POJ 1743
题意:
有N(1 <= N <=20000)个音符的序列来表示一首乐曲,每个音符都是1~~88范围内的整数,现在要找一个重复的主题。“主题”是整个音符序列的一个子串,它需要满足如下条件:
1.长度至少为5个音符。
2.在乐曲中重复出现。(可能经过转调,“转调”的意思是主题序列中每个音符都被加上或减去了同一个整数值)
3.重复出现的同一主题在原序列中不能有重叠部分。
问题类型:
不可重叠最长重复子串
分析:
因为有转调问题,所以可以将相邻音符的差分数组去做 不可重叠最长重复子串
然后就转化为了后缀数组常用解题类型
(摘自罗穗骞的国家集训队论文):
先二分答案,把题目变成判定性问题:判断是否 存在两个长度为 k 的子串是相同的,
且不重叠。解决这个问题的关键还是利用 height 数组。把排序后的后缀分成若干组,
其中每组的后缀之间的 height 值都 不小于 k。例如,字符串为“aabaaaab”
,当 k=2 时,后缀分成了 4 组,如图 5 所示。
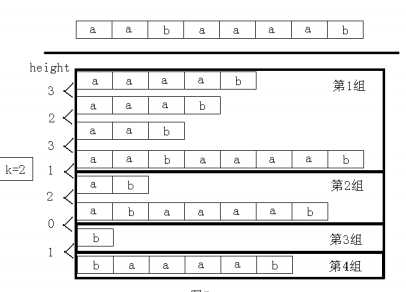
容易看出,有希望成为最长公共前缀不小于 k 的两个后缀一定在同一组。
然后对于每组后缀,只须判断每个后缀的 sa 值的最大值和最小值之差是否不小于 k。
如果有一组满足,则说明存在,否则不存在。整个做法的时间复杂度为 O(nlogn)。

1 #include <cstdio>
2 #include <cstring>
3 #include <queue>
4 #include <cmath>
5 #include <algorithm>
6 #include <set>
7 #include <iostream>
8 #include <map>
9 #include <stack>
10 #include <string>
11 #include <time.h>
12 #include <vector>
13 #define pi acos(-1.0)
14 #define eps 1e-9
15 #define fi first
16 #define se second
17 #define rtl rt<<1
18 #define rtr rt<<1|1
19 #define bug printf("******\n")
20 #define mem(a,b) memset(a,b,sizeof(a))
21 #define name2str(x) #x
22 #define fuck(x) cout<<#x" = "<<x<<endl
23 #define f(a) a*a
24 #define sf(n) scanf("%d", &n)
25 #define sff(a,b) scanf("%d %d", &a, &b)
26 #define sfff(a,b,c) scanf("%d %d %d", &a, &b, &c)
27 #define sffff(a,b,c,d) scanf("%d %d %d %d", &a, &b, &c, &d)
28 #define pf printf
29 #define FRE(i,a,b) for(i = a; i <= b; i++)
30 #define FREE(i,a,b) for(i = a; i >= b; i--)
31 #define FRL(i,a,b) for(i = a; i < b; i++)+
32 #define FRLL(i,a,b) for(i = a; i > b; i--)
33 #define FIN freopen("data.txt","r",stdin)
34 #define gcd(a,b) __gcd(a,b)
35 #define lowbit(x) x&-x
36 #define rep(i,a,b) for(int i=a;i<b;++i)
37 #define per(i,a,b) for(int i=a-1;i>=b;--i)
38
39 using namespace std;
40 typedef long long LL;
41 typedef unsigned long long ULL;
42 const int maxn = 1e5 + 7;
43 const int maxm = 8e6 + 10;
44 const int INF = 0x3f3f3f3f;
45 const int mod = 10007;
46
47 //rnk从0开始
48 //sa从1开始,因为最后一个字符(最小的)排在第0位
49 //height从1开始,因为表示的是sa[i - 1]和sa[i]
50 //倍增算法 O(nlogn)
51 int wa[maxn], wb[maxn], wv[maxn], ws_[maxn];
52 int Rank[maxn], height[maxn], sa[maxn], s[maxn];
53 int n;
54 //Suffix函数的参数m代表字符串中字符的取值范围,是基数排序的一个参数,如果原序列都是字母可以直接取128,如果原序列本身都是整数的话,则m可以取比最大的整数大1的值
55 //待排序的字符串放在r数组中,从r[0]到r[n-1],长度为n
56 //为了方便比较大小,可以在字符串后面添加一个字符,这个字符没有在前面的字符中出现过,而且比前面的字符都要小
