当年肥工的DB课讲的其实还挺好的...就用当时的笔记叭
(所以当年为什么不整理呢?还是懒叭
完整性:防止DB中存在不符合规定的数据(eg:性别只能是男或女)
实体完整性:primary key中的属性取值必须唯一且不能为空
参照完整性:若F是R的外码(foreign key),K是S的主码(primary key),F连接K。那么对于R中的每个元祖,R.F必须是 在S.K中出现过的值 或者 NULL
用户定义的完整性:用户自己在具体的DB中指定的约束(定义:NOT NULL / UNIQUE / CHECK)
触发器:用于实现用户定义的完整性 CREATE TRIGGER ON ... AFTER ...
存储过程:用SQL语句实现一些用户定义的业务逻辑
关系模型
(略)
(略)
B+Tree
B Tree 指的是 Balance Tree,也就是平衡树。平衡树是一颗查找树,并且所有叶子节点位于同一层。
B+ Tree 是基于 B Tree 和叶子节点顺序访问指针进行实现,它具有 B Tree 的平衡性,并且通过顺序访问指针来提高区间查询的性能。
在 B+ Tree 中,一个节点中的 key 从左到右非递减排列,如果某个指针的左右相邻 key 分别是 keyi 和 keyi+1,且不为 null,则该指针指向节点的所有 key 大于等于 keyi 且小于等于 keyi+1。

进行查找操作时,首先在根节点进行二分查找,找到一个 key 所在的指针,然后递归地在指针所指向的节点进行查找。直到查找到叶子节点,然后在叶子节点上进行二分查找,找出 key 所对应的 data。
插入删除操作会破坏平衡树的平衡性,因此在插入删除操作之后,需要对树进行一个分裂、合并、旋转等操作来维护平衡性。
与红黑树的比较
红黑树等平衡树也可以用来实现索引,但是文件系统及数据库系统普遍采用 B+ Tree 作为索引结构,主要有以下两个原因:
(一)更少的查找次数
平衡树查找操作的时间复杂度和树高 h 相关,O(h)=O(logdN),其中 d 为每个节点的出度。
红黑树的出度为 2,而 B+ Tree 的出度一般都非常大,所以红黑树的树高 h 很明显比 B+ Tree 大非常多,查找的次数也就更多。
(二)利用磁盘预读特性
为了减少磁盘 I/O 操作,磁盘往往不是严格按需读取,而是每次都会预读。预读过程中,磁盘进行顺序读取,顺序读取不需要进行磁盘寻道,并且只需要很短的磁盘旋转时间,速度会非常快。
操作系统一般将内存和磁盘分割成固定大小的块,每一块称为一页,内存与磁盘以页为单位交换数据。数据库系统将索引的一个节点的大小设置为页的大小,使得一次 I/O 就能完全载入一个节点。并且可以利用预读特性,相邻的节点也能够被预先载入。
B+ Tree、LSM Tree:https://www.cnblogs.com/pdev/p/11277784.html
MYSQL:http://blog.codinglabs.org/articles/theory-of-mysql-index.html
Hash:https://www.cnblogs.com/pdev/p/11332264.html
红黑树:https://www.jianshu.com/p/e136ec79235c
索引的优点
索引的使用条件
事务指的是满足 ACID 特性的一组操作,可以通过 Commit 提交一个事务,也可以使用 Rollback 进行回滚。一个事务包含了多个命令,服务器在执行事务期间,不会改去执行其它客户端的命令请求。事务是并发控制的基本单位
事务中的多个命令被一次性发送给服务器,而不是一条一条发送,这种方式被称为流水线,它可以减少客户端与服务器之间的网络通信次数从而提升性能。
ACID特性:

