微信公众号【黄小斜】大厂程序员,互联网行业新知,终身学习践行者。关注后回复「Java」、「Python」、「C++」、「大数据」、「机器学习」、「算法」、「AI」、「Android」、「前端」、「iOS」、「考研」、「BAT」、「校招」、「笔试」、「面试」、「面经」、「计算机基础」、「LeetCode」 等关键字可以获取对应的免费学习资料。
![]() ?
?
网络访问
随着 Oracle, Sybase, SQL Server ,DB2, Mysql 等人陆陆续续住进数据库村, 这里呈现出一片兴旺发达的景象, 无数的程序在村里忙忙碌碌, 读写数据库, 实际上一个村落已经容不下这么多人了, 数据库村变成了数据镇。
这一天, 数据库镇发生了一件大事: 它连上了网络!
外部的花花世界一下全部打开, 很多程序开始离开这个拥挤的城镇, 住到更加宜居的地方去。
可是他们的工作还是要读写数据库, 大家都在想办法能不能通过网络来访问数据库镇的数据库。
其中移居到Tomcat村的Java 最为活跃, 这小子先去拜访了一下Mysql , 相对于Oracle, Sybase 等大佬, Mysql 还很弱小, 也许容易搞定。
Java 说: “Mysql 先生, 现在已经网络时代了, 您也得与时俱进啊, 给我们开放下网络接口吧。 ”
Mysql 说: “还网络时代, 你们这些家伙越来越懒了, 都不愿意到我们家里来了! 说说吧, 你想怎么开放? ”
Java 说: “很简单, 您听说过TCP/IP还有Socket 没有? 没有吗?! 没关系, 您的操作系统肯定知道, 它内置实现了TCP/IP和socket, 您只需要和他商量一下, 需要申请一个ip , 确定一个端口, 然后您在这个端口监听, 我每次想访问数据了, 就会创建一个socket ,向你发起连接请求, 你接受了就行了。 ”
(刘欣注: 参见《张大胖的socket》)
“这么麻烦啊?”
“其实也简单, 您的操作系统会帮忙的, 他非常熟悉, 再说只需要做一次就行, 把这个网络访问建立起来, 到时候很多程序都会来访问您, 您会发财的。 ”
“不会这么简单吧, 假设说, 我是说假设啊, 通过socket我们建立了连接, 通过这个连接, 你给我发送什么东西? 我又给你发什么东西?” Mysql非常老练, 直击命门。
“呃, 这个.... ”
Java 其实心里其实非常明白, 这需要和Mysql定义一个应用层的协议, 就是所谓的你发什么请求, 我给你什么响应。
例如:
客户端程序先给Mysql 打个招呼, Mysql也回应一下, 俗称握手。
怎么做认证、授权, 数据加密, 数据包分组。
用什么格式发送查询语句, 用什么格式来发送结果。
如果结果集很大, 要一下子全发过来吗?
怎么做数据缓冲?
......
等等一系列让人头痛的问题。
本来Java是想独自定义, 这样自己也许能占点便宜, 没想到Mysql 直接提出来了。
“这样吧 ” Java 说 “我们先把这个应用层的协议定义下来, 然后您去找操作系统来搞定socket如何? ”
“这还差不多 ” 。 Mysql 同意了。
两人忙活了一星期, 才把这个应用层协议给定义好。
然后又忙了一星期, 才把Mysql 这里的socket搞定。
Java 赶紧回到Tomcat村, 做了一个实验: 通过socket和mysql 建立连接, 然后通过socket 发送约定好的应用层协议, 还真不错, 一次都调通了, 看来准备工作很重要啊。
(刘欣注: 这是我的杜撰, mysql 的网络访问早就有了, 并不是java 捷足先登搞出来的)
统一接口
搞定了Mysql , Java 很得意, 这是一个很好的起点, 以后和Oracle, SQL Server, Db2等大佬谈判也有底气了。
尤其是和mysql 商量出的应用层协议, mysql 也大度的公开了, 这样一来, 不管是什么语言写的程序,管你是java, pyhton, ruby , php...... 只要能使用socket, 就可以遵照mysql 的应用层协议进行访问, mysql 的顾客呈指数级增长, 财源滚滚。 尤其是一个叫PHP的家伙, 简直和mysql 成了死党。
Oracle, Db2那帮大佬一看, 立刻就红了眼, 不到Java 去谈判, 也迫不及待的定义了一套属于自己的应用层访问协议。
令人抓狂的是, 他们的网络访问协议和Msyql 的完全不一样 ! 这就意味着之前写的针对mysql 的程序无法针对Oracle , Db2通用, 如果想切换数据库, 每个程序都得另起炉灶写一套代码!
