首先hadoop和spark肯定是必须的,而hadoop是用java编写的,spark是由Scala编写的,所以还需要安装jdk和scala。大数据第三方组件我们统统都安装在/opt目录下,首先这个目录当前是空的

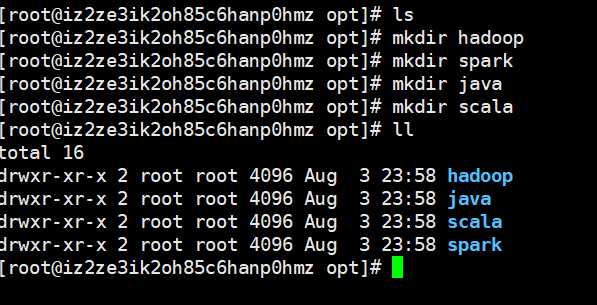
我们创建相应的目录,用于存放对应的组件

然后将相应的gz包进行上传
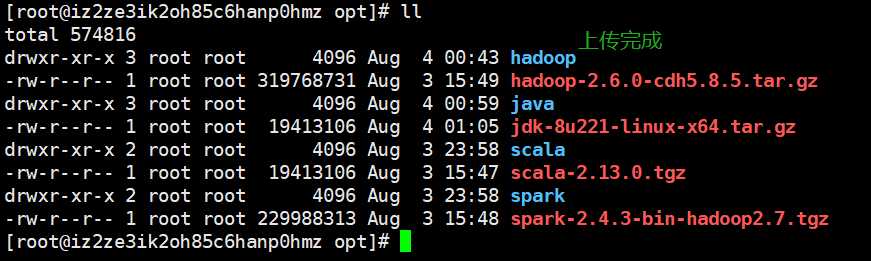
此刻在/opt目录
tar -zxvf ./jdk-8u221-linux-x64.tar.gz -C ./java
然后添加到环境变量,我一般添加到~/.bashrc里面去
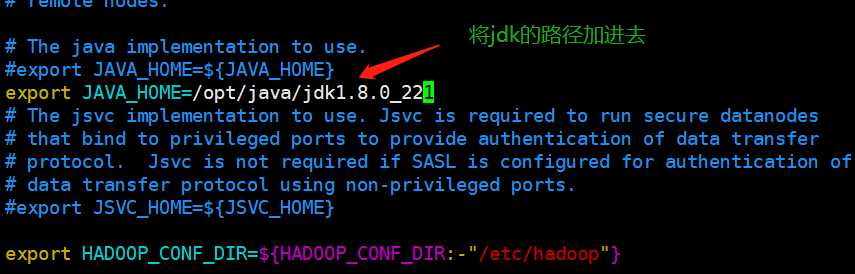
export JAVA_HOME=/opt/java/jdk1.8.0_221
export PATH=$JAVA_HOME/bin:$PATH
source ~/.bashrc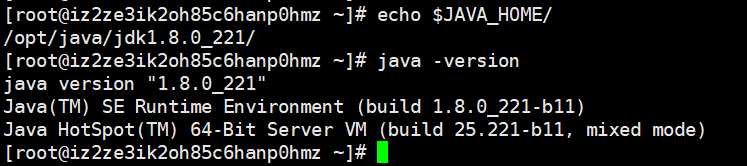
hadoop的话我这里选择的是cdh版本的,建议大家也这么选择,因为可以避免很多jar包的冲突。
进入到/opt目录
tar -zxvf ./hadoop-2.6.0-cdh5.8.5.tar.gz -C ./hadoop
export HADOOP_HOME=/opt/hadoop/hadoop-2.6.0-cdh5.8.5
export PATH=$HADOOP_HOME/bin:$PATH
source ~/.bashrc
除此之外我们还要安装ssh和rsync,这样在启动hdfs就不用输入用户密码了
yum install ssh
yum install rsync安装完之后,输入ssh-keygen -t rsa一路回车
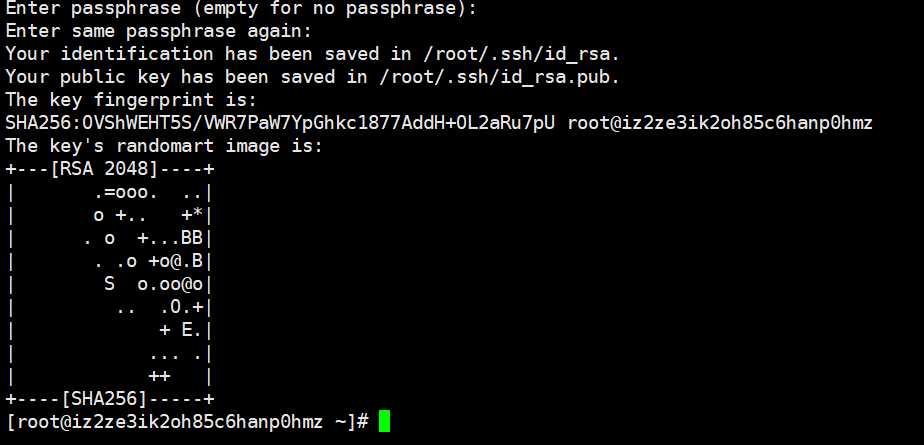
然后进入~/.ssh目录,执行如下命令, cp ./id_rsa.pub ./authorized_keys,不过我这里没有执行。
修改hadoop的几个配置文件
