目录
Liwen Zheng, Canmiao Fu, Yong Zhao. Extend the shallow part of Single Shot MultiBox Detector via Convolutional Neural Network. arXiv 2018.
https://arxiv.org/abs/1801.05918
本文使用Microsoft Word编辑后转换得来的PDF格式, 一开始还觉得挺正常, 后来看各种数学公式越看越奇怪, 最后查看属性发现并不是LaTex生成, 请问你是想笑死我吗, 作为北大的研究生你写论文学着用用LaTex真的很难吗.
上图的是本文的属性信息, 下图是LaTex生成的属性信息.
本文真的短, 实际行文只有一般文章的三分之一到四分之一, 我大概只用了三十分钟左右就读了一遍, 读的快一方面也说明文章内信息量有限, 简单来说就是接着DSSD的思路主要从速度上提升, 本文比较有意思的内容是提出了一种新的衡量网络深度方法.
作者认为DSSD网络深不说还加入了一些其他层, 严重拖累速度.
为了获得更好地性能, 作者以SSD为base net, 对于SSD的前三层, 作者加入了自己设计的module, 网络整体结构如下图所示:
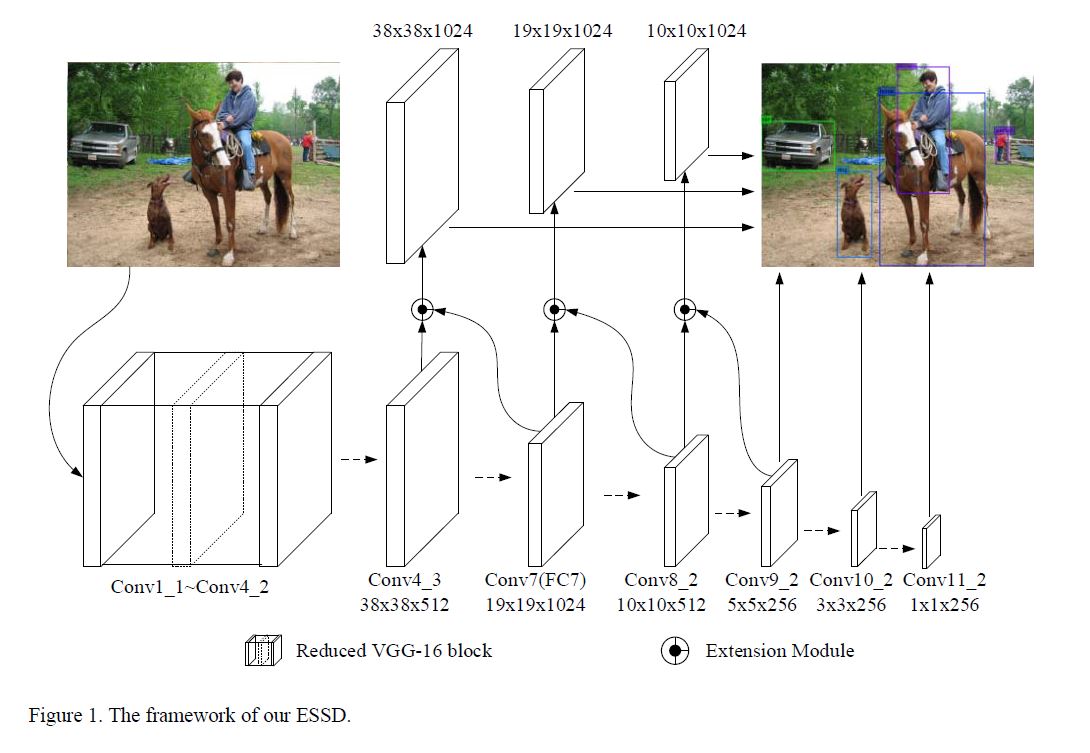
可以看的出这个新加入的结构利用了前后层的网络输出.
首先base net基本形式没得多说的.