更让人恶心的是, 每套代码都得处理非常多的协议细节, 每个使用Java进行数据库访问的程序都在喋喋不休的抱怨: 我就想通过网络给数据库发送SQL语句, 怎么搞的这么麻烦?
原因很简单, 就是直接使用socket编程, 太low 了 , 必须得有一个抽象层屏蔽这些细节!
Java 开始苦苦思索, 做出一个好的抽象不是那么容易的。
首先得有一个叫连接(Connection)的东西, 用来代表和数据库的连接。
想执行SQL怎么办? 用一个Statement来 表示吧。 SQL返回的结果也得有个抽象的概念: ResultSet 。
他们之间的关系如图所示:
从Connection 可以创建Statement, Statement 执行查询可以得到ResultSet。
ResultSet提供了对数据进行遍历的方法, 就是rs.next() , rs.getXXXX .... 完美!
对了, 无论是Connection, 还是Statement, ResultSet , 他们都应该是接口,而不能是具体实现。
具体的实现需要由各个数据库或者第三方来提供, 毫无疑问, 具体的实现代码中就需要处理那些烦人的细节了!
Java 把这个东西叫做JDBC, 想着自己定义了一个标准接口, 把包袱都甩给你别人, 他非常得意。
面向接口编程
第一个使用JDBC, 叫做学生信息管理的程序很快发现了问题, 跑来质问Java: “你这个Connection 接口设计的有问题!”
Java 说: “不可能, 我的设计多完善啊!”
“看来你这个规范的制定者没有真正使用啊, 你看看, 我想连接Mysql, 把Mysql 提供的jdbc实现(mysql-connector-java-4.1.jar )拿了过来, 建立一个Connection : ”
“这不是挺正常的吗? 你要连接Mysql , 肯定要提供ip地址, 端口号,数据库名啊” Java 问到。
“问题不在这里, 昨天我遇到mysql了, 他给了我一个号称性能更强劲的升级版mysql-connector-java-5.0.jar, 我升级以后, 发现我的代码编译都通不过了, 原来mysql 把MysqlConnectionImpl 这个类名改成了 MysqlConnectionJDBC4Impl , 你看看, 你整天吹嘘着要面向接口编程, 不要面向实现编程, 但是你自己设计的东西都做不到啊”
Java觉得背上开始出汗, 那个程序说的没错, 设计上出了漏洞, 赶紧弥补吧。
既然不能直接去 new 一个Connection 的实现, 肯定要通过一个新的抽象层来做, 这个中间层叫做什么?
Java 想到了电脑上的驱动程序, 很多硬件没法直接使用, 除非安装了驱动。 那我也模拟一下再做一个抽象层吧: Driver。
每个数据库都需要实现Driver 接口, 通过Driver 可以获得数据库连接Connection , 但是这个Driver 怎么才能new 出来呢? 肯定不能直接new , Java似乎陷入了鸡生蛋、蛋生鸡的无限循环中了。
最后, 还是Java的反射机制救了他, 不要直接new 了, 每个数据库的Driver 都用一个文本字符串来表示, 运行时动态的去装载, 例如mysql 的Driver 是这样的:
Oracle是这样的:
只要这个Driver Class不改动, 其他具体的实现像Connection, Statement, ResultSet想怎么改就怎么改。
接下来的问题是同一个程序可能访问不同的数据库, 可能有多个不同Driver 都被动态装载进来, 如何来管理?
