When using Apache Kafka as a data source, each Kafka partition may have a simple event time pattern (ascending timestamps or bounded out-of-orderness). However, when consuming streams from Kafka, multiple partitions often get consumed in parallel, interleaving the events from the partitions and destroying the per-partition patterns (this is inherent in how Kafka’s consumer clients work).
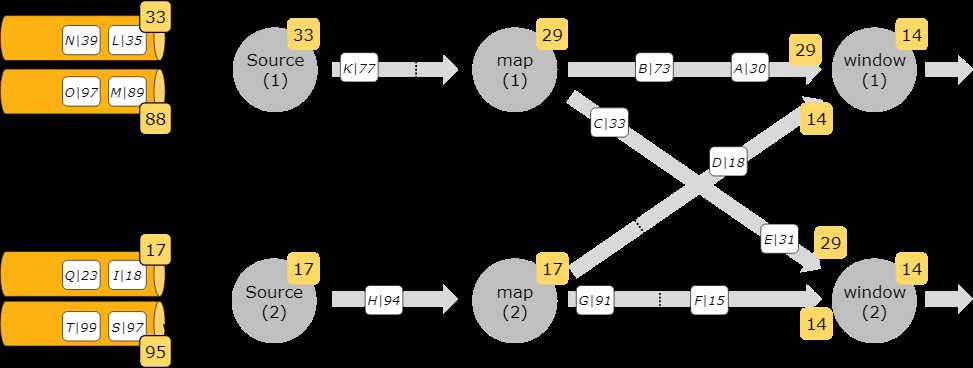
In that case, you can use Flink’s Kafka-partition-aware watermark generation. Using that feature, watermarks are generated inside the Kafka consumer, per Kafka partition, and the per-partition watermarks are merged in the same way as watermarks are merged on stream shuffles.
For example, if event timestamps are strictly ascending per Kafka partition, generating per-partition watermarks with the ascending timestamps watermark generator will result in perfect overall watermarks.
The illustrations below show how to use the per-Kafka-partition watermark generation, and how watermarks propagate through the streaming dataflow in that case.
FlinkKafkaConsumer09<MyType> kafkaSource = new FlinkKafkaConsumer09<>("myTopic", schema, props); kafkaSource.assignTimestampsAndWatermarks(new AscendingTimestampExtractor<MyType>() { @Override public long extractAscendingTimestamp(MyType element) { return element.eventTimestamp(); } });
DataStream<MyType> stream = env.addSource(kafkaSource);
原文:https://www.cnblogs.com/alu-bigdata/p/11312720.html