虽然反卷积能比较好的提取语义信息, 但是过多的反卷积却会导致运算量过大. 那么设计一个合适数量的反卷积结构, 也许就能保证有足够语义信息的条件下还不会损失太多速度. 如上文所说, 作者设计使用个包含反卷积的模块以期望达到目的, 模块细节如下图所示:
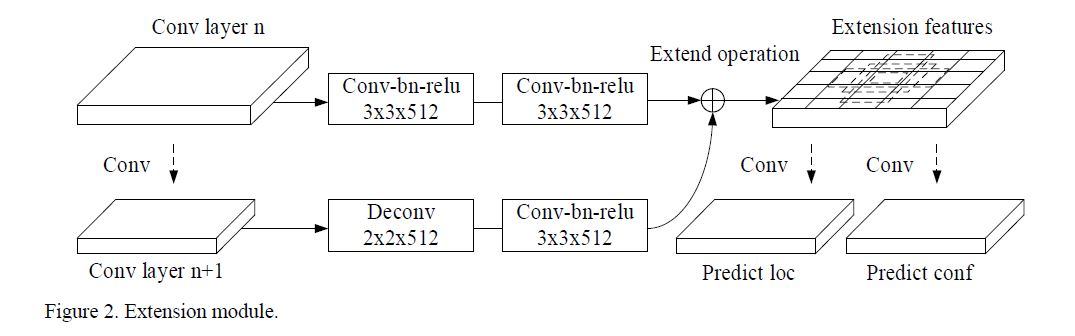
该模块左边是正常主线, 前一层(n)卷积得到后一层(n + 1), 后层通过反卷积与前一层尺寸保持一致, 这里我想提一下卷积核是\(3 \times 3\), stride = 1, padding = 1卷积后尺寸不变. 将二者网络组合, 方法有对应元素相加相减相乘, 后来实验证明加法最好. 受DSSD的启发, 作者虽然没明确说, 但应该是对prediction加入了\(1 \times 1 \times 512\)的skip.
作者提出一种表示相对深度的方法, 定义如下:
\[
\bar{D}(L_n) = \left\{
\begin{aligned}
1 && \text{if layer n directly connected to data,}\\sum\limits_{i = 1}^k L_n^kw_i && \text{otherwise.}
\end{aligned}
\right.
\]
我带大家分析以下, 当本层直接与数据相连, 那么他的深度就是1, 如果没有直接相连那么就对之前各层的深度递归加权求和, 其中权重是这样定义的, 如果该层来自组合层就是上图中的那个十字圆形, 那么权重为0.5, 否则为1. 最终递归得到各层的深度.
语义信息相仿的层深度一般相近, 作者用这种方法测试了SSD和ESSD的深度:
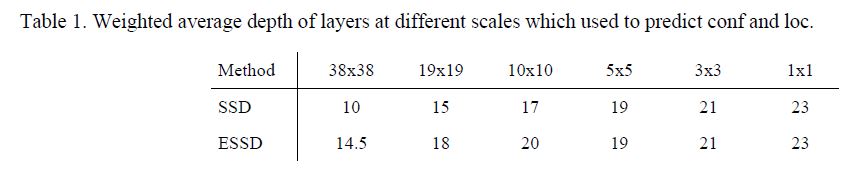
明显SSD的方差大于ESSD, 那么结论也很明显, SSD各层语义信息差异较大, 尤其浅层分辨率虽然较高但是语义信息较少, 效果较差也很正常.