那就搞一个DriverManager吧, Mysql 的Driver, Oracle的Driver 在类初始化的时候, 一定得注册到DriverManager中来, 这样DriverManager才能管理啊:
注意: 关键点是static 的代码块, 在一个类被装载后就会执行。
DriverManager 可以提供一个getConnection的方法, 用于建立数据库Connection 。
DriverManager会把这些信息传递给每个Driver , 让每个Driver去创建Connection 。
慢着! 如果DriverManager 里既有MysqlDriver, 又有OracleDriver , 这里到底该连接哪一个数据库呢? 难道让两个Driver 都尝试一下? 那样太费劲了吧, 还得区分开,没法子只好让那些程序在数据库连接url中来指定吧:
url中指明了这是一个什么数据库, 每个Driver 都需要判断下是不是属于自己支持的类型, 是的话就开始连接, 不是的话直接放弃。
(刘欣注: 每个Driver接口的实现类都需要实现一个acceptsURL(Sting url)方法, 判断这个url是不是自己能支持的。 )
唉,真是不容易啊, Java想, 这下整个体系就完备了吧, 为了获得一个Connection , 综合起来其实就这么几行代码:
无论是任何数据库, 只要正确实现了Driver, Connection 等接口, 就可以轻松的纳入到JDBC框架下了。
Java终于可以高兴的宣布: “JDBC正式诞生了!”
(完)
连接, 连接, 总是连接!
生活中肯定有比数据库连接更有趣的事情。
1
数据库连接
又到了数据库连接的时间!
那些码农把数据库参数送过来, Oracle , Db2, Sybase, SQL Server这些JDBC Driver 懒洋洋起来去干活赚钱。
小东也是其中之一, 每天的工作就是连接Mysql 数据库, 发出SQL查询, 获取结果集。
工作稳定, 收入不菲, 只是日复一日,年复一年, 枯燥的工作实在是太令人厌烦了。
有时候小东会和其他JDBC Driver 聊天, 谈起有些不着调的码农, 创建一个Connection, 发出一个查询, 处理完ResultSet后 , 立刻就把Connection给关掉了。
“他们简直不知道我们建立一个数据连接有多么辛苦, 先通过Socket 建立TCP连接, 然后还要有应用层的握手协议, 唉, 不知道要干多少脏活累活, 这帮码农用完就关, 真是浪费啊。 ”
“还有更可气的, 有些家伙使用了PreparedStatement , 我通知数据库做了预编译, 制定了查询计划, 为此我还花费了不菲的小费。 但是只执行了一次查询, Connection就关掉了, PreparedStatement 也就不可用了, 现在数据库都懒的给我做预编译了 !”
“你们这都是好的, 有些极品根本就不关闭Connection, 最后让这个Connection 进入了不可控状态。 ”
“我们啊, 都把宝贵的生命都献给了数据库连接事业...... ”
抱怨归抱怨, 大部分人都安于现状,逆来顺受了。
2
向Tomcat取经
但是不安分的小东决心改变, 他四处拜访取经, 但是一无所获。
这一天在Tomcat村遇到了Tomcat 村长, 看到了村长处理Http请求的方式, 突然间看到了曙光。
村长说: 我们本来是一个线程处理一个Http请求 , 一个Http请求来到我们这里以后, 我并不会新建一个线程来处理, 而是从一个小黑屋叫来一个线程直接干活, 干完活以后再回到小黑屋待着。
小东问: 小黑屋是什么?
(码农翻身注: 参见文章《我是一个线程》)
村长说: “学名是线程池, 为了充分利用资源, 我在启动时就建立了一批线程, 放到线程池里, 需要线程时直接去取就可以了。 ”
“那要是线程池里的线程都被派出去了怎么办 ? ”
"要么新创建线程, 要么新来的Http请求就要等待了。 实际上,线程也不是无限可用的资源, 也得复用。"
小东心想, 我们JDBC也可以这么搞啊, 把数据库连接给缓存下来, 随用随取, 一来正好可以控制码农们无限制的连接数据库; 二来可以减少数据库连接时间; 第三还可以复用Connection上的PreparedStatement, 不用老是找数据库预编译了。
3
数据库连接池
建立数据库连接池不是那么一帆风顺的, 小东的第一次尝试是创建了一个ConnectionPool这个接口:
