#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#include <stdlib.h>
#include "cublas_v2.h"
void multiCPU(float *c, float *a, float *b, unsigned int aH, unsigned int aW, unsigned int bH, unsigned int bW)
{
printf("\n");
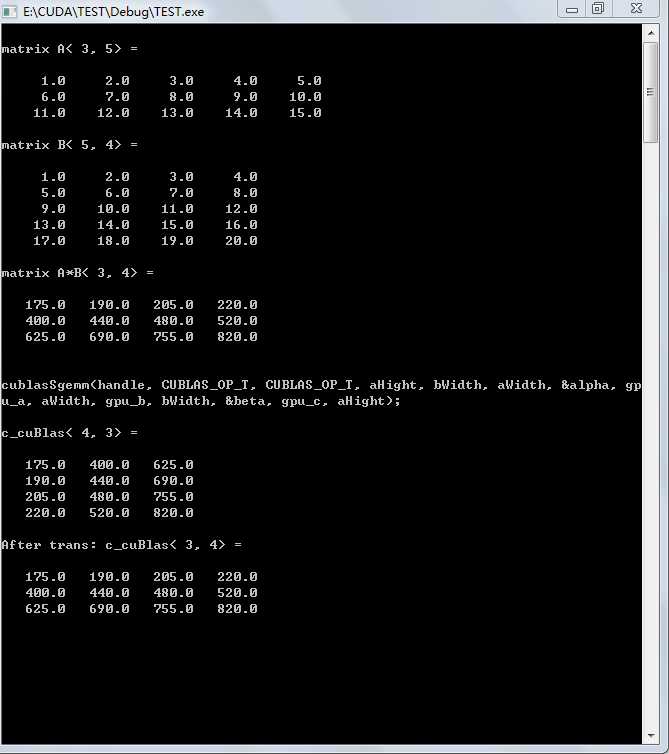
printf("matrix A<%2d,%2d> = \n\n",aH,aW);
for(int y=0; y<aH; ++y)
{
for(int x =0; x<aW; ++x)
{
int index = y*aW + x;
printf("%8.1f",a[index]);
}
printf("\n");
}
printf("\n");
printf("matrix B<%2d,%2d> = \n\n",bH,bW);
for(int y=0; y<bH; ++y)
{
for(int x =0; x<bW; ++x)
{
int index = y*bW + x;
printf("%8.1f",b[index]);
}
printf("\n");
}
printf("\n");
printf("matrix A*B<%2d,%2d> = \n\n",aH,bW);
for(int y=0; y<aH; ++y)
{
for(int x =0; x<bW; ++x)
{
int index = y*bW + x;
c[index] = 0.0f;
for(int i=0; i<aW; ++i)
{
c[index] += a[y*aW+i]*b[i*bW + x];
}
printf("%8.1f",c[index]);
}
printf("\n");
}
printf("\n");
}
void trans(float *a, unsigned int aH, unsigned int aW )
{
float* tr = (float*)malloc(sizeof(float)*aH*aW);
int count = 0;
for(int x = 0; x <aW; ++x)
{
for(int y=0; y<aH; ++y)
{
int index = y*aW + x;
tr[count] = a[index];
count++;
}
}
for(int i = 0; i<count;i++)
{
a[i] = tr[i];
}
free(tr);
for(int y=0; y < aW; ++y)
{
for(int x =0; x < aH; ++x)
{
int index = y*aH + x;
printf("%8.1f",a[index]);
}
printf("\n");
}
printf("\n");
}
int main()
{
const int aHight = 3, aWidth =5;
const int bHight = 5, bWidth =4;
float a[aHight*aWidth] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15 };
float b[bHight*bWidth] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20};
float c[aHight*bWidth] = { 0 };
float c_cuBlas[aHight*bWidth] = { 0 };
multiCPU(c, a, b, aHight,aWidth, bHight, bWidth);
float *gpu_a = 0;
float *gpu_b = 0;
float *gpu_c = 0;
cudaError_t cudaStatus;
cudaStatus = cudaSetDevice(0);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?");
goto Error;
}
cudaStatus = cudaMalloc((void**)&gpu_a,aHight*aWidth*sizeof(float));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMalloc((void**)&gpu_b,bHight*bWidth*sizeof(float));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMalloc((void**)&gpu_c,aHight*bWidth*sizeof(float));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMemcpy(gpu_a, a, aHight*aWidth*sizeof(float), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
cudaStatus = cudaMemcpy(gpu_b, b,bHight*bWidth*sizeof(float), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
//printf("Computing result using CUBLAS...\n");
cublasHandle_t handle;
cublasStatus_t ret;
ret = cublasCreate(&handle);
if (ret != CUBLAS_STATUS_SUCCESS){
printf("cublasCreate returned error code %d, line(%d)\n", ret, __LINE__);
goto Error;
}
const float alpha = 1.0f;
const float beta = 0.0f;
ret = cublasSgemm(handle, CUBLAS_OP_T, CUBLAS_OP_T, aHight, bWidth, aWidth, &alpha, gpu_a, aWidth, gpu_b, bWidth, &beta, gpu_c, aHight);
cudaStatus = cudaMemcpy(c_cuBlas, gpu_c, aHight*bWidth*sizeof(float), cudaMemcpyDeviceToHost);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
cublasDestroy(handle);
/*
trans(b,bHight,bWidth);
trans(a,aHight,aWidth);
multiCPU(c, b, a, bWidth, bHight, aWidth, aHight);
*/
printf("\ncublasSgemm(handle, CUBLAS_OP_T, CUBLAS_OP_T, aHight, bWidth, aWidth, &alpha, gpu_a, aWidth, gpu_b, bWidth, &beta, gpu_c, aHight);\n\n");
printf("c_cuBlas<%2d,%2d> = \n\n",bWidth,aHight);
for(int y=0; y<bWidth; ++y)
{
for(int x=0; x<aHight ;++x)
{
int index = y*aHight + x;
printf("%8.1f",c_cuBlas[index]);
}
printf("\n");
}
printf("\n");
printf("After trans: c_cuBlas<%2d,%2d> = \n\n",aHight,bWidth);
trans(c_cuBlas,bWidth,aHight);
printf("\n");
Error:
cudaFree(gpu_a);
cudaFree(gpu_b);
cudaFree(gpu_c);
return 0;
}
cublas 矩阵相乘API详解,布布扣,bubuko.com
原文:http://www.cnblogs.com/huangshan/p/3917153.html