在学习redis之前,先回顾下缓存,在前面的学习中,关于缓存学习了mybatis的缓存
一级缓存:一级缓存存在于sqlsession中,是默认开启的,生命周期只在一个会话内,当会话内发生更新数据时(增删改)或会话结束时close(),缓存失效
二级缓存:二级缓存存在与命名空间中(mapper的namespace中),这个命名空间是存在服务器的内存中的(tomcat服务器的内存),当服务器关闭时,缓存失效
无论一级缓存还是二级缓存都不会永远持久化数据到硬盘中,因此mybatis的缓存使用率就会很低,而且使用的范围也很窄(只能使用到对数据库的增删改查)
当拥有的数据量较大时(假如用户表users中有十亿条数据,select * from users,mybatis无法做到大批量数据的查询,连查询都无法做到,数据也绝对不会进入缓存中)
1.经常使用的数据
2.不会经常发生改变的数据(比如说:身份证号、性别、省市区国家组织等,把经常用到并且不会经常改变的数据存入数据库中的某张表中叫做字典表)
redis称之为缓存,是一个数据库(非关系型数据库)
关系型数据库:mysql,oracle;表和表之间产生关联,数据与数据之间也有关联,称之为关系型数据库
非关系型数据库:NOSQL,没有sql的数据库,数据与数据之间是独立存在的,没有关系,也没有表的概念(也就是说,在这个数据库中,不能使用sql语句select、update等)
Redis:键值对对应的数据库(数据格式以key和value对应,就像json,redis中存的就是json格式的数据)
redis中的数据类型都有什么?
redis是键值对对应的数据库,因此key只有一种类型String,value有五种类型:
List
Hash
String(使用最对的)
Set(以前的版本中是Map,新版本中是Set)
zSet
Set和zSet的区别:
Set:数据是无序的,且数据是唯一的(数据的值是唯一的,索引不是,与集合中的set一样,一个索引可以对应多个值)
zSet:数据是有序的,且数据是唯一的(数据的索引是唯一的,数据的值可以相同,每个值都有自己的唯一索引)
所有的NOSQL数据库都会在内存中做计算,数据会永久保存在内存中
当redis启动后,redis会自动从磁盘中加载数据,将数据加载入内存中,等待客户端进行查询数据,这样客户端实际是从内存中获取数据,所以效率会非常快。
应用场景:一般只能应用与缓存,因为数据都存在了内存中,所以相应的也非常的消耗内存,
Redis是以集群的形式存在,在官方文档中说明,如果需要配置redis缓存库,至少需要六台(三主三从)
用一个图来描述redis的工作原理:
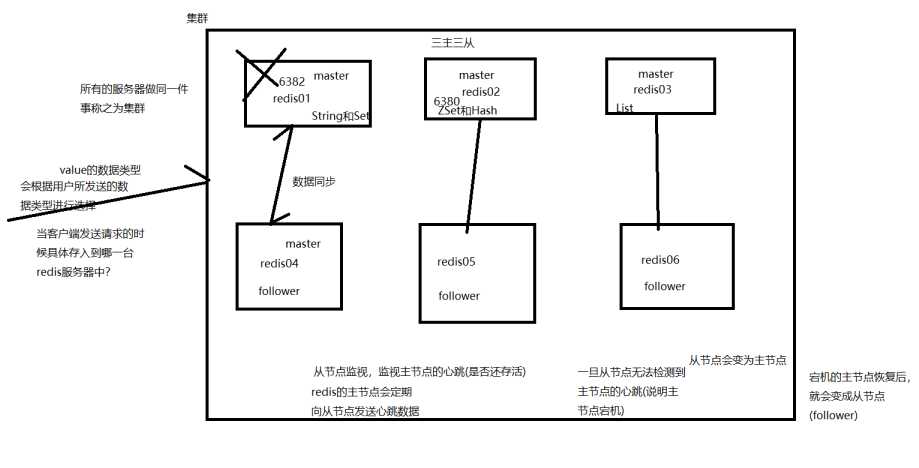
创建redis的集群,三主三从,每一个主服务器master都有一个随从follower,master主要存放数据,follower监视master是否存活,master与follower之间的数据要保持同步,这样,当master宕机时,follower就会代替master的位置,变成主节点,然后原来的主节点修好后,变成从节点监视,等待现在的主节点宕机后,就会再次成为主节点
1.redis必须以集群的形式存在(六台服务器),占用的资源就会非常的多
2.主从之间需要数据的同步,占用的磁盘空间就会非常大,master有十万条数据,follower也要有十万条数据,但是只有master中的数据才会被使用
3.redis是在内存中所运算(10万条数据缓存信息),就会占用非常大的内存
4.因为最终因为redis加载机制问题,硬盘和内存需要进行交互,会占用非常大的CPU
原文:https://www.cnblogs.com/Zs-book1/p/11411561.html