里边有两个重要的方法, getConnection(), 用于从池中取出一个让用户使用;
releaseConnection() 把数据库连接放回池中去。
小东想, 只要我写一个ConnectionPool的实现类, 里边可以维护一个管理数据库连接的数据结构就行了, 码农们用起来也很方便, 他们肯定会喜欢的。
可是事与愿违, 几乎没有人用这样的接口。
小东经过多方打探才明白, 码农们要么是用DriverManager来获得Connection, 要么是使用DataSource来得到Connection;关闭的时候,只需要调用Connection.close() 就可以了。
这样的代码已经有很多了, 而小东的新方案相当于新的接口, 需要改代码才能用, 话说回来, 谁愿意没事改代码玩? 尤其是正在运行的系统。
再做一次改进吧, 小东 去找Java 这个设计高手求教。
Java 说:“虽然ConnectionPool概念不错, 但是具体的实现最好隐藏起来, 对码农来说,还是通过DataSource 来获取Connection, 至于这个Connection 是新建的还是从连接池中来的, 码农不应该关心, 所以应该加一个代理Proxy,把物理的Connection给封装起来, 然后把这个Proxy返回给码农。”
“那这个Proxy是不是得和您定义的接口Connection 接口保持一致? 要不然码农还得面对新东西。”
“是的, 这个Proxy 应该也实现JDBC的Connection 接口, 像这样: ”
(点击看大图)
小东说: ”奥, 我明白了, 当码农从DataSource中获得Connection的时候, 我返回的其实是一个ConnectionProxy , 其中封装了一个从ConnectionPool来的Connection , 然后把各种调用转发到这个实际的physicalConn的方法去, 关键点在close, 并不会真的关闭Connection, 而是放回到ConnectionPool “
“哈哈, 看来你已经get了, 这就是面向接口编程的好处啊, 你给码农返回了一个ConnectionProxy, 但是码农们一无所知, 仍然以为是在使用Connection , 这是一次成功的‘欺骗’啊”
“但是你定义的Connection 接口中的方法实在是太多了, 足足有50多个, 我这个Proxy类实际上只关注那么几个, 例如close方法, 其他的都是转发而已,这么多无聊的转发代码是在是太烦人了”
Java说: “还有一种办法,可以用动态代理啊”
小东问:“什么是动态代理?”
"刚才我们提供的那个Proxy可以称为静态代理, 我的动态代理不用你写一个类去实现Connection, 完全可以在运行期来做, 还是先来看代码吧"
(点击看大图)
“代码有点难懂, 你看,这里没有声明一个实际的类来实现Connection 接口 , 而是用动态代理在运行时创建了一个类Proxy.newProxyInstance(....) , 重点部分就是InvocationHandler, 在他的invoke方法中, 我们判断下被调用的方法是不是close, 如果是, 就把Connection 放回连接池, 如果不是,就调用实际Connection的方法。” Java 解释了一通。
小东惊叹到:“代码虽然难懂, 但是精简了好多,我对Java 反射不太熟, 回头我再仔细研究下。”
(码农翻身注: 不熟悉Java动态代理的也可以研究下, 这是一项重要的技术)
经过一番折腾, 数据库连接池终于隐藏起来了, 码农们可以使用原有的方式去获取Connection, 只是不知道背后其实发生了巨变。
当然也不可能让码农完全意识不到连接池, 毕竟他们还得去设置一些参数, 小东定义了一些:
数据库连接池获得了巨大的成功, 几乎成了每一个Java Web项目的标配, 不一样的JDBC驱动小东也获得了极高的荣誉, 后面等着他的还会有哪些挑战呢?
抱怨
JDBC出现以后, 以其对数据库访问出色的抽象, 良好的封装, 特别是把接口和具体分开的做法, 赢得了一片称赞。
(参见文章《》)
乘着Java和互联网的东风, JDBC在风口飞了起来, 无数的程序开始使用JDBC进行编程, 访问数据库村的数据库, 在数据库村,无论是大佬Oracle, 还是小弟Mysql都赚的盆满钵满。
所谓物极必反, JDBC的代码写得多了, 它的弱点就暴露出来了, 很多码农抱怨道:“JDBC是在是太Low了”。
