表中存在聚集索引的情况下,扫描总是选择聚集索引扫描.
有书中说,在聚集索引碎片化严重的情况下,如果表扫描不要求排序,将采取如图所示的扫描
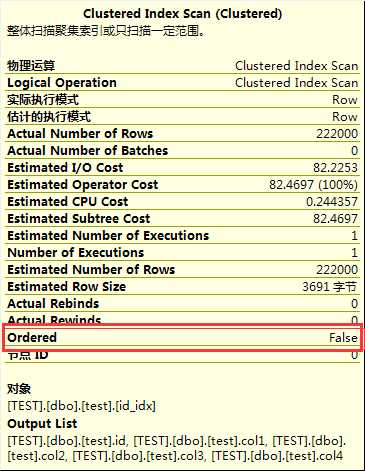
该扫描的特点就是order 为false.
数据引擎灵活的选取执行方式:
1.如果索引碎片化程度不高,将采取聚集索引扫描.
2.如果索引碎片化程度高,将采取iam表扫描.
经测试此论断错误,存在聚集索引的表始终采取聚集索引扫描.
测试方式:
1.创建一张大表,并增加聚集索引.
2.分批插入大量数据,使之产生大量分页,碎片率达到98%
3.然后分别使用带或不带order by的全表检索.时间几乎没有差距.
4.删除索引后全表扫描,时间缩短近一半.
原文:https://www.cnblogs.com/sxf2086he/p/11391674.html