Vector 、ArrayList 和LinkedList都是List接口下的实现类,但是他们之间的区别和联系是什么呢?
首先:
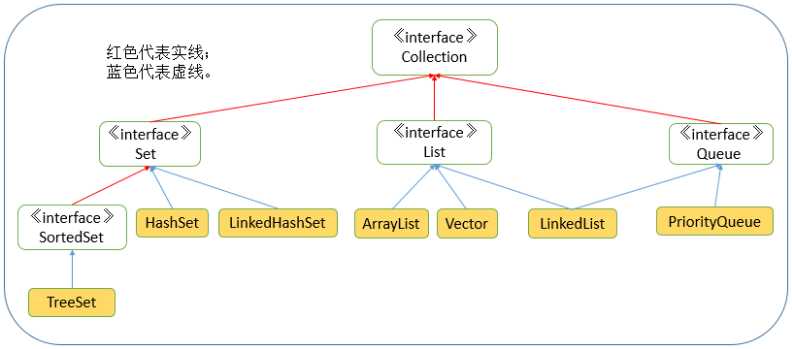
然后:
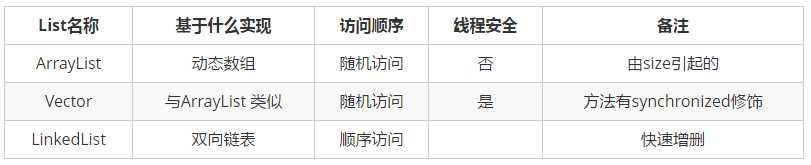
如果您仅仅想知道结论,那么可以关闭了。
下面我讨论讨论为什么。
这是ArrayList所拥有的部分属性,通过这两个字段我们可以看出,ArrayList的实现主要就是用了一个Object的数组,用来保存所有的元素,以及一个size变量用来保存当前数组中已经添加了多少元素。
1 public class ArrayList<E> extends AbstractList<E> 2 implements List<E>, RandomAccess, Cloneable, java.io.Serializable 3 { 4 /** 5 * 列表元素集合数组 6 * 如果新建ArrayList对象时没有指定大小,那么会将EMPTY_ELEMENTDATA赋值给elementData, 7 * 并在第一次添加元素时,将列表容量设置为DEFAULT_CAPACITY 8 */ 9 transient Object[] elementData; 10 11 /** 12 * 列表大小,elementData中存储的元素个数 13 */ 14 private int size; 15 }
接着我们看下最重要的add操作时的源代码:
1 public boolean add(E e) { 2 3 /** 4 * 添加一个元素时,做了如下两步操作 5 * 1.判断列表的capacity容量是否足够,是否需要扩容 6 * 2.真正将元素放在列表的元素数组里面 7 */ 8 ensureCapacityInternal(size + 1); // Increments modCount!! 9 elementData[size++] = e; 10 return true; 11 }
ensureCapacityInternal()这个方法的详细代码我们可以暂时不看,它的作用就是判断如果将当前的新元素加到列表后面,列表的elementData数组的大小是否满足,如果size + 1的这个需求长度大于了elementData这个数组的长度,那么就要对这个数组进行扩容。
由此看到add元素时,实际做了两个大的步骤:
这样也就出现了第一个导致线程不安全的隐患,在多个线程进行add操作时可能会导致elementData数组越界。具体逻辑如下:
另外再看第二步 elementData[size++] = e 设置值的操作同样会导致线程不安全。从这儿可以看出,这步操作也不是一个原子操作,它由如下两步操作构成:
在单线程执行这两条代码时没有任何问题,但是当多线程环境下执行时,可能就会发生一个线程的值覆盖另一个线程添加的值,具体逻辑如下:
这样线程AB执行完毕后,理想中情况为size为2,elementData下标0的位置为A,下标1的位置为B。而实际情况变成了size为2,elementData下标为0的位置变成了B,下标1的位置上什么都没有。并且后续除非使用set方法修改此位置的值,否则将一直为null,因为size为2,添加元素时会从下标为2的位置上开始。
举例分析:
1 public static void main(String[] args) throws InterruptedException { 2 final List<Integer> list = new ArrayList<Integer>(); 3 4 // 线程A将0-1000添加到list 5 new Thread(new Runnable() { 6 public void run() { 7 for (int i = 0; i < 1000 ; i++) { 8 list.add(i); 9 10 try { 11 Thread.sleep(1); 12 } catch (InterruptedException e) { 13 e.printStackTrace(); 14 } 15 } 16 } 17 }).start(); 18 19 // 线程B将1000-2000添加到列表 20 new Thread(new Runnable() { 21 public void run() { 22 for (int i = 1000; i < 2000 ; i++) { 23 list.add(i); 24 25 try { 26 Thread.sleep(1); 27 } catch (InterruptedException e) { 28 e.printStackTrace(); 29 } 30 } 31 } 32 }).start(); 33 34 Thread.sleep(1000); 35 36 // 打印所有结果 37 for (int i = 0; i < list.size(); i++) { 38 System.out.println("第" + (i + 1) + "个元素为:" + list.get(i)); 39 } 40 }
结果:
第7个元素为:3 第8个元素为:1003 第9个元素为:4 第10个元素为:1004 第11个元素为:null 第12个元素为:1005 第13个元素为:6
可以看到第11个元素的值为null,这也就是我们上面所说的情况。
vector之所以说是线程安全的是因为,他的很多方法上都加了Synchronized关键字。
但是!但是!但是!这仅仅表示在vector内部,其所有方法不会被多线程所访问。
如果是像下面这样呢?