消息传到Tomcat村, Java 简直不相信自己的耳朵: “什么? JDBC还很low ? 看来那帮码农没有用socket访问过数据库吧?! 那才叫low . ”
Tomcat 说 : “你是个标准的制定者, 写代码太少了,太不接地气了, 你看看这样的代码: ”
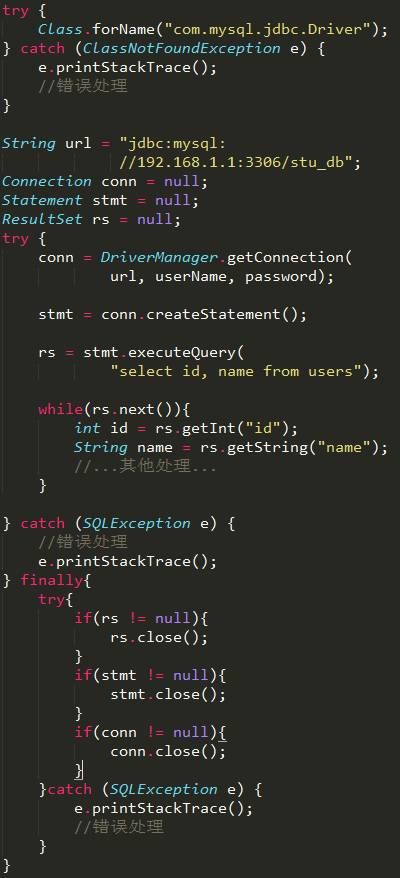
Java 把代码拿过来一看, 不由的倒吸了一口凉气: “ 代码怎么这么长啊, 似乎是有那么一点问题, ‘噪声’似乎太多了, 把业务代码全给淹没了”
Tomcat说:”看来你也是个明白人啊, 为了正确的打开和关闭你定义的Connection , Statement, ResultSet 需要花很多功夫, 再加上那些异常处理, 一个50多行的程序, 真正做事的也就那么10几行而已, 这些琐碎代码太烦人了, 所以大家抱怨很low啊。 ”
Java表示同意: “不错, 可以想象, 如果代码中有大量这样的代码, 码农会抓狂的, 不过,” Java突然想到了些什么 , “其实这不是我的问题, 码农们抱怨错人了, 我作为一门语言, 所能提供的就是贴近底层(socket)的抽象, 这样通用性最强。 至于码农想消除这些重复代码, 完全可以再封装, 再抽象, 再分层啊”
Tomcat想想也是, 在计算机世界里, 每个人都有分工, 不能强求别人做不喜欢也不擅长的事情, 看来这件事错怪Java了。
JDBCTemplate
Java 预料的不错, 稍微有点追求, 不愿意写重复代码的码农都对JDBC做了封装, 例如写个DBUtil的工具类把打开数据库连接, 发出查询语句都封装了起来。
码农的抱怨也渐渐平息了。
有一天, 有个叫JDBCTemplate的人来到了Tomcat村找到了Java , 他自称是Rod Johnson派来专门用于解决JDBC问题的, 他提供了一个优雅而简洁的解决方案。
(注: Rod Johnson就是Spring 最初的作者)
JDBCTemplate说: “尊敬的Java先生, 感谢您发明了JDBC, 让我们可以远程访问数据库村, 您也听说了不少对JDBC的抱怨吧, 我的主人Rod Johnson 也抱怨过, 不过他在大量的编程实践中总结了很多经验, 他认为数据库访问无外乎这几件事情:
指定数据库连接参数
打开数据库连接
声明SQL语句
预编译并执行SQL语句
遍历查询结果
处理每一次遍历操作
处理抛出的任何异常
处理事务
关闭数据库连接”
“我的主人认为” JDBCTemplate说, “开发人员只需要完成黑体字工作就可以了,剩下的事情由我来办“
“你们主人的总结能力很强, 把一个框架应该做的事情和用户应该做的事情区分开了 ” Java说
JDBCTemplate 看到Java 态度不错, 赶紧趁热打铁: “ 我给你看个例子:”

Java 和之前那个传统的JDBC比较了一下, JDBCTemplate的方式的确是把注意力放到了业务层面: 只关注SQL查询, 以及把ResultSet和 User业务类进行映射, 至于如何打开/关闭Connection, 如何发出查询,JDBCTemplate在背后都给你悄悄的完成了, 完全不用码农去操心。
“你在JDBC上做了不错的抽象和封装” Java 说, “但是我还不明白JDBCTemplate 怎么创建出来的”
“这很简单, 你可以直接把它new 出来, 当然new 出来的时候需要一个参数, 就是javax.sql. DataSource, 这也是你定义的一个标准接口啊”
"当然, 我主人Rod Johnson推荐结合Spring 来使用, 可以轻松的把我‘注入’到各个你需要的地方去"。
“明白了, 你们主人这是要推销Spring 啊, 那是什么东西? ”
“简单的说,就是一个依赖注入和AOP框架, 功能强大又灵活。 具体的细节还得让我主人亲自来给您介绍了 ”
(注: 参见《Spring 的本质系列(1) -- 依赖注入》 返回上一级 回复数字 0002阅读文章和《Spring 的本质系列(2) -- AOP》返回上一级 回复数字 0003阅读文章)
“好吧, 不管如何, 我看你用起来还不错, 可以向大家推荐一下。”
O/R Mapping
JDBCTemplate这样对JDBC的封装 , 把数据库的访问向前推进了一大步, 但是Tomcat村和数据库村的很多有识之士都意识到: 本质的问题仍然没有解决!
