因为在工作中经常会用到阻塞队列,有的时候还要根据业务场景获取重写阻塞队列中的方法,所以学习一下阻塞队列的实现原理还是很有必要的。(PS:不深入了解的话,很容易使用出错,造成没有技术深度的样子)
要想了解阻塞队列,先了解一下队列是啥,简单的说队列就是一种先进先出的数据结构。(具体的内容去数据结构里学习一下)所以阻塞队列就是一种可阻塞的队列。和普通的队列的不同就体现在 ”阻塞“两个字上。阻塞是啥意思?
百度看一下

在软件工程里阻塞一般指的是阻塞调用,即调用结果返回之前,当前线程会被挂起。函数只有在得到结果之后才会返回。
阻塞队列其实就是普通的队列根据需要将某些方法改为阻塞调用。所以阻塞队里和普通队里的不同主要体现在两个方面
那么为什么要使用阻塞队列?阻塞队列又能完成什么特殊的任务吗?
阻塞队列的经典使用 场景就是“生产者”和“消费者”模型,生产者生产数据,放入队列,然后消费从队列中获取数据,这个在一般情况下自然没有问题,但如果生产者和消费者在某个时间段内,万一发生数据处理速度不匹配的情况呢?
在出现消费者速度远大于生产者速度,消费者在数据消费至一定程度的情况下,暂停等待一下(阻塞消费者)来等待生产者,以保证生产者能够生产出新的数据;反之亦然。
阻塞队列在java中的一种典型使用场景是线程池,在线程池中,当提交的任务不能被立即得到执行的时候,线程池就会将提交的任务放到一个阻塞的任务队列中来(线程池的具体使用参见之前写的一篇文章《java并发之线程池的浅析》)
然而,在阻塞队列发布以前,在多线程环境下,我们每个程序员都必须去自己控制这些细节,尤其还要兼顾效率和线程安全,而这会给我们的程序带来不小的复杂度。在这里要感谢一下concurrent包,减轻了我们很多工作
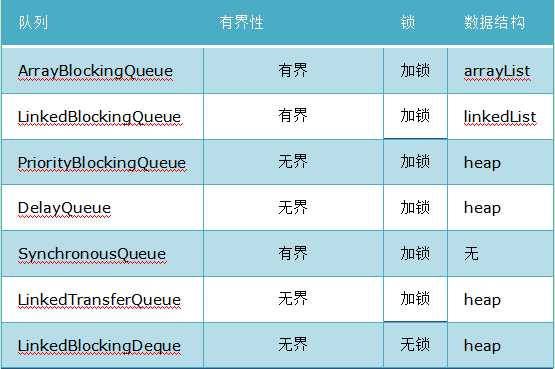
下面分别简单介绍一下:
ArrayBlockingQueue:是一个用数组实现的有界阻塞队列,此队列按照先进先出(FIFO)的原则对元素进行排序。构造时必须传入的参数是数组大小此外还可以指定是否公平性。【注:每一个线程在获取锁的时候可能都会排队等待,如果在等待时间上,先获取锁的线程的请求一定先被满足,那么这个锁就是公平的。反之,这个锁就是不公平的。公平的获取锁,也就是当前等待时间最长的线程先获取锁】;在插入或删除元素时不会产生或销毁任何额外的对象实例
LinkedBlockingDeque: 一个由链表结构组成的双向阻塞队列。队列头部和尾部都可以添加和移除元素,多线程并发时,可以将锁的竞争最多降到一半。
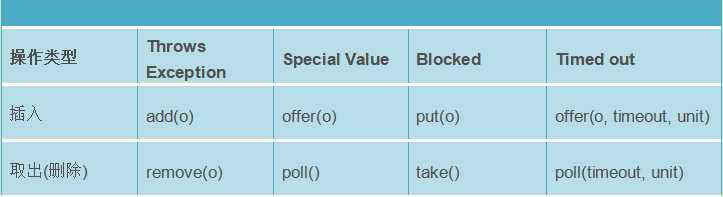
阻塞对队列的核心方法主要是插入操作操作和取出操作,如下
public boolean add(E e) { if (offer(e)) return true; else throw new IllegalStateException("Queue full"); }
前面介绍了非阻塞队列和阻塞队列中常用的方法,下面来探讨阻塞队列的实现原理,本文以比较常用的ArrayBlockingQueue为例,其他阻塞队列实现原理根据特性会和ArrayBlockingQueue有一些差别,但是大体思路应该类似,有兴趣的朋友可自行查看其他阻塞队列的实现源码。
首先看一下ArrayBlockingQueue的几个关键成员变量
public class ArrayBlockingQueue<E> extends AbstractQueue<E> implements BlockingQueue<E>, java.io.Serializable { /** The queued items */ final Object[] items; /** items index for next take, poll, peek or remove */ int takeIndex; /** items index for next put, offer, or add */ int putIndex; /** Number of elements in the queue */ int count; /* * Concurrency control uses the classic two-condition algorithm * found in any textbook. */ /** Main lock guarding all access */ final ReentrantLock lock; /** Condition for waiting takes */ private final Condition notEmpty; /** Condition for waiting puts */ private final Condition notFull; }