if (!vector.contains(element)) vector.add(element); ... }
这是经典的 put-if-absent 情况,尽管 contains, add 方法都正确地同步了,但作为 vector 之外的使用环境,仍然存在 race condition: 因为虽然条件判断 if (!vector.contains(element))与方法调用 vector.add(element); 都是原子性的操作 (atomic),但在 if 条件判断为真后,那个用来访问vector.contains 方法的锁已经释放,在即将的 vector.add 方法调用之间有间隙,在多线程环境中,完全有可能被其他线程获得 vector的 lock 并改变其状态, 此时当前线程的vector.add(element); 正在等待(只不过我们不知道而已)。只有当其他线程释放了 vector 的 lock 后,vector.add(element); 继续,但此时它已经基于一个错误的假设了。
所以,单个的方法 synchronized 了并不代表组合(compound)的方法调用具有原子性,使 compound actions 成为线程安全的可能解决办法之一还是离不开intrinsic lock (这个锁应该是 vector 的,但由 client 维护):
// Vector v = ... public boolean putIfAbsent(E x) { synchronized(v) { boolean absent = !contains(x); if (absent) { add(x); } } return absent; }
【综上】:
Vector 和 ArrayList 实现了同一接口 List, 但所有的 Vector 的方法都具有 synchronized 关键修饰。但对于复合操作,Vector 仍然需要进行同步处理。
在多线程程序中有多个线程访问LinkedList的话会出现什么问题呢?
会抛出ConcurrentModificationException,JDK代码里,ListItr的add(), next(), previous(), remove(), set()方法都会跑出ConcurrentModificationException。
举例:通过LinkedList对象修改其结构
如果两个线程都是通过LinkedList对象修改其结构,会发生什么呢?我们先看一下JDK中LinkedList的数据结构。
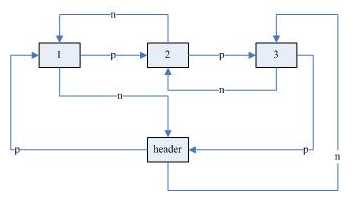
这是一个双向循环链表。header的作用就是能快速定位链表的头和尾。图中,“n”表示next,“p”表示previous。header的n指向first element;p指向last element。
当一个线程A调用LinkedList的addFirst方法时(假设添加节点“4”):
第一步:它首先更新“4”的n和p,n->3, p->header;
第二步:更新节点“3”和herder的n和p,3的n不变, 3的p->4, header的n->4, header的p不变。
假设两个线程A,B同时调用addFirst(4), addFirst(5),会发生什么呢?
很可能4,5的n指向3,p都指向header。也可能addFirst后,紧接着发现getFirst已经不是刚刚加入的元素。
【解决办法】
方法一:List<String> list = Collections.synchronizedList(new LinkedList<String>());
方法二:将LinkedList全部换成ConcurrentLinkedQueue;
Over...
参考:
容器之List接口下各实现类(Vector,ArrayList 和LinkedList)的线程安全问题
原文:https://www.cnblogs.com/gjmhome/p/11385916.html