这个问题就是面向对象世界和关系数据世界之间存在的巨大鸿沟。
Tomcat村的Java 程序都是面向对象的: 封装、继承、多态, 对象被创建起来以后, 互相关联, 在内存中形成了一张图。
数据库村的关系数据库则是表格: 主键,外键, 关系运算、范式、事务。 数据被持久化在硬盘上。
ResultSet依然是对一个表的数据的抽象和模拟: rs.next() 获取下一行, rs.getXXX("XX") 访问该行某一列。
把关系数据转化成Java对象的过程, 仍然需要码农们写大量代码来完成。
现在码农的呼声越来越高, 要把这个过程给自动化了。 他们的要求很清晰: 我们只想用面向对象的方式来编程, 我们告诉你Java 类、属性 和数据库表、字段之间的关系, 你能不能自动的把对数据库的增删改查给实现了 ?
他们还把这个诉求起了一个很洋气的名称: O/R Mapping (Object Relational Mapping)
Java 自然不敢怠慢, 赶紧召集Tomcat村和数据库村开了一次会议, 确定了这么几个原则:
1. 数据库的表映射为Java 的类(class)
2. 表中的行记录映射为一个个Java 对象
3. 表中的列映射为Java 对象的属性。
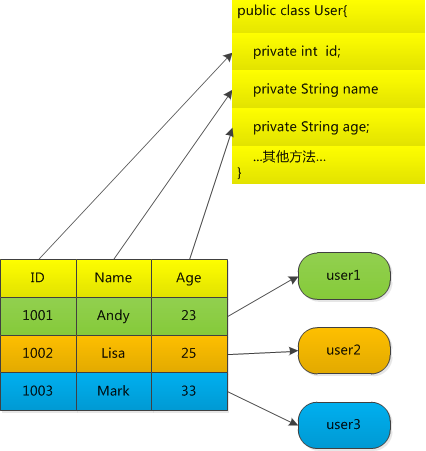
但是光有这几个原则是远远不够的, 一旦涉及到实际编程, 细节会扑面而来:
1. Java类的粒度要精细的多, 有时候多个类合在一起才能映射到一张表
例如下面的例子, User类 的name属性其实是也是一个类, 但在数据库User 表中, firstName, middleName, lastName却是在同一张表中的。
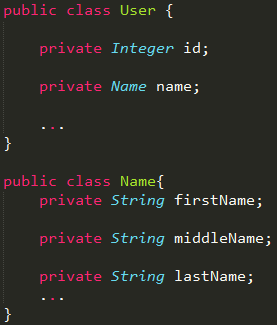
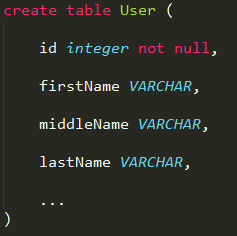
2. Java 的面向对象有继承, 而数据库都是关系数据, 根本没有继承这回事!
这时候可选的策略就很多了, 比如
(1) 把父类和子类分别映射到各自的Table 中, 数据会出现冗余
(2) 把父类的公共属性放到一个Table中, 每个子类都映射到各自的Table中, 但是只存放子类自己的属性。子类和父类的表之间需要关联。
(3) 干脆把父类和子类都映射到同一张Table中, 用一个字段(例如Type)来表明这一行记录是什么类型。
3. 对象的标识问题
Java中使用a==b 或者 a.equals(b) 来进行对象是否相等的判断, 而数据库则是另外一套:使用主键。
4. 对象的关联问题
在Java 中, 一个对象关联到另外一个或者一组对象是在是太常见了, 双向的关联(也就是A 引用B , B反过来也引用了A )也时常出现, 而在数据库中定义关联能用的手段只剩下外键和关联表了。
5. 数据导航
在OOP中, 多个对象组成了一张网, 顺着网络上的路径, 可以轻松的从一个对象到达另外一个对象。 例如: City c = user.getAddress().getCity();
在关系数据库中非得通过SQL查询, 表的连接等方式来实现不可。
6. 对象的状态
在OOP中, 对象无非就是创建出来使用, 如果不用了,就需要回收掉, 但是一旦扯上数据库, 势必要在编程中引入新的状态,例如“已经持久化”
......
