当数据预处理完成后,我们需要选择有意义的特征输入机器学习的算法和模型进行训练。通常来说,从两个方面考虑来选择特征:
根据特征选择的形式又可以将特征选择方法分为3种:
根据特征的相关性进行评分,设定一个评分阈值来选择。
方差越大的特征,那么我们可以认为它是比较有用的。如果方差较小,比如小于1,那么这个特征可能对我们的算法作用没有那么大。最极端的,如果某个特征方差为0,即所有的样本该特征的取值都是一样的,那么它对我们的模型训练没有任何作用,可以直接舍弃。
主要用于输出连续值的监督学习算法中。我们分别计算所有训练集中各个特征与输出值之间的相关系数,设定一个阈值,选择相关系数较大的部分特征。
卡方检验,是一种以χ2分布为基础的一种常用假设检验方法,它的无效假设H0是:观察频数与期望频数没有差别。
基本思想:假设H0成立,计算出χ2值,表示观察值与理论值之间的偏离程度,根据χ2分布及自由度可以确定在H0假设成立的情况下获得当前统计量及更极端情况的概率P。如果P值很小,说明观察值与理论值偏离程度太大,应当拒绝无效假设。
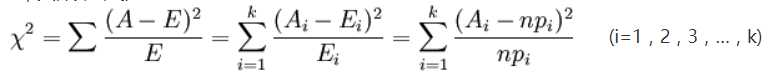
从信息熵的角度分析各个特征和输出值之间的关系评分。互信息值越大,说明该特征和输出值之间的相关性越大,越需要保留。
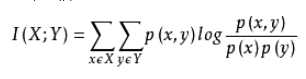
P(x,y):联合分布
使用一个机器学习模型进行多轮训练,每轮训练后,消除若干权值系数的特征,然后在新的特征集上重新训练,直到满足我们要求的特征数量。
经典的SVM-RFE算法,第一轮训练,选择所有的特征进行训练,以每个特征为正例得到最佳超平面,最后每个特征对应的最佳超平面w的平方值最小的,就排除。然后下一轮训练。
使用带惩罚项的基模型,除了筛选出特征外,同时也进行了降维。
L1或L2正则化,正则化惩罚项越大,那么模型的系数就会越小。当正则化惩罚项大到一定的程度的时候,部分特征系数会变成0,当正则化惩罚项继续增大到一定程度时,所有的特征系数都会趋于0. 但是我们会发现一部分特征系数会更容易先变成0,这部分系数就是可以筛掉的。
L1或L2正则化,正则化惩罚项越大,那么模型的系数就会越小。当正则化惩罚项大到一定的程度的时候,部分特征系数会变成0,当正则化惩罚项继续增大到一定程度时,所有的特征系数都会趋于0. 但是我们会发现一部分特征系数会更容易先变成0,这部分系数就是可以筛掉的。
可以使用决策树或者GBDT,不是所有的机器学习方法都可以作为嵌入法的基学习器,一般来说,可以得到特征系数coef或者可以得到特征重要度(feature importances)的算法才可以做为嵌入法的基学习器。
例如:想要知道车子速度,但没有这个特征数据,只有车子的公里数和时间,那么这个高级特征就是由公里数和时间这两个特征计算得到的。
原文:https://www.cnblogs.com/pacino12134/p/11369021.html