恢复:
事务是并发控制的基本单位。
并发一致性问题
在并发环境下,事务的隔离性很难保证,因此会出现很多并发一致性问题。解决方法是通过并发控制来保证隔离性。并发控制可以通过封锁来实现,但是封锁操作需要用户自己控制,相当复杂。数据库管理系统提供了事务的隔离级别,让用户以一种更轻松的方式处理并发一致性问题。
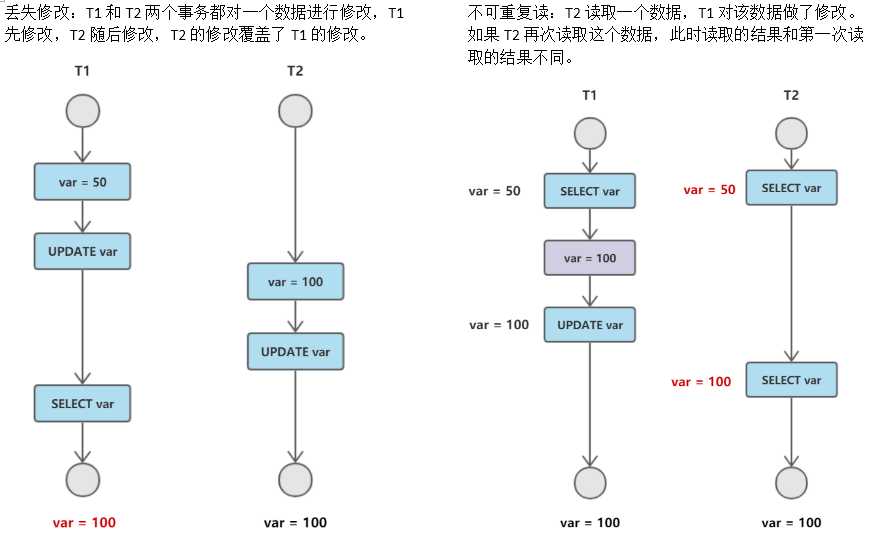
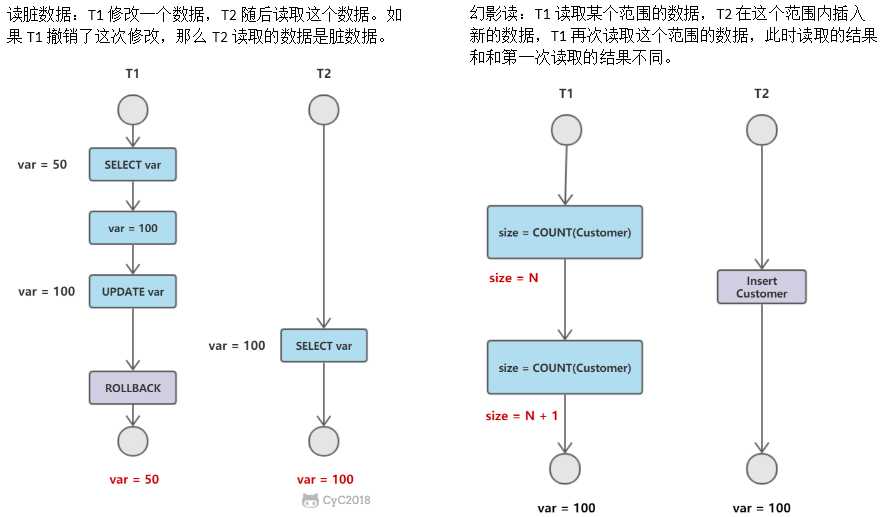
并发控制主要技术:封锁、时间戳、乐观控制法、多版本并发控制等。
基本封锁类型:排他锁(X 锁 / 写锁)、共享锁(S 锁 / 读锁)。
封锁:
活锁:某个事务等待时间太长,可通过先来先服务的策略避免。
死锁:事务永远无法完成,同OS中的死锁
可串行化调度:多个事务的并发执行是正确的,当且仅当其结果与按某一次序串行地执行这些事务时的结果相同。可串行性是并发事务正确调度的准则。
切分
水平切分:水平切分又称为 Sharding,它是将同一个表中的记录拆分到多个结构相同的表中。
当一个表的数据不断增多时,Sharding 是必然的选择,它可以将数据分布到集群的不同节点上,从而缓存单个数据库的压力。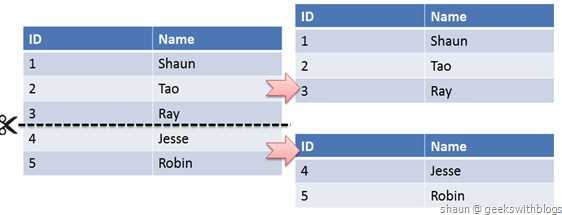
垂直切分:将一张表按列切分成多个表,通常是按照列的关系密集程度进行切分,也可以利用垂直切分将经常被使用的列和不经常被使用的列切分到不同的表中。
在数据库的层面使用垂直切分将按数据库中表的密集程度部署到不同的库中,例如将原来的电商数据库垂直切分成商品数据库、用户数据库等。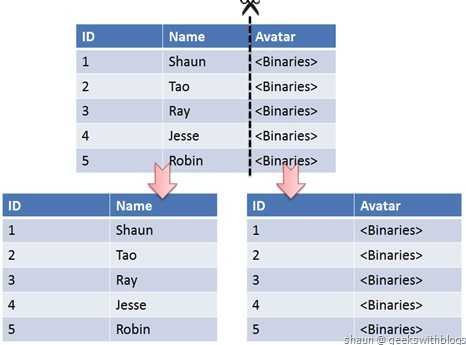
Sharding 策略
哈希取模:hash(key) % N;
范围:可以是 ID 范围也可以是时间范围;
映射表:使用单独的一个数据库来存储映射关系。
Sharding 存在的问题
1. 事务问题 使用分布式事务来解决,比如 XA 接口。
2. 连接 可以将原来的连接分解成多个单表查询,然后在用户程序中进行连接。
3. ID 唯一性 使用全局唯一 ID(GUID)、为每个分片指定一个 ID 范围、分布式 ID 生成器 (如 Twitter 的 Snowflake 算法)
主从复制
主要涉及三个线程:binlog 线程、I/O 线程和 SQL 线程。

读写分离
主服务器处理写操作以及实时性要求比较高的读操作,而从服务器处理读操作。读写分离能提高性能的原因在于:
读写分离常用代理方式来实现,代理服务器接收应用层传来的读写请求,然后决定转发到哪个服务器。

https://github.com/CyC2018/CS-Notes/blob/master/notes/%E6%95%B0%E6%8D%AE%E5%BA%93%E7%B3%BB%E7%BB%9F%E5%8E%9F%E7%90%86.md
https://github.com/huihut/interview#-%E6%95%B0%E6%8D%AE%E5%BA%93
https://github.com/CyC2018/CS-Notes/blob/master/notes/MySQL.md
https://github.com/CyC2018/CS-Notes/blob/master/notes/Redis.md
原文:https://www.cnblogs.com/pdev/p/11330788.html