目录
1.findall(查找返回):
1.找出字符串中符合正则的内容
2.返回列表,列表中是正则表达匹配的内容
2.search(往后查找,搜索) :
1.返回一个对象,必须调用group才能看到结果
2.根据正则查找一次,只要查到结果就不会往后查找
3.当查找结果不存在(返回的None),再调用group直接报错,因为none没有group方法
3.match(匹配开头):
1.match匹配字符串开头
2.没有同样返回None
3.同样调用group报错
其他方法:
4.split(切割)
5.sub(替换,指定替换个数)
6.subn(替换,返回元组)
7.compile(编译成对象)
8.finditer(迭代)
9.分组,起别名: ?P<别名>
1.findall(全文查找返回):
res = re.findall(‘a‘,‘asd jeff ball‘)
res1 = re.findall(‘a-z+‘,‘asd jeff ball‘)
print(res1)
2.search(从上至下查找):
res2 = re.search(‘a‘,‘asd jeff ball‘)
if res2:
print(res2.group())
3.match(匹配开头):
res3 = re.match(‘a‘,‘asd jeff ball‘)
if res3:
print(res3.group())
4.split(切割):
ret = re.split(‘[ab]‘, ‘abcd‘) # 先按‘a‘分割得到‘‘和‘bcd‘,在对‘‘和‘bcd‘分别按‘b‘分割
print(ret) # [‘‘, ‘‘, ‘cd‘]
5.sub(替换)
ret = re.sub(‘999‘, ‘H‘, ‘jeff age max 999 8884‘, 2) # 将数字替换成‘H‘,参数1表示只替换1个
print(ret) # evaHegon4yuan4
6.subn(替换,返回元组)
ret = re.subn(‘\d‘, ‘H‘, ‘eva3egon4yuan4‘) # 将数字替换成‘H‘,返回元组(替换的结果,替换了多少次)
print(ret)
7.compile(正则封装为对象)
obj = re.compile(‘\d{3}‘) #将正则表达式编译成为一个 正则表达式对象,规则要匹配的是3个数字
ret = obj.search(‘abc123eeee‘) #正则表达式对象调用search,参数为待匹配的字符串
print(ret.group()) #结果 : 123
8.finditer(迭代)
ret = re.finditer(‘\d‘, ‘ds3sy4784a‘) #finditer返回一个存放匹配结果的迭代器
print(ret) # <callable_iterator object at 0x10195f940>
print(next(ret).group()) #查看第一个结果
print(next(ret).group()) #查看第二个结果
print([i.group() for i in ret]) #查看剩余的左右结果
9.分组
res = re.search(‘^[1-9]\d{14}(\d{2}[0-9x])?$‘,110105199812067023
print(res)
print(res.group(1)) # 获取正则表达式括号阔起来分组的内容
print(res.group(2)) # search与match均支持获取分组内容的操作 跟正则无关是python机制
10.起别名:
re.search(‘^[1-9]?P
print(res.group(passwd))
在线测试工具 http://tool.chinaz.com/regex/
整则表达式符号:
A-Z:匹配大写A至Z的字母
. :出换行符的任意字符
\w:匹配字母数字下划线 单词word
\s : 匹配空白符 单词space
\d:匹配数字
\W:匹配除字母数字下划线
\S:匹配除空白符
\D:匹配除数字
\n:匹配换行符
\t:匹配制表符
\b:以什么什么结尾的单词 eg:n\b————表示以n结尾的单词 还可以:tion\b以tion结尾的单词
$ :p匹配字符串的结尾 eg:[0-9x]$: 表示以0-9或x结尾的 tion$ :以tion结尾的字符串
注意:^与$连用,叫精确匹配,中间写什么匹配什么。 eg: ^jeff$ :匹配jeff,以jeff开头并以jeff结尾
a|b :匹配字符a或b eg(错误):ab|abc:先匹配ab,abc就匹配不到了。eg(正确):eg:abc|ab :先匹配abc,再匹配ab,都能匹配到。将长的放在前面
():匹配括号里的表达式,表示一个组
^ :匹配字符串的开头 eg:^0-9:表示以0至9开头的 ^art :以art开头
[^...]:表示非,除了字符组中的所有字符。 eg:[^ab]:匹配所有除了ab的字符
量词:
1.必须跟在正则表达后
2.量词只能限制紧挨着的一个表达
:重复零次或多次
+:一次或多次
?:零次或一次
{n}:表示重复n次 eg: \d{11}————匹配11位数字
{n,}:重复n次或更多次
{n,m}:重复n到m次 eg:\d{2,5}————匹配2位至5位的数字
取消贪婪匹配:
贪婪匹配:默认都是贪婪匹配。贪婪匹配都是取大,比如: 表示更多次、+表示多次、?表示一次,当然这只是默认的,当默认贪婪匹配不到,就会表示零次、+表示一次、?表示零次
取消贪婪匹配:量词后面加问号(?)。 eg: 待匹配:李杰和李莲英和李二棍子 正则表达式:李.+? 结果:李杰 李莲 李二 ,因为+后面跟了?,所以+表示一次
转义符:
? : 取消转义
eg: \n 表示\n
import : 导入模块
from 模块名 import ...