我们进入到$HADOOP_HOME/etc/hadoop目录下
1.修改hadoop-env.sh
2.修改core-site.xml
在configuration中添加如下内容
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:8020</value>
</property>3.修改hdfs-site.xml
在configuration中添加如下内容
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/tmp</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>修改临时文件的存储路径,不然一重启就没了,这肯定是不行的,这里路径指定为/opt/hadoop/tmp,然后是副本系数,因为我们这里是单机伪分布式的,所以副本系数设为1
4.slaves
这个对于单机来说,是不需要的,但是对于搭建真正的分布式是很有用的,我们搭建分布式,肯定需要多台机器,那么把其他机器的hostname加进去就可以了。
这里只有一个localhost,当然我们也可以写主机名
5.修改mapred-site.xml
首先目录里面没有mapred-site.xml,但是给我们提供了一个模板,mapred-site.xml.template,我们直接cp一下即可。
cp mapred-site.xml.template mapred-site.xml
在configuration中添加如下内容
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>6.修改yarn-site.xml
在configuration中添加如下内容
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>配置完成
下面格式化文件系统:hdfs namenode -format,这个操作只需要执行一次,我们进入~目录操作吧
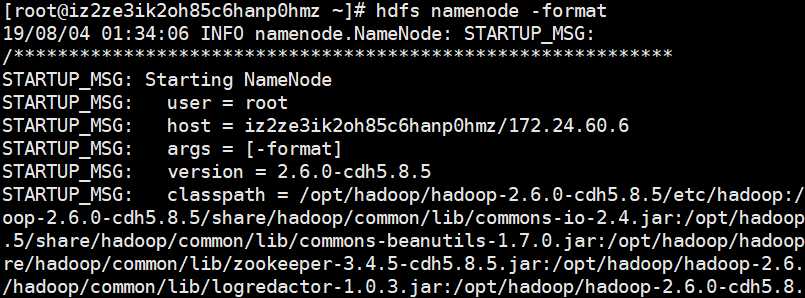