(注: 本来想讲Hibernate, 但是限于篇幅, 实在是无法展开讲细节, 这几个问题是Hibernate 官网上提到的, 是O/R Maping 的本质问题)
这些细节问题让Java 头大, 他暗自思忖: " 还是别管那些码农的抱怨, 我还是守住JDBC这一亩三分地吧, 这些烦人的O/R Mapping 问题还是让别人去处理好了。 "
O/R Mapping 的具体实现就这么被Java 搁置下了。
Hibernate 和 JPA
随着时间的推移,各大厂商都想利用Java 赚钱, 联合起来搞了一个叫J2EE的规范, 然后疯狂的推行自己的应用服务器(例如Weblogic, Websphere等等),还搭配着硬件销售, 在互联网泡沫时代赚了不少钱。
J2EE中也有一个叫Entity Bean 的东西, 试图去搞定O/R Mapping , 但其蹩脚的实现方式被码农们骂了个狗血喷头。
转眼间, 时间到了2001年, Tomcat告诉Java 说: “听说了吗? 现在很多码农都被一个叫Hibernate的东西给迷住了”
"冬眠(Hibernate) ? 让内存中的数据在数据库里冬眠, 这个名字起的很有意境啊 , 我猜是一个O/R Mapping 工具吧"
"没错, 是由一个叫Gavin King的小帅哥开发的, 这个框架很强悍, 它实现了我们之前讨论的各种烦人细节, 大家都趋之若鹜, 已经成为O/R Mapping 事实上的标准, Entity Bean 已经快被大家抛弃了。 "
“没关系, Entity Bean 从1.0 开始就是一个扶不起的阿斗, 我已经想通了, 我这里只是指定标准, 具体的实现让别人去做。 既然Hibernate 这么火爆, 我们就把Gavin King 招安了吧 ”
“怎么招安? ”
“让小帅哥过来领导着大家搞一个规范吧, 参考一下Hibernate的成功经验 , 他应该会很乐意的。 ”
不久以后, 一个新的Java规范诞生了, 专门用于处理Java 对象的持久化问题, 这个新的规范就是JPA(Java Persistence API), Hibernate 自然也实现了这个规范, 几乎就是JPA的首选了。
做互联网研发,最早接触使用jdbc技术,为了数据库连接能够复用,会用到c3p0、dbcp等数据库连接池。应该是研发人员最早接触的数据库连接池,再到httpclient http连接池,再到微服务netty连接池,redis客户端连接池,以及jdk中线程池技术。
这么多数据库、http、netty连接池,jdk线程池,本质上都是连接池技术,连接池技术核心是连接或者说创建的资源复用。
连接池技术核心:通过减少对于连接创建、关闭来提升性能。用于用户后续使用,好处是后续使用不用在创建连接以及线程,因为这些都需要相关很多文件、连接资源、操作系统内核资源支持来完成构建,会消耗大量资源,并且创建、关闭会消耗应用程序大量性能。
网络连接本身会消耗大量内核资源,在linux系统下,网络连接创建本身tcp/ip协议栈在内核里面,连接创建关闭会消耗大量文件句柄(linux中万物皆文件,一种厉害抽象手段)系统资源。当下更多是应用tcp技术完成网络传输,反复打开关闭,需要操作系统维护大量tcp协议栈状态。
连接池本质上是构建一个容器,容器来存储创建好的线程、http连接、数据库连接、netty连接等。对于使用方相当于黑盒,按照接口进行使用就可以了。各个连接池构建、使用管理详细过程大概分成以下三部分。
第一部分:首先初始化连接池,根据设置相应参数,连接池大小、核心线程数、核心连接数等参数,初始化创建数据库、http、netty连接以及jdk线程。
第二部分:连接池使用,前边初始化好的连接池、线程池,直接从连接池、线程中取出资源即可进行使用,使用完后要记得交还连接池、线程池,通过池容器来对资源进行管理。
第三部分:对于连接池维护,连接池、线程池来维护连接、线程状态,不可用连接、线程进行销毁,正在使用连接、线程进行状态标注,连接、线程不够后并且少于设置最大连接、线程数,要进行新连接、线程创建。
通过上边可以了解到各种连接池技术以及线程池原理或者说套路,理解原理才能不被纷繁复杂表象掩盖。
下面谈谈构建自己连接池,其实理解了连接池、线程原理,可以使用ArrayList来构建自己连接池、线程池。初始化时创建配置连接数、线程,存储在ArrayList容器中,使用时从ArrayList从取出连接、线程进行使用,执行完任务后,提交回ArrayList容器。前提条件是单线程,在多线程状态下要用线程安全容器。
前边根据原理介绍了一个简单连接池、线程池怎样构建,实际工业级别线程池还要考虑到连接状态,短连接重连,线程池维护管理高效,线程池稳定等多个因素。