57 //同上,为了函数操作的方便,约定除r[n-1]外所有的r[i]都大于0,r[n-1]=0
58 //函数结束后,结果放在sa数组中,从sa[0]到sa[n-1]
59 void Suffix ( int *r, int *sa, int n, int m ) {
60 int i, j, k, *x = wa, *y = wb, *t;
61 //对长度为1的字符串排序
62 //一般来说,在字符串的题目中,r的最大值不会很大,所以这里使用了基数排序
63 //如果r的最大值很大,那么把这段代码改成快速排序
64 for ( i = 0; i < m; ++i ) ws_[i] = 0;
65 for ( i = 0; i < n; ++i ) ws_[x[i] = r[i]]++; //统计字符的个数
66 for ( i = 1; i < m; ++i ) ws_[i] += ws_[i - 1]; //统计不大于字符i的字符个数
67 for ( i = n - 1; i >= 0; --i ) sa[--ws_[x[i]]] = i; //计算字符排名
68 //基数排序
69 //x数组保存的值相当于是rank值
70 for ( j = 1, k = 1; k < n; j *= 2, m = k ) {
71 //j是当前字符串的长度,数组y保存的是对第二关键字排序的结果
72 //第二关键字排序
73 for ( k = 0, i = n - j; i < n; ++i ) y[k++] = i; //第二关键字为0的排在前面
74 for ( i = 0; i < n; ++i ) if ( sa[i] >= j ) y[k++] = sa[i] - j; //长度为j的子串sa[i]应该是长度为2 * j的子串sa[i] - j的后缀(第二关键字),对所有的长度为2 * j的子串根据第二关键字来排序
75 for ( i = 0; i < n; ++i ) wv[i] = x[y[i]]; //提取第一关键字
76 //按第一关键字排序 (原理同对长度为1的字符串排序)
77 for ( i = 0; i < m; ++i ) ws_[i] = 0;
78 for ( i = 0; i < n; ++i ) ws_[wv[i]]++;
79 for ( i = 1; i < m; ++i ) ws_[i] += ws_[i - 1];
80 for ( i = n - 1; i >= 0; --i ) sa[--ws_[wv[i]]] = y[i]; //按第一关键字,计算出了长度为2 * j的子串排名情况
81 //此时数组x是长度为j的子串的排名情况,数组y仍是根据第二关键字排序后的结果
82 //计算长度为2 * j的子串的排名情况,保存到数组x
83 t = x;
84 x = y;
85 y = t;
86 for ( x[sa[0]] = 0, i = k = 1; i < n; ++i )
87 x[sa[i]] = ( y[sa[i - 1]] == y[sa[i]] && y[sa[i - 1] + j] == y[sa[i] + j] ) ? k - 1 : k++;
88 //若长度为2 * j的子串sa[i]与sa[i - 1]完全相同,则他们有相同的排名
89 }
90 }
91 void calheight ( int *r, int *sa, int n ) {
92 int i, j, k = 0;
93 for ( i = 1; i <= n; i++ ) Rank[sa[i]] = i;
94 for ( i = 0; i < n; height[Rank[i++]] = k )
95 for ( k ? k-- : 0, j = sa[Rank[i] - 1]; r[i + k] == r[j + k]; k++ );
96 }
97 bool judge ( int c ) {
98 int Max = sa[0], Min = sa[0];
99 for ( int i = 1; i <= n; i++ ) {
100 if ( height[i] >= c )
101 Max = max ( Max, sa[i] ), Min = min ( Min, sa[i] );
102 else
103 Max = sa[i], Min = sa[i];
104 if ( Max - Min >= c + 1 )
105 return true;
106 }
107 return false;
108 }
109 int main() {
110 while ( sf ( n ) && n ) {
111 int maxx = 0;
112 for ( int i = 0; i < n ; i++ ) {
113 sf ( s[i] );
114 if ( i ) s[i - 1] = s[i] - s[i - 1] + 88, maxx = max ( maxx, s[i - 1] );
115 }
116 s[n-1] = 0;
117 n--;
118 Suffix ( s, sa, n + 1, maxx + 1 );
119 calheight ( s, sa, n );
120 int low = 0, high = n, ans = 0;