import 就相当于:把超市给我
from 超市 import 矿泉水:把超市里的矿泉水给我
例子1:不会报错
import aaa
aaa.func1()
aaa.func2()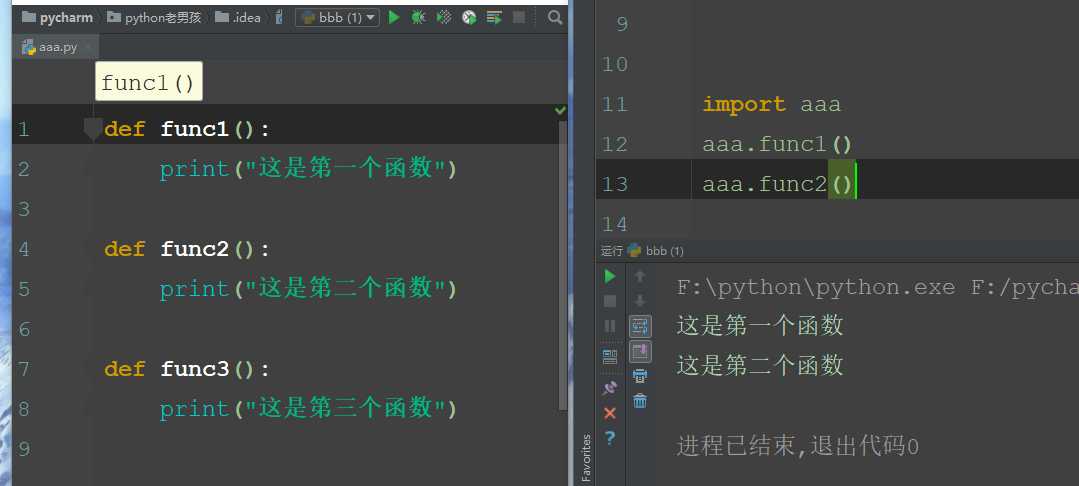
例子2:报错,因为没有导入func2
from aaa import func1
func1()
func2()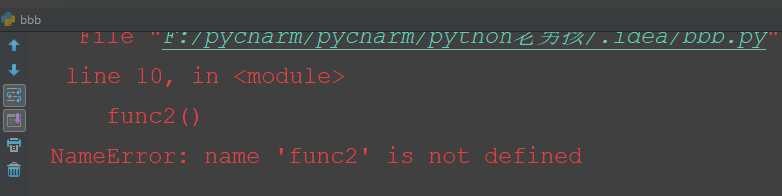
模块就是一系列的功能结合体:
模块的三种来源:
1.内置的模块(pycharm内置自带的)
2.第三方的(别人写的)
3.自定义的(自己写的)
1.在python编程中,写程序的时候尽量多去调用模块来完成功能,因为这是python的特点,这样效率高,速度快,提高开发效率
2.当程序比较庞大的时候,需要用模块的形式将庞大的程序一步步拆分,更加的详细清楚
1.先从内存中查找
2.pycharm内置中找
3.sys.path中找(环境变量)
‘.’点代表当前路径
‘..’点点代表上一级路径
‘...’点点点代表上上一级路径
注意:
相对导入不能在执行文件中使用,只能在被导入的模块中使用,相对导入需要知道模块与模块之间的路径关系
1.namedtuple 具名元组(给元组取名)
2.deque 双端队列(左中右添加值,左右取值)
3.OrderedDict 有序字典
4.Counter方法(计算计算字符串的每个字符的个数,并以字典返回)
from collections import namedtuple
point = namedtuple('坐标', ['x', 'y', 'z'])
p = point(2, 5, 8)
print(p)
print(p.x)
print(p.y)
print(p.z)
结果:坐标(x=2, y=5, z=8) 2 5 8from collections import namedtuple
card = namedtuple('扑克牌', 'color number')
A = card('?', 'A')
print(A)
print(A.color)
print(A.number)
结果:扑克牌(color='?', number='A') ? Aimport queue
q = queue.Queue() # 生成队列对象
q.put('one') # 传值
q.put('two')
q.put('three')
print(q.get()) # 朝着队列要值,如果取完了,程序原地等待(不结束)
print(q.get())
print(q.get())
print(q.get())四个方法:
1.append 尾部追加
2.appendleft 左边追加
3.pop 末尾取值
4.popleft 左边取值
5.insert(索引,‘值‘) 根据索引插值
from collections import deque
q = deque(['a', 'b', 'c'])
q.append('尾')
q.appendleft('左')
q.insert(1, '插') # 在索引1位置插入
print(q.pop()) # 结果: 尾
print(q.popleft()) # 结果: 左
print(q.popleft()) # 结果: 插from collections import OrderedDict
k = OrderedDict()
k['x'] = 1 # 给固定的键传值
k['y'] = 2
k['z'] = 3
表现:
print(k)
for i in k:
print(i)k = 'abcaabca'
d = {}
# 字典的key是固定的,先建一个值为0的字典
for i in k:
d[i] = 0
# 每个字符和字典的key作比较,有就加1
for q in k:
for n in d:
if n == q:
d[q] += 1
print(d)
2.Counter方法
from collections import Counter
k = 'abcaabca'
res = Counter(k)
print(res)import time
