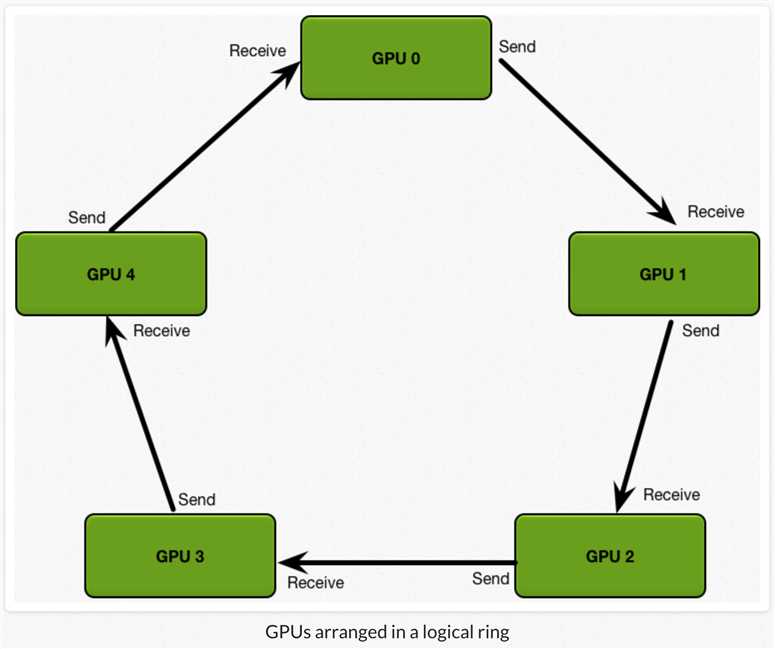
Baidu All Reduce,即Ring All Reduce。Ring All Reduce技术在高性能计算领域很常用,2017年被百度用于深度学习训练。
朴素All Reduce的通信时间随GPU节点数线性增长。Ring All Reduce的通信时间跟GPU节点数无关,只受限于GPU间最慢的连接。
Ring All Reduce包含两步:scatter reduce和all gather。
1)scatter reduce:GPU交换数据,每个GPU得到最后结果的一部分(chunk)。
2)all gather:GPU交换chunk,每个GPU得到最后结果。
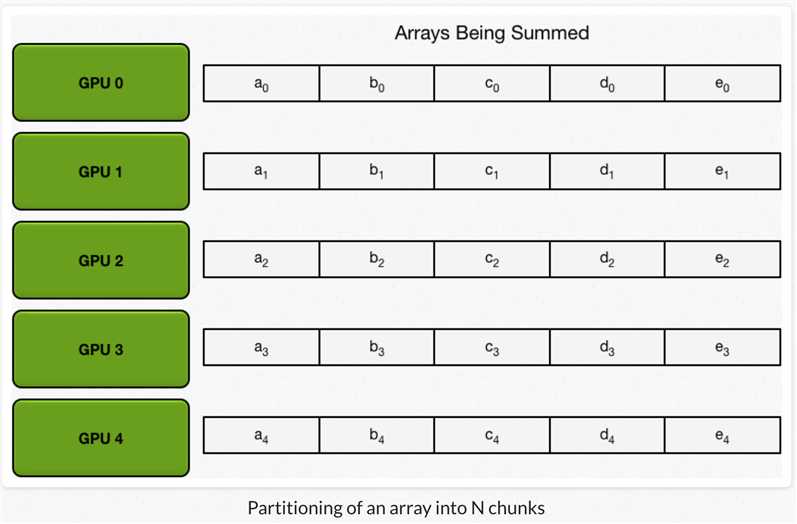
假设要实现数组间对应元素求和,GPU节点数为N,每个GPU都有一个相同size的数组。
1、每个GPU
原文:https://www.cnblogs.com/yangwenhuan/p/11391197.html