121 while ( low <= high ) {
122 int mid = ( low + high ) / 2;
123 if ( judge ( mid ) ) {
124 low = mid + 1;
125 ans = mid;
126 } else high = mid - 1;
127 }
128 if ( ans < 4 ) printf ( "0\n" );
129 else printf ( "%d\n", ans + 1 );
130 }
131 return 0;
132 }
POJ 3261 Milk Patterns
题意:
给出一个字符串,求至少出现k次的可重叠的最长子串的长度
(摘自罗穗骞的国家集训队论文):
算法分析: 这题的做法和上一题差不多,也是先二分答案,然后将后缀分成若干组。
不同的是,这里要判断的是有没有一个组的后缀个数不小于 k。
如果有,那么存在 k 个相同的子串满足条件,否则不存在。这个做法的时间复杂度为 O(nlogn)。
1 #include <cstdio>
2 #include <cstring>
3 #include <queue>
4 #include <cmath>
5 #include <algorithm>
6 #include <set>
7 #include <iostream>
8 #include <map>
9 #include <stack>
10 #include <string>
11 #include <time.h>
12 #include <vector>
13 #define pi acos(-1.0)
14 #define eps 1e-9
15 #define fi first
16 #define se second
17 #define rtl rt<<1
18 #define rtr rt<<1|1
19 #define bug printf("******\n")
20 #define mem(a,b) memset(a,b,sizeof(a))
21 #define name2str(x) #x
22 #define fuck(x) cout<<#x" = "<<x<<endl
23 #define f(a) a*a
24 #define sf(n) scanf("%d", &n)
25 #define sff(a,b) scanf("%d %d", &a, &b)
26 #define sfff(a,b,c) scanf("%d %d %d", &a, &b, &c)
27 #define sffff(a,b,c,d) scanf("%d %d %d %d", &a, &b, &c, &d)
28 #define pf printf
29 #define FRE(i,a,b) for(i = a; i <= b; i++)
30 #define FREE(i,a,b) for(i = a; i >= b; i--)
31 #define FRL(i,a,b) for(i = a; i < b; i++)+
32 #define FRLL(i,a,b) for(i = a; i > b; i--)
33 #define FIN freopen("data.txt","r",stdin)
34 #define gcd(a,b) __gcd(a,b)
35 #define lowbit(x) x&-x
36 #define rep(i,a,b) for(int i=a;i<b;++i)
37 #define per(i,a,b) for(int i=a-1;i>=b;--i)
38
39 using namespace std;
40 typedef long long LL;
41 typedef unsigned long long ULL;
42 const int maxn = 1e5 + 7;
43 const int maxm = 8e6 + 10;
44 const int INF = 0x3f3f3f3f;
45 const int mod = 10007;
46
47 //rnk从0开始
48 //sa从1开始,因为最后一个字符(最小的)排在第0位
49 //height从1开始,因为表示的是sa[i - 1]和sa[i]
50 //倍增算法 O(nlogn)
51 int wa[maxn], wb[maxn], wv[maxn], ws_[maxn];
52 int Rank[maxn], height[maxn], sa[maxn], s[maxn];
53 int n, K;
54 //Suffix函数的参数m代表字符串中字符的取值范围,是基数排序的一个参数,如果原序列都是字母可以直接取128,如果原序列本身都是整数的话,则m可以取比最大的整数大1的值
55 //待排序的字符串放在r数组中,从r[0]到r[n-1],长度为n
56 //为了方便比较大小,可以在字符串后面添加一个字符,这个字符没有在前面的字符中出现过,而且比前面的字符都要小
57 //同上,为了函数操作的方便,约定除r[n-1]外所有的r[i]都大于0,r[n-1]=0
58 //函数结束后,结果放在sa数组中,从sa[0]到sa[n-1]
59 void Suffix ( int *r, int *sa, int n, int m ) {
