我们知道Java在运行时内存分为了五个部分:程序计数器、虚拟机栈、本地方法栈、堆、方法区。其中程序计数器、虚拟机栈、本地方法栈所占用的内存是不需要垃圾收集的,这三个区域的内存随着线程生,随着线程死,我们需要关注的其实只有堆和方法区这两块内存的垃圾收集。
哪些内存需要回收
什么时候回收
怎么回收
在Java中,引用和对象是关联的,如果要操作对象,则必须用引用进行,因此,可以通过引用计数来判断对象是否可以回收。如果该对象被引用,计数器加1,不引用减1,如果计数器等于0,我们就认为没有引用指向该对象,可以将该对象回收,
它的不足之处就是不能解决循环引用,如下面的例子,实际上这两个对象已经不可能再被访问,但是它们因为互相引用着对方,导致它们的引用计数都不为0,于是引用计数算法无法通知GC收集器回收它们。
public class TestCycleReference { private Object obj = null; private static final int _size = 1024 * 1024; public static void main(String[] args) { TestCycleReference t1 = new TestCycleReference(); TestCycleReference t2 = new TestCycleReference(); t1.obj = t2; t2.obj = t1; t1 = null; t2 = null; System.gc(); } }
通过一系列GC Roots对象作为起始点搜索,如果在GC Roots和一个对象之间没有可达路径,则认为该对象不在存活
那么什么可以GC Roots呢?
既然找到了哪些对象是不存活的,那么GC就应该采取一些策略,将不存活的对象kill掉,提供了四种算法来kill掉这些不存活的对象
最基础的垃圾回收算法,分为两个阶段,标记和清楚,标记阶段记出所有需要回收的对象,清除阶段回收被标记的对象所占用的空,如图:

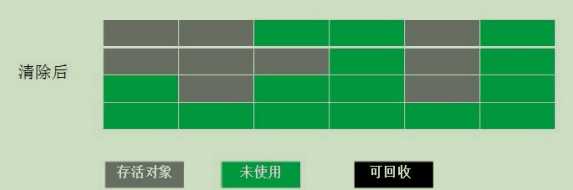
从图中可以看出,该算法最大的问题是内存碎片太严重,后序可能无法对一个大的对象找到可利用的空间
将新生代内存分为一块较大的Eden(伊甸园)与两块大小相等的Survivor(幸存者),默认比例8:1:1
,每次使用Eden与其中一块Survivor区域(一个叫From区,另一个叫To区)
复制算法的核心流程:
step1.对象默认都在Eden区产生,当Eden空间即将满时,触发第一次Minor GC(新生代GC),
将Eden区所有存活对象复制到From区,然后一次性清理掉Eden区的所有空间。
step2.当Eden区再次即将满的时,触发MinorGC,此时需要将Eden与From区的所有存活对象复制到To区,然后一次清理掉Eden与From的所有空间。之后的新生代GC,重复阶段2(只是From与To
来回作为备用区域).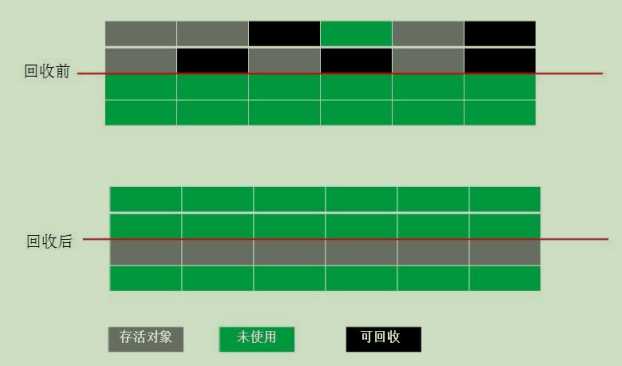
备注:某些对象来回在From与To区交换若干次(默认15次)以上,将其置入老年代空间
这种算法虽然实现简单,内存效率高,不易产生碎片,但是最大的问题是可用内存被压缩到了原本的一半。且存活对象增多的话,Copying算法的效率会大大降低
核心思想相较于标记清除-整理阶段先让存活对象向一端移动,而后清理掉存活对象边界之外的所有空间。
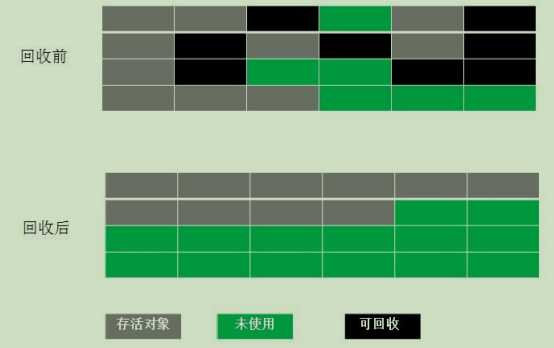
一般情况下,我们将堆区划分为新生代和老年代,老年代特点是每次垃圾回收时只有少量对象需要被回收,所以老年代采用标记整理算法;新生代特点是每次垃圾回收都有大量的对象被回收,所以新生代采用复制算法。
注意:当对象在Survivor区躲过一次GC后,其年龄就会+1。默认情况下年龄到达15的对象会被移到老生代中。
Java堆内存被划分为新生代和年老代两部分,新生代主要使用复制和标记-清除垃圾回收
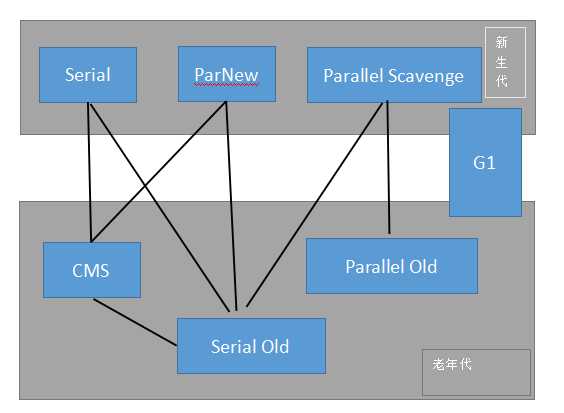
区别一: 使用范围不一样
CMS收集器是老年代的收集器,可以配合新生代的Serial和ParNew收集器一起使用
由于G1收集器对堆区进行划分,所以G1收集器收集范围是老年代和新生代。不需要结合其他收集器使用
区别二: STW的时间
CMS收集器以最小的停顿时间为目标的收集器。
G1收集器可预测垃圾回收的停顿时间(建立可预测的停顿时间模型)
区别三: 垃圾碎片
CMS收集器是使用“标记-清除”算法进行的垃圾回收,容易产生内存碎片
G1收集器使用的是“标记-整理”算法,进行了空间整合,降低了内存空间碎片。
区别四: 垃圾回收的过程不一样
CMS收集器 :初始标记、并发标记、重新标记、并发清除
G1收集器:初始标记、并发标记、最终标记、筛选回收
原文:https://www.cnblogs.com/du001011/p/11380785.html