print(time.time()) # 距离1970.01.01的秒数
print(time.strftime('%Y-%m-%d %H:%M:%S')) # 拼接时间格式
print(time.localtime())
time.sleep(3) # 程序暂停3秒import datetime
print(datetime.date.today()) # 年月日
print(datetime.datetime.today()) # 年月日 时分秒
res = datetime.date.today()
res1 = datetime.datetime.today()
print(res.year) # 年
print(res.month) # 月
print(res.day) # 日
print(res.weekday()) # 第几个星期(从0开始)
print(res.isoweekday()) # 第几个星期(从1开始)# 时间计算
import datetime
a = datetime.datetime(2019, 12, 15, 5, 5, 5)
b = datetime.datetime.today()
print(a-b) # 现在时间-指定时间
UTC时间:
import datetime
a = datetime.datetime.today()
b = datetime.datetime.now()
c = datetime.datetime.utcnow() #一区时间,上海东八区
print(a)
print(b)
print(c)# 随机模块
import random
print(random.randint(0, 9)) # 随机取一个0-9的数字,包含头尾
print(random.random) # 取0-1之间的小数
print(random.choice([1, 2, 3, 4])) # 随机从列表中取一个值打乱顺序shuffle:
res = [1, 2, 3, 4, 5]
random.shuffle(res) # 打乱列表的顺序
print(res)
# 生成随机验证码
a = str(random.randint(0, 9)) # 转成字符串型,才可以相加拼接
b = chr(random.randint(65, 90)) # 大写字母 65-90
c = chr(random.randint(97, 122)) # 小写字母 97-122
# print(a, b, c)
k = ''
for i in range(5):
m = random.choice([a, b, c])
k += m # 让字符串相加,而不是数字
print(k)
m = random.randint(0, 9)
print(type(a))
print(type(m))import sys
sys.path.append() # 将某个路径添加到环境变量中
print(sys.platform) # 查看当前操作系统
print(sys.version) # python解释器的版本
print(sys.argv) # 命令启动文件 可以做身份验证
subprocess 子进程模块
"""
sub :子
process:进程
"""
例子1:
输出cmd命令并返回结果:
while True:
cmd = input('cmd>>>:').strip()
import subprocess
obj = subprocess.Popen(cmd,shell=True,stdout=subprocess.PIPE,stderr=subprocess.PIPE)
print('正确命令返回结果stdout',obj.stdout.read().decode('gbk'))
print('错误命令返回的提示信息stdout',obj.stdout.read().decode('gbk'))json:可以和其他语言玩
pickle:只能和自己(python)玩
dumps(转): 将其他数据类型转成json格式的字符串
loads(解): 将json格式字符串转换成其他数据类型
dump(转文件): 将其他数据类型转成json格式的字符串