60 int i, j, k, *x = wa, *y = wb, *t;
61 //对长度为1的字符串排序
62 //一般来说,在字符串的题目中,r的最大值不会很大,所以这里使用了基数排序
63 //如果r的最大值很大,那么把这段代码改成快速排序
64 for ( i = 0; i < m; ++i ) ws_[i] = 0;
65 for ( i = 0; i < n; ++i ) ws_[x[i] = r[i]]++; //统计字符的个数
66 for ( i = 1; i < m; ++i ) ws_[i] += ws_[i - 1]; //统计不大于字符i的字符个数
67 for ( i = n - 1; i >= 0; --i ) sa[--ws_[x[i]]] = i; //计算字符排名
68 //基数排序
69 //x数组保存的值相当于是rank值
70 for ( j = 1, k = 1; k < n; j *= 2, m = k ) {
71 //j是当前字符串的长度,数组y保存的是对第二关键字排序的结果
72 //第二关键字排序
73 for ( k = 0, i = n - j; i < n; ++i ) y[k++] = i; //第二关键字为0的排在前面
74 for ( i = 0; i < n; ++i ) if ( sa[i] >= j ) y[k++] = sa[i] - j; //长度为j的子串sa[i]应该是长度为2 * j的子串sa[i] - j的后缀(第二关键字),对所有的长度为2 * j的子串根据第二关键字来排序
75 for ( i = 0; i < n; ++i ) wv[i] = x[y[i]]; //提取第一关键字
76 //按第一关键字排序 (原理同对长度为1的字符串排序)
77 for ( i = 0; i < m; ++i ) ws_[i] = 0;
78 for ( i = 0; i < n; ++i ) ws_[wv[i]]++;
79 for ( i = 1; i < m; ++i ) ws_[i] += ws_[i - 1];
80 for ( i = n - 1; i >= 0; --i ) sa[--ws_[wv[i]]] = y[i]; //按第一关键字,计算出了长度为2 * j的子串排名情况
81 //此时数组x是长度为j的子串的排名情况,数组y仍是根据第二关键字排序后的结果
82 //计算长度为2 * j的子串的排名情况,保存到数组x
83 t = x;
84 x = y;
85 y = t;
86 for ( x[sa[0]] = 0, i = k = 1; i < n; ++i )
87 x[sa[i]] = ( y[sa[i - 1]] == y[sa[i]] && y[sa[i - 1] + j] == y[sa[i] + j] ) ? k - 1 : k++;
88 //若长度为2 * j的子串sa[i]与sa[i - 1]完全相同,则他们有相同的排名
89 }
90 }
91 void calheight ( int *r, int *sa, int n ) {
92 int i, j, k = 0;
93 for ( i = 1; i <= n; i++ ) Rank[sa[i]] = i;
94 for ( i = 0; i < n; height[Rank[i++]] = k )
95 for ( k ? k-- : 0, j = sa[Rank[i] - 1]; r[i + k] == r[j + k]; k++ );
96 }
97 bool judge ( int mid ) {
98 int cnt = 0;
99 for ( int i = 1; i <= n; i++ ) {
100 if ( height[i] >= mid ) cnt++;
101 else cnt = 0;
102 if ( cnt+1 >= K ) return true;
103 }
104 return false;
105 }
106 int main() {
107 while ( ~sff ( n, K ) ) {
108 int maxx = 0;
109 for ( int i = 0; i < n ; i++ ) sf ( s[i] ), maxx = max ( maxx, s[i] );
110 s[n] = 0;
111 Suffix ( s, sa, n + 1, maxx + 1 );
112 calheight ( s, sa, n );
113 int low = 0, high = n, ans = 0;
114 while ( low <= high ) {
115 int mid = ( low + high ) / 2;
116 if ( judge ( mid ) ) {
117 low = mid + 1;
118 ans = mid;
119 } else high = mid - 1;
120 }
121 printf ( "%d\n", ans );
122 }
123 return 0;
124 }
POJ 1743-POJ - 3261~后缀数组关于最长字串问题
原文:https://www.cnblogs.com/qldabiaoge/p/11329879.html