从上边可以明显的看出ArrayBlockingQueue用一个数组来存储数据,takeIndex和putIndex分别表示队首元素和队尾元素的下标,count表示队列中元素的个数。 lock是一个可重入锁,notEmpty和notFull是等待条件。
然后看它的一个关键方法的实现:put()
public void put(E e) throws InterruptedException { checkNotNull(e); final ReentrantLock lock = this.lock; lock.lockInterruptibly(); try { while (count == items.length) notFull.await(); enqueue(e); } finally { lock.unlock(); }
}
enqueue(E x)将元素插入到数组啊item中
/** * Inserts element at current put position, advances, and signals. * Call only when holding lock. */ private void enqueue(E x) { // assert lock.getHoldCount() == 1; // assert items[putIndex] == null; final Object[] items = this.items; items[putIndex] = x; if (++putIndex == items.length) putIndex = 0; count++; notEmpty.signal(); }
该方法内部通过putIndex索引直接将元素添加到数组items中
这里思考一个问题 为什么当putIndex索引大小等于数组长度时,需要将putIndex重新设置为0?
这是因为当队列是先进先出的 所以获取元素总是从队列头部获取,而添加元素从中从队列尾部获取。所以当队列索引(从0开始)与数组长度相等时,所以下次我们就需要从数组头部开始添加了;
最后当插入成功后,通过notEmpty唤醒正在等待取元素的线程
阻塞队列中和put对应的就是take了
下边是take方法的实现
public E take() throws InterruptedException { final ReentrantLock lock = this.lock; lock.lockInterruptibly(); try { while (count == 0) notEmpty.await(); return dequeue(); finally { lock.unlock(); } }
take方法其实很简单,队列中有数据就删除没有就阻塞,注意这个阻塞是可以中断的,如果队列没有数据那么就加入notEmpty条件队列等待(有数据就直接取走,方法结束),如果有新的put线程添加了数据,那么put操作将会唤醒take线程;
可以看到take的实现跟put方法实现很类似,只不过put方法等待的是notFull信号,而take方法等待的是notEmpty信号。(等的就是上文的put中的信号)当数组的数量为空时,也就是无任何数据可以被取出来的时候,notEmpty这个Condition就会进行阻塞,直到被notEmpty唤醒
dequeue的实现如下
private E dequeue() { final Object[] items = this.items; E x = (E) items[takeIndex]; items[takeIndex] = null; if (++takeIndex == items.length) takeIndex = 0; count--; if (itrs != null) itrs.elementDequeued(); notFull.signal(); return x; }
take方法主要是从队列头部取元素,可以看到takeIndex是取元素的时候的偏移值,而put中是putIndex控制添加元素的偏移量,由此可见,put和take操作的偏移量分别是由putIndex和takeIndex控制的。其实仔细观察put和take的实现思路是有很多相似之处。
模拟食堂的经历,食堂窗口端出一道菜放在台面,然后等待顾客消费。写到代码里就是食堂窗口就是一个生产者线程,顾客就是消费者线程,台面就是阻塞队列。
public class TestBlockingQueue {
/**
* 生产和消费业务操作
*
* @author tang
*
*/
protected class WorkDesk {
BlockingQueue<String> desk = new LinkedBlockingQueue<String>(8);
public void work() throws InterruptedException {
