这周在工作中遇到一个SQL查询行转列的问题,在网上搜了下,找到了一些案例,自己试着写了下,希望对朋友们有所帮助!
目录结构如下:
[一]、行转列
1.1、初始测试数据
表结构:TEST_TB_GRADE
初始数据如下图:

1.2、 如果需要实现如下的查询效果图:

这就是最常见的行转列,主要原理是利用decode函数、聚集函数(sum),结合group by分组实现的,具体的sql如下:
1.3、延伸
如果要实现对各门功课的不同分数段进行统计,效果图如下:

具体的实现sql如下:
[二]、列转行
1.1、初始测试数据
表结构:TEST_TB_GRADE2
初始数据如下图:

1.2、 如果需要实现如下的查询效果图:

这就是最常见的列转行,主要原理是利用SQL里面的union,具体的sql语句如下:
也可以利用【 insert all into ... select 】来实现,首先需要先建一个表TEST_TB_GRADE3:
再执行下面的sql:
别忘记commit操作,然后再查询TEST_TB_GRADE3,发现表中的数据就是列转成行了。
本文连接:http://sjsky.iteye.com/blog/1152167
以上转载自网上的一篇博客,本人对decode()函数也不是很了解,于是又去百度了下decode()函数
decode()函数简介:
主要作用:将查询结果翻译成其他值(即以其他形式表现出来,以下举例说明);
使用方法:
Select decode(columnname,值1,翻译值1,值2,翻译值2,...值n,翻译值n,缺省值)
From talbename
Where …
其中columnname为要选择的table中所定义的column,
·含义解释:
decode(条件,值1,翻译值1,值2,翻译值2,...值n,翻译值n,缺省值)的理解如下:
if (条件==值1)
then
return(翻译值1)
elsif (条件==值2)
then
return(翻译值2)
......
elsif (条件==值n)
then
return(翻译值n)
else
return(缺省值)
end if
注:其中缺省值可以是你要选择的column name 本身,也可以是你想定义的其他值,比如Other等;
举例说明:
现定义一table名为output,其中定义两个column分别为monthid(var型)和sale(number型),若sale值=1000时翻译为D,=2000时翻译为C,=3000时翻译为B,=4000时翻译为A,如是其他值则翻译为Other;
SQL如下:
Select monthid , decode (sale,1000,‘D‘,2000,‘C‘,3000,‘B‘,4000,‘A‘,’Other’) sale from output
特殊情况:
若只与一个值进行比较
Select monthid ,decode(sale, NULL,‘---’,sale) sale from output
另:decode中可使用其他函数,如nvl函数或sign()函数等;
NVL(EXPR1,EXPR2)
若EXPR1是NULL,则返回EXPR2,否则返回EXPR1.
SELECT NAME,NVL(TO_CHAR(COMM),‘NOT APPLICATION‘) FROM TABLE1;
如果用到decode函数中就是
select monthid,decode(nvl(sale,6000),6000,‘NG‘,‘OK‘) from output
sign()函数根据某个值是0、正数还是负数,分别返回0、1、-1,
如果取较小值就是
select monthid,decode(sign(sale-6000),-1,sale,6000) from output,即达到取较小值的目的。
自己解释下 decode(条件,值1,翻译值1,值2,翻译值2,值3,翻译值3,值4,翻译值4....)
其中条件可以是表中的一列 例如 学生表中的课程这列,另外decode()函数是oracle专有的,而我用的是sql server2012
本文中的例子是这样的
USE [ RUNOOB ]
create table TEST_TB_GRADE
(
ID INT IDENTITY(1,1) PRIMARY KEY ,
USER_NAME VARCHAR(20),
COURSE varchar(20),
SCORE FLOAT
)
USE [ RUNOOB ]
SELECT * FROM dbo.TEST_TB_GRADE ORDER BY USER_NAME --按照用户名排序
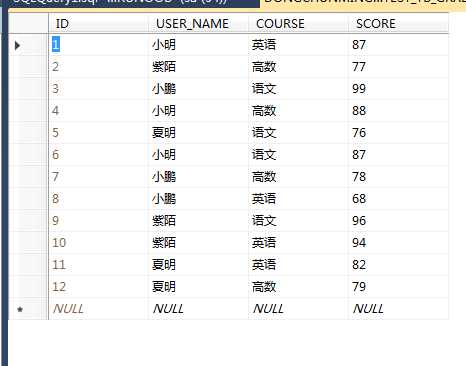
测试数据如下
原文:https://www.cnblogs.com/kelly1314/p/7092760.html