思想乍听起来很神奇是不是?其实我们早就熟悉它了。auto-encoder时,我们也是用有一个隐藏层的神经网络进行训练,训练完成后,丢去后面的output层,只用隐藏层的输出作为最终需要的向量对象,藉此成功完成向量的压缩。
Word2Vec有两种训练方法,一种叫CBOW,核心思想是从一个句子里面把一个词抠掉,用这个词的上文和下文去预测被抠掉的这个词;第二种叫做Skip-gram,和CBOW正好反过来,输入某个单词,要求网络预测它的上下文单词。下面以Skip-gram为例介绍,
1、word2Vec只是一个三层 的神经网络。
2、喂给模型一个word,然后用来预测它周边的词。
3、然后去掉最后一层,只保存input_layer 和 hidden_layer。
4、从词表中选取一个词,喂给模型,在hidden_layer 将会给出该词的embedding repesentation。
用神经网络训练,大体有如下几个步骤:
准备好data,即X和Y
定义好网络结构
定义好loss
选择合适的优化器
进行迭代训练
存储训练好的网络
一、构造训练数据
假设我们的语料库中只有一句话:The quick brown fox jumps over the lazy dog.
这句话中共有8个词(这里The与the算同一个词)。skip gram算法是怎么为这8个词生成词向量的呢?
其实非常简单,(x,y)就是一个个的单词对。比如(the,quick)就是一个单词对,the就是样本数据,quick就是该条样本的标签。
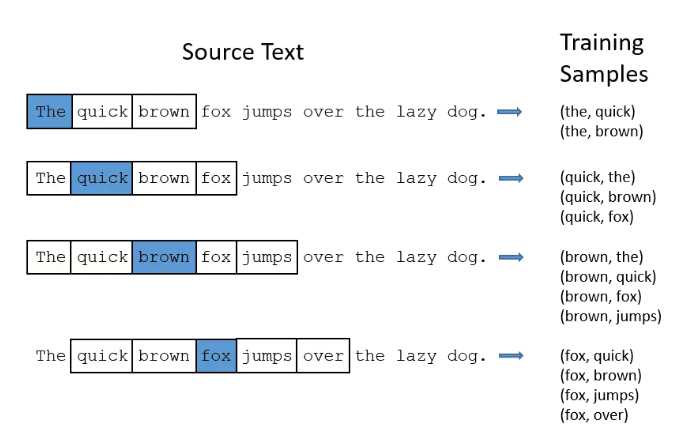
那么,如何从上面那句话中生成单词对数据呢?答案就是n-gram方法。多说不如看图:
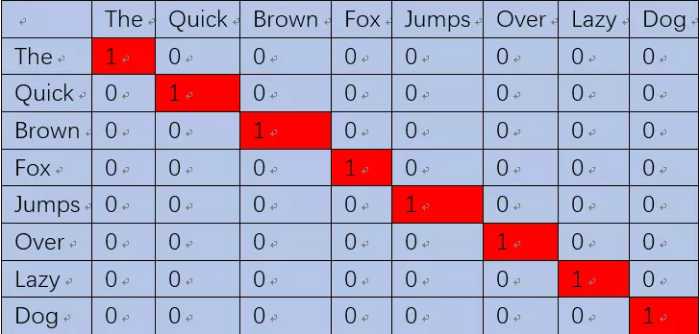
(the,quick)单词对就表示成【(1,0,0,0,0,0,0,0),(0,1,0,0,0,0,0,0)】。这样就可以输入神经网络进行训练了,当我们将the输入神经网络时,希望网络也能输出一个8维的向量,并且第二维尽可能接近1(即接近quick),其他维尽可能接近0。也就是让神经网络告诉我们,quick更可能出现在the的周围。当然,我们还希望这8维向量所有位置的值相加为1,因为相加为1就可以认为这个8维向量描述的是一个概率分布,正好我们的y值也是一个概率分布(一个位置为1,其他位置为0),我们就可以用交叉熵来衡量神经网络的输出与我们的label y的差异大小,也就可以定义出loss了。