Thread.sleep(1000);
desk.put("端出一道菜");
}
public String eat() throws InterruptedException {
Thread.sleep(4000);
return desk.take();
}
}
/**
* 生产者类
*
* @author tang
*
*/
class Producer implements Runnable {
private String producerName;
private WorkDesk workDesk;
public Producer(String producerName, WorkDesk workDesk) {
this.producerName = producerName;
this.workDesk = workDesk;
}
@Override
public void run() {
try {
for (;;) {
workDesk.work();
System.out.println(producerName + "端出一道菜" +",Data:"+System.currentTimeMillis());
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
/**
* 消费者类
*
*
*/
class Consumer implements Runnable {
private String consumerName;
private WorkDesk workDesk;
public Consumer(String consumerName, WorkDesk workDesk) {
this.consumerName = consumerName;
this.workDesk = workDesk;
}
@Override
public void run() {
try {
for (;;) {
workDesk.eat();
System.out.println(consumerName + "端走了一个菜"+",Data:"+System.currentTimeMillis());
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
public static void main(String args[]) throws InterruptedException {
TestBlockingQueue testQueue = new TestBlockingQueue();
WorkDesk workDesk = testQueue.new WorkDesk();
ExecutorService service = Executors.newFixedThreadPool(6);
//四个生产者线程
for (int i=1;i<=4;++i) {
service.submit(testQueue.new Producer("食堂窗口-"+ i+"-", workDesk));
}
//两个消费者线程
Consumer consumer1 = testQueue.new Consumer("顾客-1-", workDesk);
Consumer consumer2 = testQueue.new Consumer("顾客-2-", workDesk);
service.submit(consumer1);
service.submit(consumer2);
service.shutdown();
}
}
结果部分如下
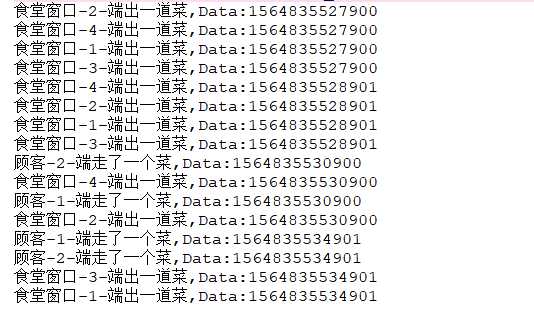
可以看到当生产者产生的数据达到阻塞队列的容量时,生成者线程会阻塞,等待消费者线程进行消费,上述案例中最大容量为8个盘子,所以当食堂做好了8个菜后了8会等待顾客进行消费,消费后继续生产。上述案例使用阻塞队列,看起来代码要简单得多,不需要再单独考虑同步和线程间通信的问题。
在并发编程中,一般推荐使用阻塞队列,这样实现可以尽量地避免程序出现意外的错误。
阻塞队列使用最经典的场景就是socket客户端数据的读取和解析,读取数据的线程不断将数据放入队列,然后解析线程不断从队列取数据解析。还有其他类似的场景,如线程池中就使用了阻塞队列,其实只要符合生产者-消费者模型的都可以使用阻塞队列。
参考资料:
《Java编程思想》
https://www.cnblogs.com/dolphin0520/p/3932906.html
https://www.cnblogs.com/superfj/p/7757876.html
原文:https://www.cnblogs.com/NathanYang/p/11276428.html