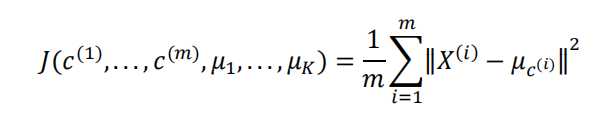聚类分析是在数据中发现数据对象之间的关系,将数据进行分组,组内的相似性越大,组间的差别越大,则聚类效果越好。
此次我们学习聚类中的第一个算法——K-均值算法。K-均值算法本质就是重复将样本分配的类里面,不断的更新类的重心位置。
这里将围绕K-均值算法讨论目标优化、随机初始化和如何选择聚类数。
K-均值是最普及的聚类算法,算法接受一个未标记的数据集,然后将数据聚类成不同的组。
K-均值是一个迭代算法,假设我们想要将数据聚类成 n 个组,其方法为:
首先选择??个随机的点,称为聚类中心(cluster centroids);
对于数据集中的每一个数据,按照距离??个中心点的距离,将其与距离最近的中心点关联起来,与同一个中心点关联的所有点聚成一类。
计算每一个组的平均值,将该组所关联的中心点移动到平均值的位置。
用??1,??2 ,...,???? 来表示聚类中心,用??(1),??(2) ,...,??(??)来存储与第??个实例数据最近的聚类中
心的索引,K-均值算法的伪代码如下:
Repeat {
for i = 1 to m
c(i) := index (form 1 to K) of cluster centroid closest to x(i)
for k = 1 to K
μk := average (mean) of points assigned to cluster k
}
即:
选择K个点作为初始质心
repeat
将每个点指派到最近的质心,形成K个簇
重新计算每个簇的质心
until 簇不发生变化或达到最大迭代次数
算法分为两个步骤,第一个 for 循环是赋值步骤,即:对于每一个样例??,计算其应该属
于的类。第二个 for 循环是聚类中心的移动,即:对于每一个类??,重新计算该类的质心。
K-均值算法也可以很便利地用于将数据分为许多不同组,即使在没有非常明显区分的组群的情况下。
K-均值最小化问题,是要最小化所有的数据点与其所关联的聚类中心点之间的距离之和,
因此 K-均值的代价函数(又称畸变函数 Distortion function)为:
通过比较这两个式子,我们可以发现,K-均值迭代算法,第一个循环是用于减小??(??)引起的代价,
而第二个循环则是用于减小????引起的代价。迭代的过程一定会是每一次迭代都在减小代价函
数,不然便是出现了错误。
在运行K-均值算法的之前,我们首先要随机初始化所有的聚类中心点,下面介绍怎样做:
1. 我们应该选择?? < ??,即聚类中心点的个数要小于所有训练集实例的数量
2. 随机选择??个训练实例,然后令??个聚类中心分别与这??个训练实例相等
K-均值的一个问题在于,它有可能会停留在一个局部最小值处,而这取决于初始化的情况。
为了解决这个问题,我们通常需要多次运行K-均值算法,每一次都重新进行随机初始
化,最后再比较多次运行K-均值的结果,选择代价函数最小的结果。这种方法在??较小的时
候还是可行的,但是如果??较大,这么做也可能不会有明显地改善
通过学习,可以发现K-Means算法有主要的两个缺陷:
1. K值需要预先给定,属于预先知识,很多情况下K值的估计是非常困难的。
2. K-Means算法对初始选取的聚类中心点是敏感的,不同的随机种子点得到的聚类结果完全不同。
通过“肘部法则”,选择聚类数。
改变??值,也就是聚类类别数目的总数。用一个聚类来运行 K 均值聚类方法。这就意味着,所有的数据都会分到一个聚类里,然后计算成本函数
或者计算畸变函数??。??代表聚类数字。
如果问题中没有指定的值,可以通过肘部法则这一技术来估计聚类数量。肘部法则会把不同值的成本函数值画出来。
随着值的增大,平均畸变程度会减小;每个类包含的样本数会减少,于是样本离其重心会更近。
但是,随着值继续增大,平均畸变程度的改善效果会不断减低。值增大过程中,畸变程度的改善效果下降幅度最大的位置对应的值就是肘部。
无监督学习——聚类算法
原文:https://www.cnblogs.com/CuteyThyme/p/11361098.html