需要用到连接池而又没有相关开源产品可用时,java连接池可以使用common-pool2来构建,比如google开源gRPC技术,本身是高性能跨平台技术,但目前作为微服务使用,没有连接池、负载均衡等相应配套,这时可以根据需要自己基于Java容器构建自己连接池。也可以利用common-pool2构建连接池来提升应用性能,以及保持高可用。common-pool2本身不仅仅可以构建连接池使用,还可以用来构建对象池。
连接池还有一个副作用就是实现了高可用,在微服务场景下一个连接不可用,那么再从netty连接池中取出一个进行使用,避免了连接不可用问题。
掌握原理从比较全面掌握各种池技术,避免数据库连接池,再到httpclient http连接池,再到微服务netty连接池,redis客户端连接池,以及jdk中线程池,对象池各种各样池技术,使我们眼花缭乱,花费过多时间,掌握原理机制以不变应万变。
推广一下这个方法,其他技术也是类似,深入掌握其原理,就可以明白其他类似技术相似原理,避免疲于应对各种新技术。但每一种架构设计与实现又与领域有着关系,也不可讲原理不顾实际情况扩展。理论与架构设计、源码学习相结合才是最好的,希望有帮助。
转自:
对于一个简单的数据库应用,由于对于数据库的访问不是很频繁。这时可以简单地在需要访问数据库时,就新创建一个连接,用完后就关闭它,这样做也不会带来什么明显的性能上的开销。但是对于一个复杂的数据库应用,情况就完全不同了。频繁的建立、关闭连接,会极大的减低系统的性能,因为对于连接的使用成了系统性能的瓶颈。
数据库连接池的基本原理是在内部对象池中维护一定数量的数据库连接,并对外暴露数据库连接获取和返回方法。
外部使用者可通过 getConnection 方法获取连接,使用完毕后再通过 close 方法将连接返回,注意此时连接并没有关闭,而是由连接池管理器回收,并为下一次使用做好准备。
Java 中有一个 DataSource 接口, 数据库连接池就是 DataSource 的一个实现
下面我们自己实现一个数据库连接池:
首先实现 DataSource, 这里使用 BlockingQueue 作为池 (只保留了关键代码)
import javax.sql.DataSource;
import java.io.PrintWriter;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.sql.SQLFeatureNotSupportedException;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
import java.util.logging.Logger;
public class MyDataSource implements DataSource {
static {
try {
Class.forName("com.mysql.jdbc.Driver");
} catch (Exception e) {
e.printStackTrace();
}
}
//这里有个坑
//MySQL用的是5.5的
//驱动用的是最新的
//连接的时候会报The server time zone value ‘?й???????‘
// is unrecognized or represents more than one time zone
//解决方法:
//1.在连接串中加入?serverTimezone=UTC
//2.在mysql中设置时区,默认为SYSTEM
//set global time_zone=‘+8:00‘
private String url = "jdbc:mysql://localhost:3306/test?serverTimezone=UTC";
private String user = "root";
private String password = "123456";
private BlockingQueue<Connection> pool = new ArrayBlockingQueue<>(3);
public MyDataSource() {
initPool();
}
private void initPool() {
try {
for (int i = 0; i < 3; i++) {
pool.add(new MyConnection(
DriverManager.getConnection(url, user, password), this));
}
} catch (SQLException e) {
e.printStackTrace();
}
}
/*
从池中获取连接
*/
@Override
public synchronized Connection getConnection() throws SQLException {