训练流程是首先训练SSD, 其后freeze SSD后训练增加的网络, 最终综合fine-tune整个网络, 最终结果如下:
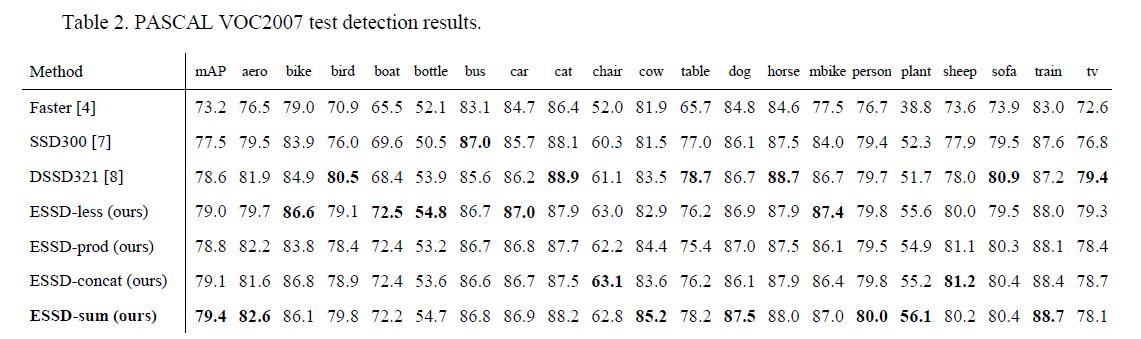
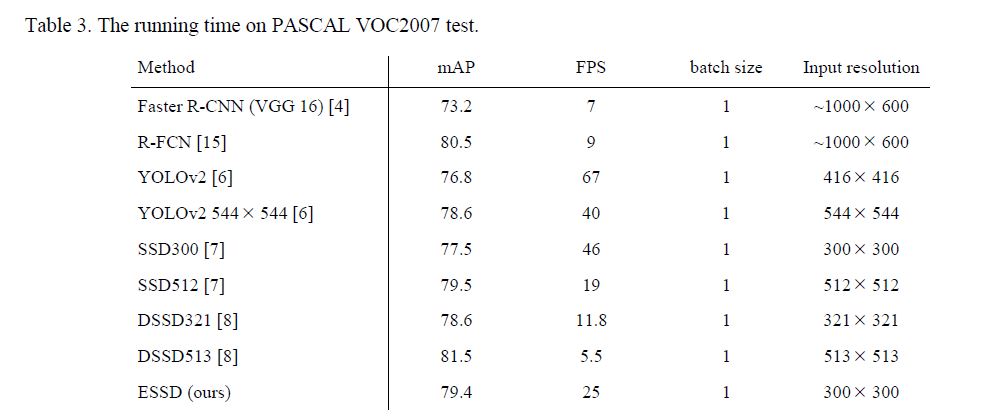
确实速度精度都好很多, 下图有几张演示:
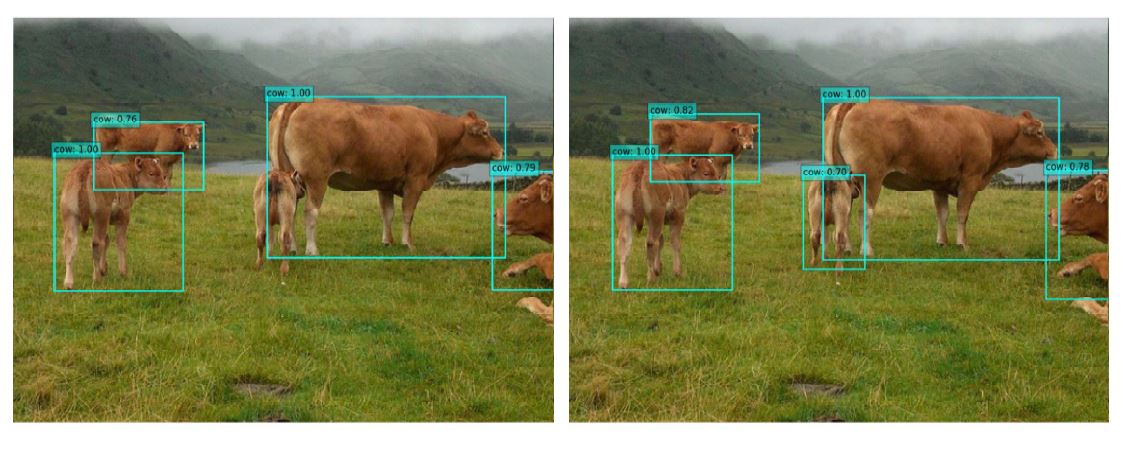

但本文方法创新性有限, 但提出的Weighted average depth确实衡量网络语义层次有价值.
原文:https://www.cnblogs.com/edbean/p/11335879.html