Citation
Al-Molegi A , Martínez-Ballesté, Antoni, Jabreel M . Move, Attend and Predict: An Attention-based Neural Model for People’s Movement Prediction[J]. Pattern Recognition Letters, 2018:S016786551830182X.

本文与之前所阅读的几篇轨迹预测文章不同,其采纳循环神经网络对小场景中轨迹预测的提升,将其运用于更大时间跨度(最小为小时,由GPS、打卡机等设备采集)的地点变换预测上。具体来说,定义Move, Attend and Predict (MAP)模型,模型的输入由(二维地址, 时间戳)构成,输出则为根据以往地址信息所预测的下一个地址,模型由RNN编码器、注意力模型和预测模型三部分组成,总体来说结构比较简单,某些技术受限于期刊审核时间稍有滞后,但其在实验评估部分的方法留留给我了一些启示,稍后将在文章中给出。
MAP模型由三部分组成:地点信息模型(左部灰色区)、注意力模型(右部灰色区)、分类器(上)
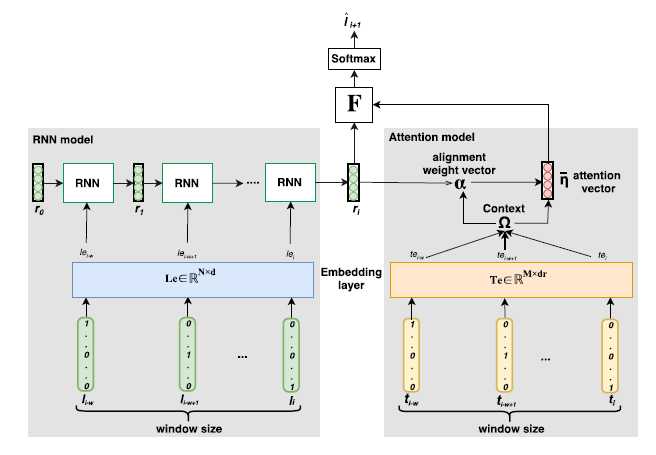
对于行人,给定\(w\)对\(p_i=(l_i,t_i)\ \ (1 \le i \le w)\)元组-分别表示地点和时间戳,表示该行人过去的轨迹序列。
模型的目的是基于这\(w\)对信息,推测行人下一步的地点:\(P(l_{i+1}|p_i,...,p_1)\)
地点信息模型是基本的RNN结构,其首先将\(N\)维的独热值地点信息经过嵌入矩阵\(Le\)生成\(d_l\)维向量,而后作为RNN的每一步的输入参与编码,最后一次的RNN输出(维度为\(d_r\))作为summary vector参与注意力模型运算和分类器:
\[le_i = l_i \cdot Le, \ \ r_i = RNN(le_i;W_{rnn})\]
\[r_i \in \R^{d_r}\]
[注意]:模型下标编号是倒序的,以\(i\)为结尾,一直到\(i-w+1\),因此\(r_i\)是RNN最后一个输出。
Question
请仔细参考结构图明确MAP的注意力模型中,“注意的对象到底是谁?“。
应该为时间戳经过嵌入后形成的W个嵌入向量,而不是RNN模型输出,这点需要和带注意力机制的RNN模型区分开。
用Attention Mechanism机制中的三个指标(Query,Key和Value)来具体刻画此模型的注意力机制:
注意力权重由Query和Key点乘并归一化得到:
\[\alpha =softmax(\Omega \cdot r_i) \ \ \alpha \in \R^{w \times 1}\]
注意力向量由注意力权重和Value进行element-wise的乘法运算:
\[\eta = \alpha * \Omega \ \ \eta \in \R^{w \times d_r}\]
分类器实质就是综合RNN编码器和注意力模型两部分模型的信息,进行简单的线性变换,并用softmax压缩为概率对于每个地点的预测概率。这里的综合函数文章给出了两种参考,一种是拼接,另一种是相加,\(W_F\)根据不同策略维度需要有所变化。
\[\hat y = softmax(F(r_i, \eta) \cdot W_F+b)\]
模型最后是优化方法和损失函数,优化方法采用的是ADADELTA,损失函数则直接基于softmax输出的连续概率分布计算(否则离散化后无法求导进行反向传播),这与评估时需要离散的方式是不同的。
\[Loss = - \Sigma^n_{i=1}y_i \cdot log(\hat y_i)\]
[注意]:上述公式只是一个人的损失,i遍历的是有限n个地点,\(y_i\)只有0和1的取值,\(\hat y_i\)是\(\hat y\)中的具体数值。
MAP模型的数据集相比之前轨迹预测的数据集更宏观,时间跨度以小时为最小单位,并且地点也是离散和有限的。
文章在神经网络的可解释方面做了很深的研究,进一步加强了数据定义与模型设计的合理性。
首先,文章中"被注意"的对象是时间独热值经嵌入层得到的\(w\)个时间嵌入向量,文章探讨在计算注意力权重\(\alpha\)时考虑因素的不同对注意力产生的影响。设置已知轨迹长度\(w=2\),两个对比分别是\(\alpha_1 = softamx(g(r_i, \Omega)) \ \ VS \ \ \alpha_2=softmax(g(r_i))\),最后探讨\(\alpha\)的权重分布特点,下图中case1是考虑空间+时间,case2只考虑空间。

结论:将时间因素$\Omega \(纳入考虑得到的\)\alpha$符合人为的认知结果 - 更关注距离当前时间点更近的时间嵌入向量。
模型中为保证维度正确性,隐藏层维度和时间嵌入向量维度保持一致,根据实验结果,在\(d_r=24\)左右达到峰值,或高或低都导致预测能力下降。这恰好说明模型对24小时制的学习效果,过高或过低维度形成的时间段都将导致与时间戳定义(小时制)的不吻合。

时间戳的定义由两方面问题,一是单位的定义(小时,时辰,天,月……),二是选择哪个时刻与对应地点相对应,经过对比,最终得出:
文献阅读报告 - Move, Attend and Predict
原文:https://www.cnblogs.com/sinoyou/p/11407732.html