http://www.mooc.ai/course/353/learn?lessonid=2289&groupId=0#lesson/2289
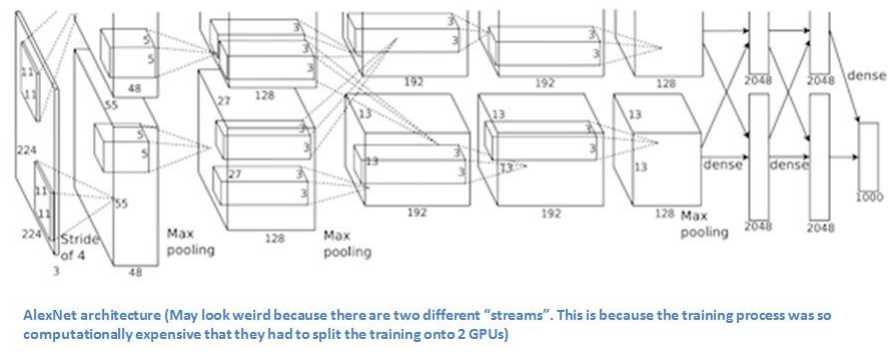
图像输入224*224*3。11*11滤波器。2个通道,用于硬件实现。其中一个通道是5*5的。
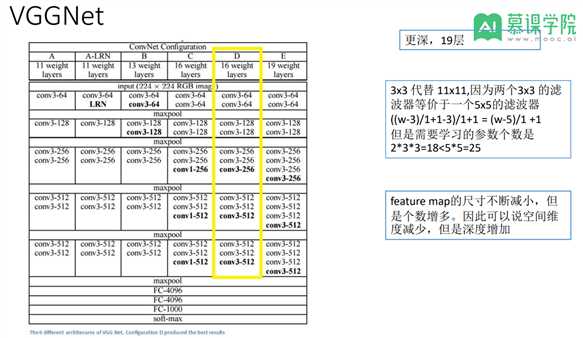
很多变体。VGG16/19。更少参数。
feature map的尺寸不断减小,但 是个数增多。因此可以说空间维 度减少,但是深度增加。
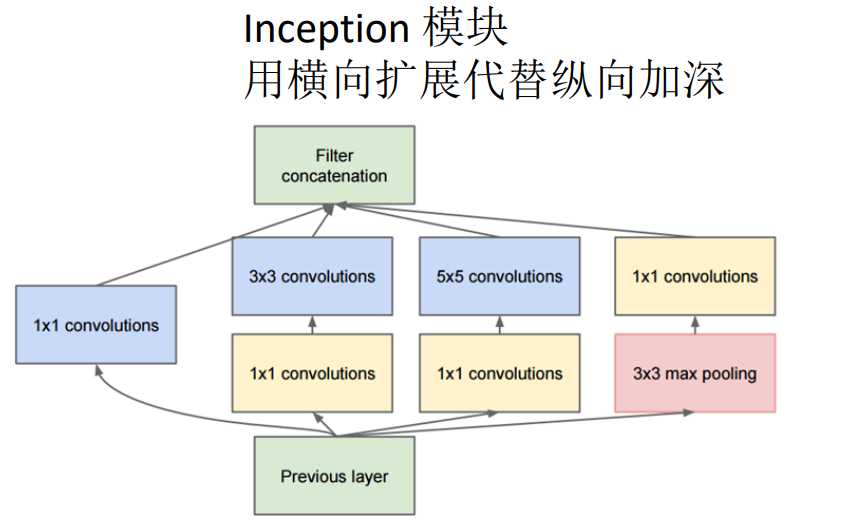
更加复杂、更深 超过100层。空间上横向扩展代替纵向加深。
去掉全连接层,少了很多参数。
1*1卷积层,降维用。
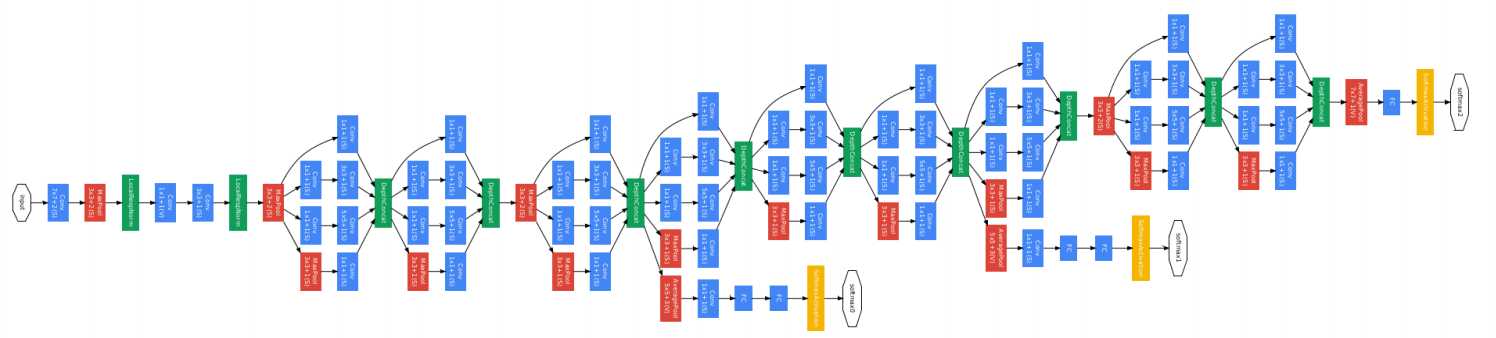
精度超过人类。
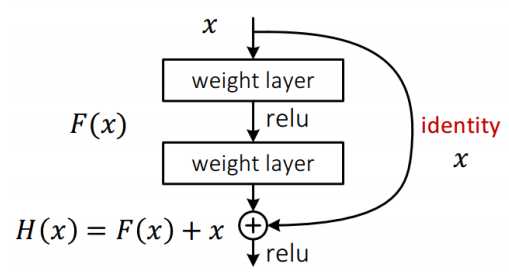
学习的是期望的输出与输入之间的残差。
引入残差后的映射对输出的变化更敏感。
输出变化对权重的调整作用更大,所以效果更好。残差的思想都是去掉 相同的主体部分,从而突出微小的变化。
水平翻转, 随机裁剪和平移变换,颜色、光照变换。适应不同条件。