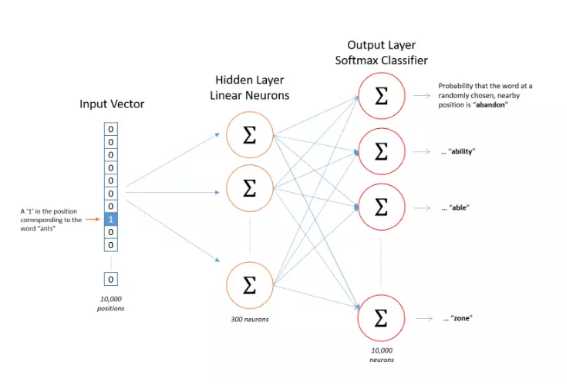
4、隐藏层
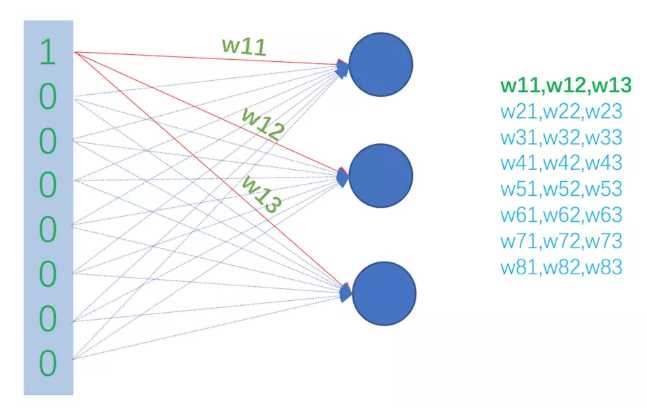
网络训练完成后,这个8行3列的矩阵的每一行就是一个单词的词向量!如下图所示:
网络的输入是one-hot编码的单词,它与隐藏层权重矩阵相乘实际上是取权重矩阵特定的行,如下图所示:
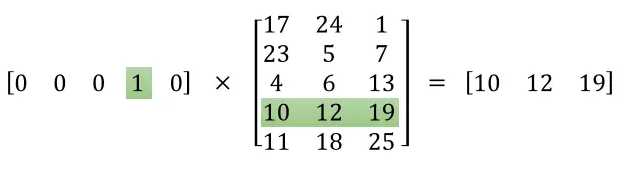
这意味着,隐藏层实际上相当于是一个查找表,它的输出就是输入的单词的词向量
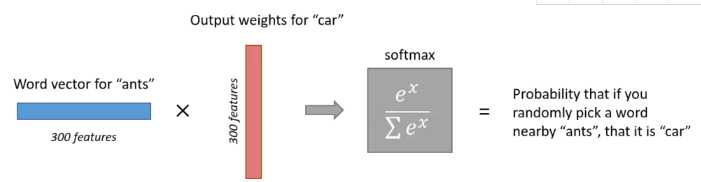
这里有一点需要注意,我们说输出的是该单词出现在输入单词周围的概率大小,这个“周围”包含单词的前面,也包含单词的后面。

在tensorflow里面实现的word2Vec,vocab_szie并不是所有的word的数量,而且先统计了所有word的出现频次,然后选取出现频次最高的前50000的词作为词袋。具体操作请看代码 tensorflow/examples/tutorials/word2vec/word2vec_basic.py,其余的词用unkunk代替。
采用一种所谓的”负采样”的操作,这种操作每次可以让一个样本只更新权重矩阵中一小部分,减小训练过程中的计算压力。
举例来说:一个input output pair如:(“fox”,“quick”),由上面的分析可知,其true label为一个one−hot向量,并且该向量只是在quick的位置为1,其余的位置均为0,并且该向量的长度为vocab size,由此每个样本都缓慢能更新权重矩阵,而”负采样”操作只是随机选择其余的部分word,使得其在true label的位置为0,那么我们只更新对应位置的权重。例如我们如果选择负采样数量为5,则选取5个其余的word,使其对应的output为0,这个时候output只是6个神经元,本来我们一次需要更新300∗10,000参数,进行负采样操作以后只需要更新300∗6=1800个参数。
原文:https://www.cnblogs.com/bnuvincent/p/11296343.html