十一。k-均值聚类
这个需要MR迭代多次。
开始时,会选择K个点作为簇中心,这些点成为簇质心。可以选择很多方法啦初始化质心,其中一种方法是从n个点的样本中随机选择K个点。一旦选择了K个初始的簇质心,下面可以计算输入集合中各个点到这个k个中心点的距离,然后将各个点分配到与他距离最近的簇中心。所有对象都分配之后,在重新计算k个质心的位置。反复迭代,知道簇质心不变(或者变化非常小。)
算法代码:
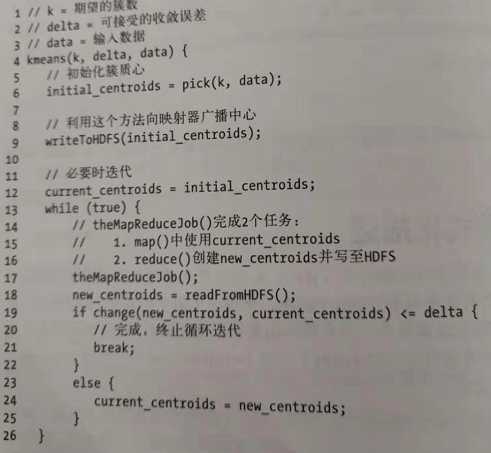

MR的实现步骤:




Spark由ML库,可以直接调用方法:

十二。 KNN

spark的大致步骤:
1.导入所需的类和接口
2.处理输入参数
3.创建一个Spark上下文对象。
4.广播共享对象
5.未查询和训练数据集创建RDD
6.计算(R,S)的笛卡儿积
7.找出R中的r与S中的s之家的距离distance(r,s)
8.按R中的r对距离分组
9.找出k个近邻并对r分类。
数据算法 --hadoop/spark数据处理技巧 --(11.K-均值聚类 12. k-近邻)
原文:https://www.cnblogs.com/dhName/p/11387564.html