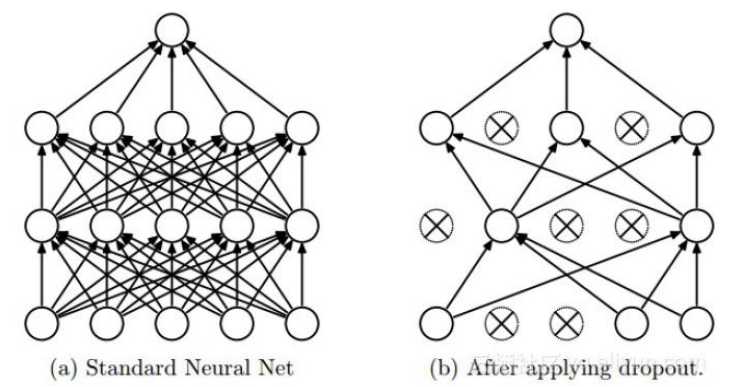
把一些层的输出丢掉,随机不激活。
在训练阶段中,将假设的投影作为修改的激活函数a(h), D是伯努利分布变量:https://yq.aliyun.com/articles/68901
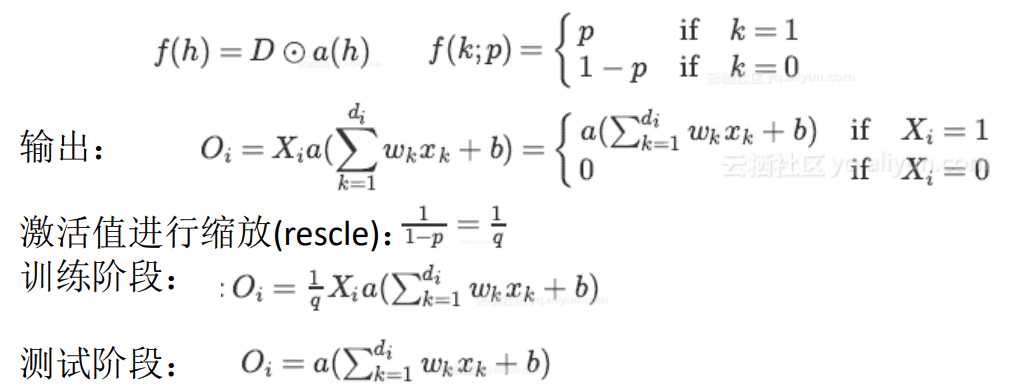
• 1.L1,L2正则化
• 2.Batch Normalization
每次进行SGD的时候,在卷积之后(Wx+b)之后进行归一化,将输出变成均值为0,方差接近1。按照batch,每一维度减去自身均值, 再除以自身标准差。
优点:
1,使用更高的学习率
2,移除或者使用较低的dropout
3,降低L2权重衰减系数
http://caffe.berkeleyvision.org/tutorial/

https://nbviewer.jupyter.org/github/BVLC/caffe/blob/master/examples/00-classification.ipynb
CV3——学习笔记-实战项目(上):如何搭建和训练一个深度学习网络
原文:https://www.cnblogs.com/wxl845235800/p/11367174.html