load(解文件): 将json格式字符串转换成其他数据类型
ensure_ascii=False False表示字典中的汉字不转,Turn表示转中文,默认为Trun
优点: 1.所有语言都支持json格式
缺点: 2.支持的数据类型少
pickle()
优点: 1.python所有数据类型都支持
缺点: 2.只支持python
序列化:
序列:字符串
序列化:其他数据类型转成字符串的过程
序列化:其他数据类型转成字符串的过程
反序列化:字符串转成其他数据类型
注意:
写入文件的数据必须是字符串(二进制)
基于网络传输的数据必须是二进制
例子1:
将字典转换成字符串:k = {‘name‘: ‘jeff‘}
res = json.dumps(k)
print(res) # 结果:{"name": "jeff"}
print(res, type(res)) # 结果:{"name": "jeff"} <class ‘str‘>
将上面的字符串转为字典:
res1 = json.loads(res)
print(res1, type(res1)) 结果:{'name': 'jeff'} <class 'dict'>例子2:对文件的中的内容转换:
转换类型,并写入文件:
d = {"name":"jeff"}
with open(r'userinfo','w',encoding='utf-8') as f:
json.dump(d, f) # 转字符,并自动写入文件读取内容,并解为python类型:
with open(r'userinfo', 'r', encoding='utf-8') as f:
res = json.load(f) # 解字符,并读取
print(res, type(res))例子3:
ensure_ascii=False 表示字典中的汉字不转
中文不转码:
d = {'name': '辜老板'}
print(json.dumps(d, ensure_ascii=False)) # ensure_ascii=False识别中文不转码
#结果:{"name": "辜老板"}中文转码:
d = {'name': '辜老板'}
print(json.dumps(d, ensure_ascii=True)) # ensure_ascii=False识别中文不转码
# 结果:{"name": "\u8f9c\u8001\u677f"} 中文转码了hashlib加密模块:不可逆,但是可以撞库
md.update(‘数据‘): 没有提示,记住单词
md.hexdigest() :获取密文,记住单词
hashlib加盐:用手动传入假数据(动态)和真数据混合在一起加密
MD5:常用加密算法
1.密码的密文储存
2.校验文件内容是否一致
1.加密:
md = hashlib.md5() # 加密,不可逆
md.update('hello'.encode('utf-8')) # 往对象里传数据加密 ,update只能接受bytes类型
md.update(b'hello')
print(md.hexdigest())
结果:23b431acfeb41e15d466d75de822307c2.加盐加密:自己添加的东西和客户的真密码一起加密,自己添加的东西可以是动态的
2.加盐 :自己添加的东西和客户的真密码一起加密,自己添加的东西可以是动态的
md = hashlib.md5()
md.update(b'yan.com')
md.update(b'hello') # 加密
print(md.hexdigest()) # 获取密文例子1:给客户输入的密码加盐加密
import hashlib
# 加盐
def get_md5(date):
md = hashlib.md5()
md.update('加盐'.encode('utf-8'))
md.update(date.encode('utf-8'))
return md.hexdigest()
password = input('password>>>:')
res = get_md5(password)
print(res)原文:https://www.cnblogs.com/guyouyin123/p/11344354.html