如果配置正确,那么出现一大堆输出,表示执行成功
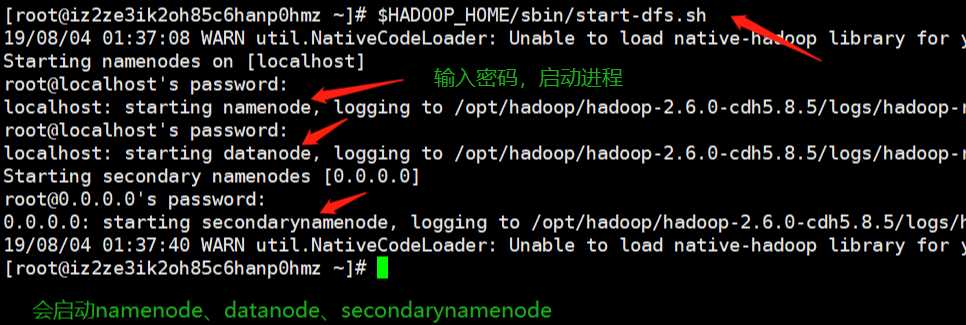
启动$HADOOP_HOME/sbin目录下的start-dfs.sh
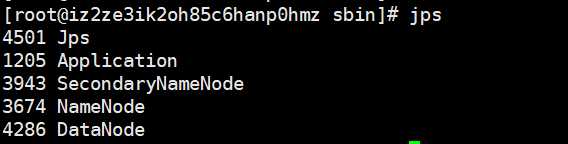
输入jps,会有如下进程,说明启动成功
启动yarn,yarn是一个资源管理器,我们也要将它启动起来,启动$HADOOP_HOME/sbin目录下的start-yarn.sh
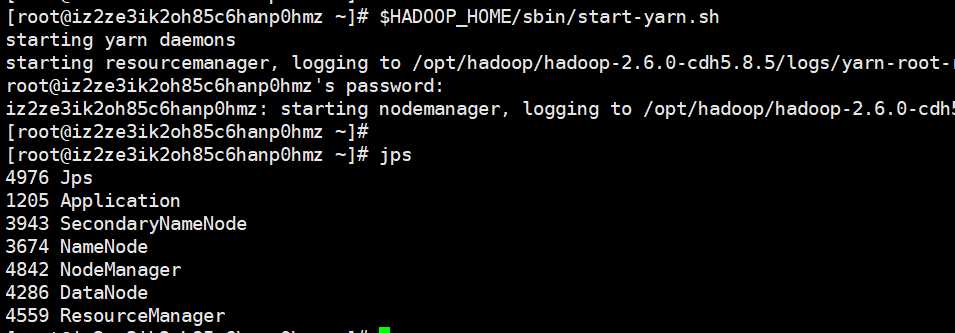
此时如果多出这些内容,表示执行成功
我们来操作一波
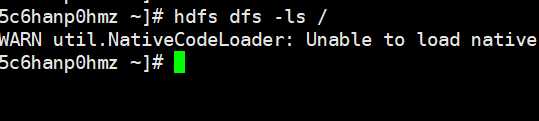
hdfs dfs -ls /:查看hdfs根目录的内容
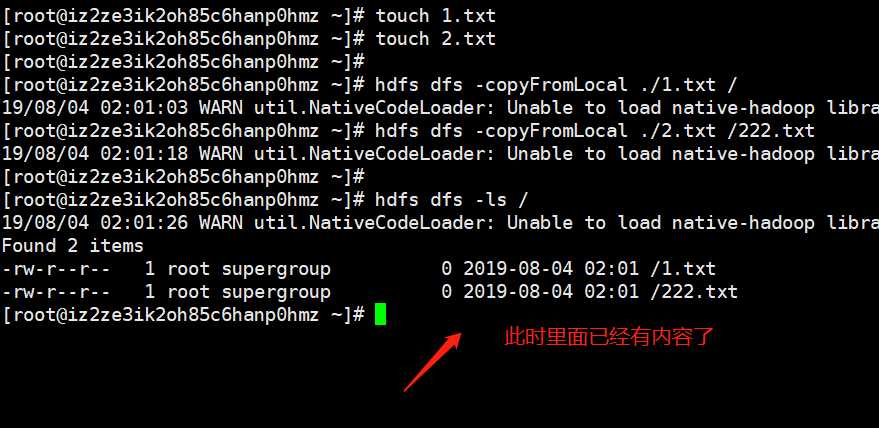
hdfs dfs -copyFromLocal 本地文件 hdfs路径:将本地文件拷贝到hdfs上面去
进入到/opt目录
tar -zxvf ./scala-2.13.0.tgz -C ./scala
export SCALA_HOME=/opt/scala/scala-2.13.0
export PATH=$SCALA_HOME/bin:$PATH
source ~/.bashrc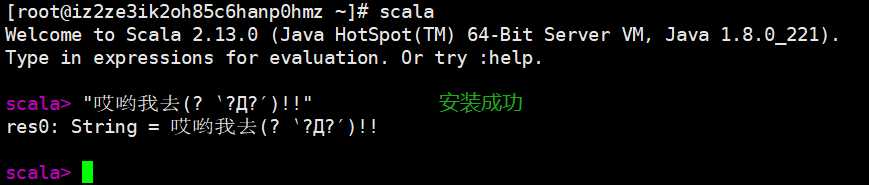
进入到/opt目录
tar -zxvf ./spark-2.4.3-bin-hadoop2.7.tgz -C ./spark
export SPARK_HOME=/opt/spark/spark-2.4.3-bin-hadoop2.7
export PATH=$SPARK_HOME/bin:$PATH
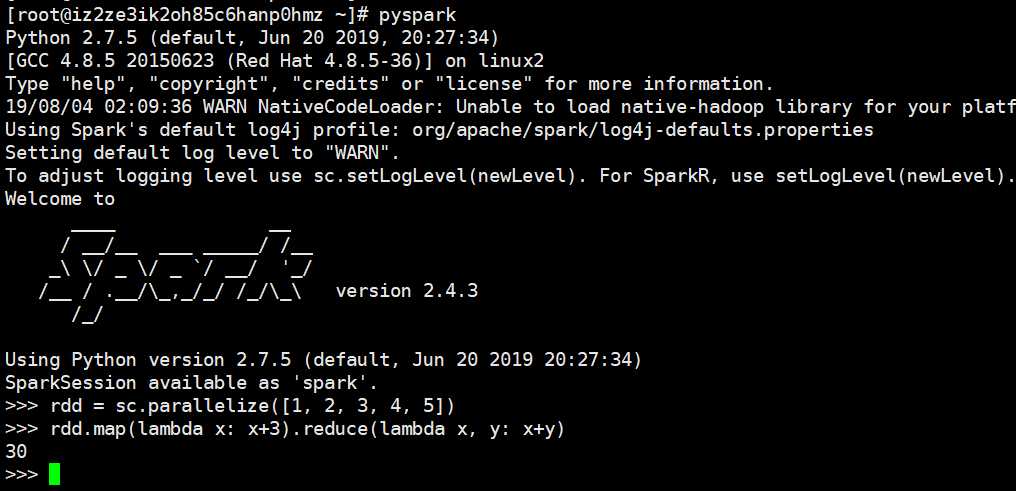
source ~/.bashrc输入pyspark,出现如下内容,说明配置成功
原文:https://www.cnblogs.com/traditional/p/11297049.html