写在前面的话
在使用 Linux 的时候,可以经常听到有关文件系统 FS(File System)的东西,MySQL 也有属于自己类似的东西,那就是存储引擎。之前在创建数据表的时候,在 Create table 后面一般都加了 engine=innodb。这就是指定存储引擎。
关于存储引擎
可以将存储引擎就当作 Linux 而言的文件系统,其主要功能在于:数据读写 / 安全 / 一致性,提升读写性能,提供热备份,自动故障恢复,高可用等。
需要知道的存储引擎大致有:InnoDB,MyISAM,MEMORY,ARCHIVE,CSV,BLACKHOLE,MERGE,NDBCLUSTER,EXAMPLE 等
查看数据库支持的存储引擎:
show engines;
结果:
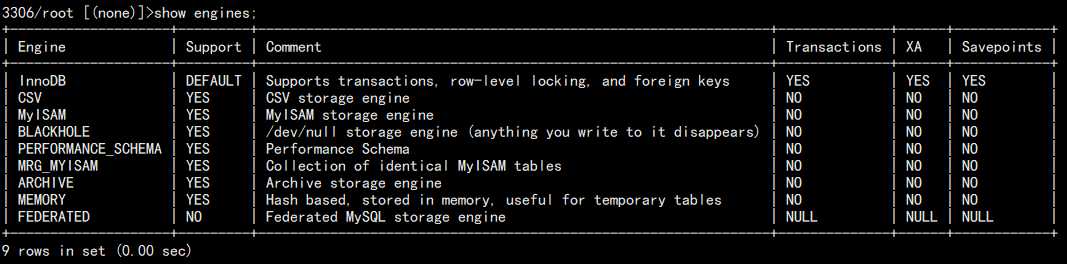
值得注意的是,存储引擎针对的对象是表,这意味着一个库中,可能存在多种存储引擎,例如:
select TABLE_NAME,ENGINE from information_schema.tables where TABLE_SCHEMA="mysql";
结果:
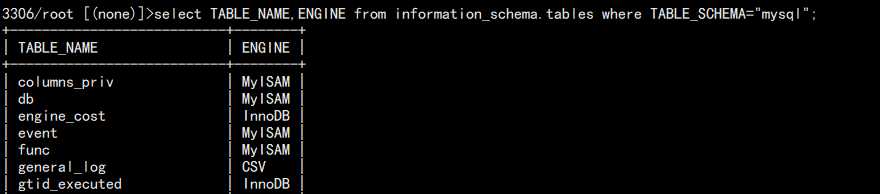
对于 MySQL 的两大分支 Percona 和 MariaDB 的存储引擎:
Percona:默认 XtraDB
MariaDB:默认 InnoDB
同样也有其它的存储引擎:TokuDB,RocksDB,MyRocks 等。
这三种存储引擎有一个共同特点,压缩比较高,数据写入性能高,在使用 Zabbix 监控超多主机时候可以考虑这种。
常见优化建议
1. Zabbix 由于监控的服务器数量太多,数据保留天数长,数据量大,导致平台卡慢,磁盘容量写满,优化建议:
a. 查看 MySQL 版本,对于这类并非超级重要的数据,数据库版本尽可能新,如 8 版本,性能优化明显。
b. 更换数据库存储引擎,默认一般 InnoDB,但是对于这类读写频繁的,可以考虑更换为 TokuDB 这类。
c. 定期清理数据,由于 delete 删除并不会立即释放,可考虑将表按月拆分,使用 drop 或 truncate 删除,当然相对麻烦。
d. 关闭 binlog 和双 1,和上面一样,由于数据不重要,所有没必要这些功能,导致影响性能。
e. 其它的一些优化,如关闭安全性参数,进而提高性能。
2. InnoDB 和 MyISAM 之间存储引擎替换:
由于 MyISAM 是表级锁,性能极差,且不支持事务,在突然断电时会导致数据丢失,所以建议替换为 InnoDB。
3. 由于业务数据量大,程序中的删除并不会释放出空间,而且需要按月删除历史数据,处理办法:
a. 将数据全导出,手动 drop 表重建导入,这样就能释放出空间。
b. 对于需要按月数据清理,可以按月分表,业务使用 truncate 处理旧数据。
关于 InnoDB
先看一张表,在 MySQL 5.5 之后默认的存储引擎就是 InnoDB:
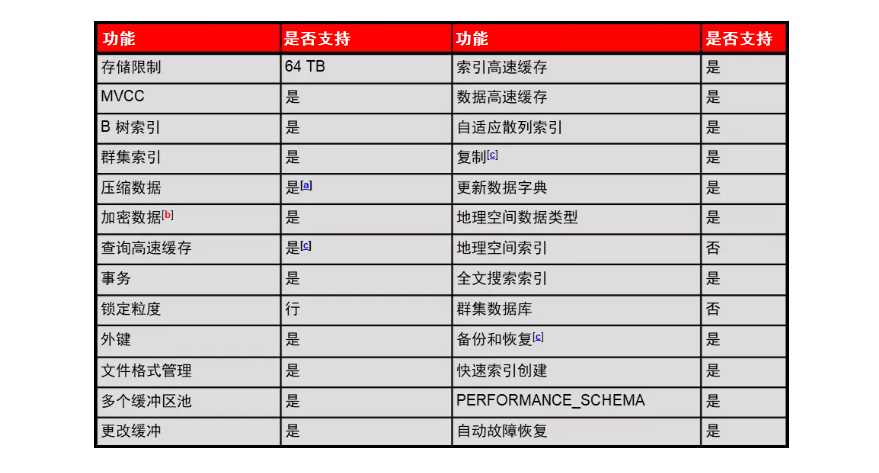
这是 InnoDB 存储引擎支持的功能,其主要优点可以归纳为以下几个(针对于 MyISAM):
a. 支持事务(Transaction)
b. MVCC(Multi-version Concurrency Control,多版本并发控制)
c. 行级锁(Row-Level Lock)
d. ACSR(Auto Crash Safey Recovery,自动故障恢复)
e. 热备份(Hot Backup)
f. Replication / GTID / 多线程
操作存储引擎
1. 查看系统默认存储引擎:
select @@default_storage_engine;
结果:

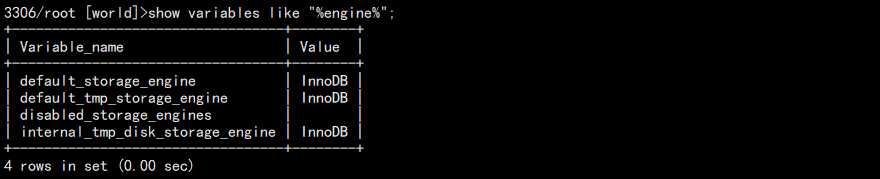
当然,也可以更换为:
show variables like "%engine%";
结果:
2. 修改默认存储引擎:
set default_storage_engine="MyISAM";
结果:
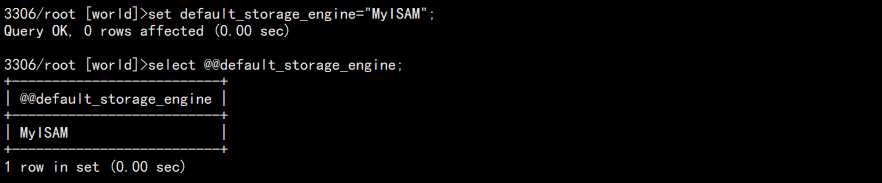
但是这种设置方法存在一个问题,退出登录下次再登录又变回去了,也就是该配置只再当前会话起作用。
设置全局生效的方法:
set global default_storage_engine="MyISAM";
此时当前会话查看是不会生效的,需要退出登录然后重新登录查看:

当然,这样并不会永久生效,重启数据库以后会恢复为之前的,永久生效的方法是在:/etc/my.cnf 中添加:
[mysqld]
default_storage_engine=myisam
可以将 global 和修改配置文件结合起来使用,这样就能实现不用重启数据库并永久生效的目的。当然,肯定还是使用 InnoDB。
3. 查看每个表的存储引擎:
show create table city\G
结果:
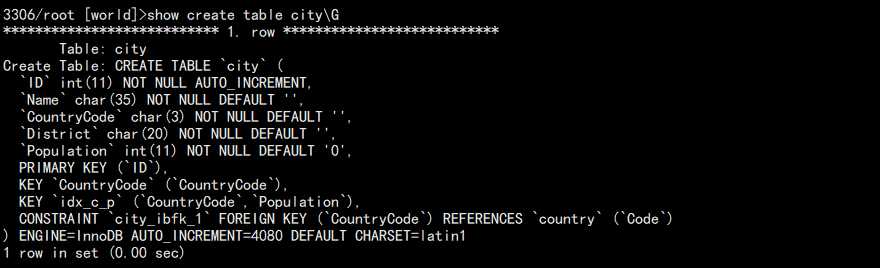
当然也可以使用:
show table status like "city"\G;
结果:
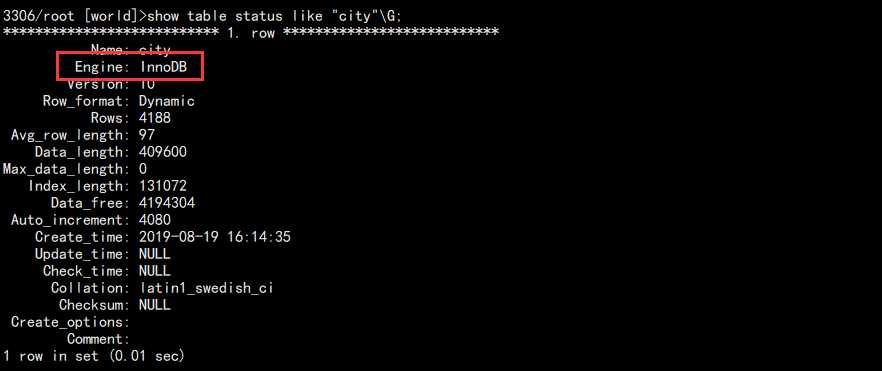
实在还不行就使用 information_schema.tables 查看:
select table_name,engine from information_schema.tables where table_name="city" and table_schema="world";
结果:

4. 修改表的存储引擎:
alter table student engine MyISAM;
结果:

批量修改:
select concat("alter table ",table_name," engine tokudb;") from information_schema.tables where table_schema="school" into outfile "/tmp/1.sql";
前面用过这个语句,只需要注意 /tmp 目录在配置文件中配置 security 信任。

InnoDB 物理存储结构
查看 MySQL 数据目录:
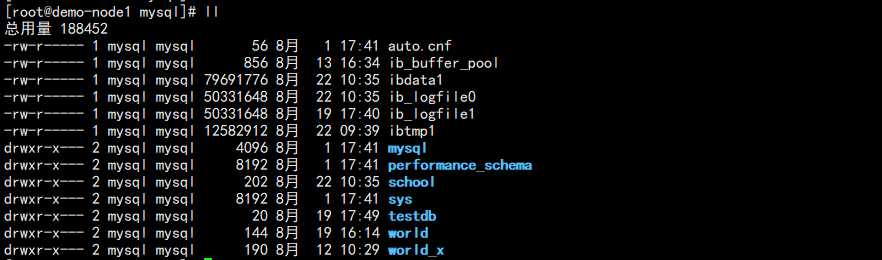
简单的对文件进行说明:
a. ibdata1:系统数据字典信息,UNDO 表空间等数据。
b. ib_logfile0~1:REDO 日志文件,事务日志文件。
c. ibtmp1:临时表空间磁盘位置,用于存储临时表。
d. 其它目录:单独的库。
e. 目录下 frm 文件:存储表的列信息。
f. 目录下 ibd 文件:存储数据和索引。
表空间
1. 共享表空间:
将所有数据存储到同一个表空间中,管理起来比较混乱。
在 5.5 版本中出现,属于默认的存储方式。
在 5.6 版本中只用于存储数据字典信息,undo,临时表。
在 5.7 版本中,临时表也被单独出来。
在 8.0 版本中,undo 也被单独出来。
可以查看共享表空间的设置:
select @@innodb_data_file_path;
如图:

初始时候为 12 M,自动扩展。
查看扩展设置:
show variables like ‘%extend%‘;
结果:

可以知道每扩展一次增加 64M。当然这个规则是可以修改的,同样也可以修改共享表空间的增加规则,如:
innodb_data_file_path=ibdata1:512M:ibdata2:512M:autoextend
这个的意思是初始 512M,第一次扩展也加 512M,后面的扩展就按照配置自动增加。
当然,这些配置一般都是在数据库初始化的时候去设置的,后面一般不怎么动它。
2. 独立表空间:
从 5.6 开始,默认表空间转为独立表空间,主要用于存储用户数据。其特点为一个表两个文件:
frm 用于存储表结构,ibd 用于存储索引和数据行。值得注意的是:
表数据(元素据) = (ibdatax + frm) + ibd
其中 MySQL 存储引擎的各种日志:
Redo log:if_logfilex,重做日志
Undo log:ibdatax,存储在共享表空间中,回滚日志
临时表:ibtmpx,jion union 等产生的数据临时存储
查看独立表空间的设置:
select @@innodb_file_per_table;
结果:

1:说明开启独立表空间,也就是每个表分开存储。
数据恢复案例
有这样一个数据库,没有任何最新备份,在某天突然断电,导致服务器启动后只读,无法使用。
使用 fsck 修复磁盘后,服务器启动成功,但是 MySQL 数据库丢失了某些数据,再也无法启动。
目前手里只要一份老的数据备份。该数据库已经是独立表空间,如何恢复数据到最新:
分析:
1. 由于目前数据库无法启动,所以无法得知该数据库里面的最新表结构,也无法直接捞出 SQL 进行导出恢复。
2. 目前有所有表的 ibd,frm 的文件,但是由于其他库文件异常,导致共享表空间 ibdatax 文件中有些错误,所有才会导致数据库无法启动。
3. 由于备份是旧的,唯一能够提供使用也就只有表结构了。
由此,可以根据上文中的结论:
表数据 = ibdatax + frm + ibd
其中 ibdatax 有错误,无法使用,frm 依赖于 ibdatax,如果我们直接拷贝到新机器上面,也不能使用。
最后我们唯一能够使用的就是数据 ibd,这本身也是最关键的东西。
恢复过程:
1. 旧的备份,故障解决的第一步都是备份,不能直接操作,否则出问题将永久无法恢复。
2. 新服务器建立一个一模一样的数据库,将旧数据导入,这样带来的好处是该数据的 ibdatax 和 frm 是正常的。但是 ibd 的数据是旧的。
3. 将故障服务器的 ibd 文件拷贝到新库下面,然后进行恢复。具体操作可以查看下面的测试:
故障预演测试:
1. 在服务器 192.168.100.111 上面有个 school 库,下面有表:

2. 在服务器 192.168.100.112 上面有一个新数据库。
3. 我们先做个测试,将 111 上面的 school 的目录拷贝到 112 上面看能不能使用:
cd /data/data/mysql/ scp -r school/ root@192.168.100.112:/data/data/mysql/
此时前往 112 上面修改刚刚传过来的文件权限:
cd /data/data/mysql/ chown -R mysql.mysql school/
在 112 上面数据库查看:
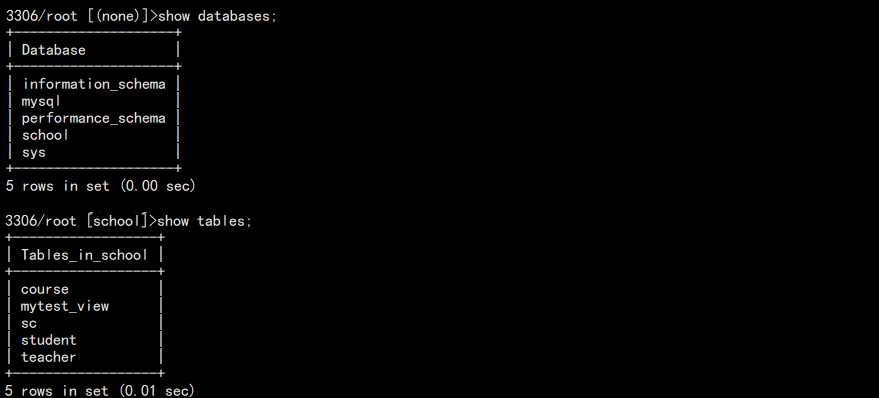
可以发现 use 和 show tables 都是没问题的。此时试试查询:
select * from sc;
结果:

报错表不存在,可是明明 show tables 都还在的。这里的原因就是 ibdatax 文件的问题,我们直接拷贝过来其实际是无法使用的。
4. 将 school 目录先移走,然后将旧的数据库导入,由于之前有过 school 库,虽然移走,但是也有问题,建议重启数据库再导入。
否则可能报错 :
ERROR 1146 (42S02): Table ‘xxx doesn‘t exist
导入之后我们可以查看:

由于我这里测试只是允许了建表语句,所以 select 的时候是空的。
5. 删除独立表空间中存放数据行和索引的文件,也就是 ibd 文件:
alter table course discard tablespace; alter table sc discard tablespace; alter table student discard tablespace; alter table teacher discard tablespace;
结果:
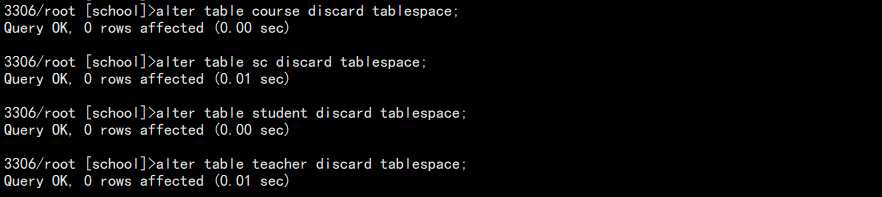
查看 112 服务器上面该库的文件情况:

可以发现,所有的 ibd 文件都不见了。
6. 将故障服务器的 ibd 文件拷贝过来:
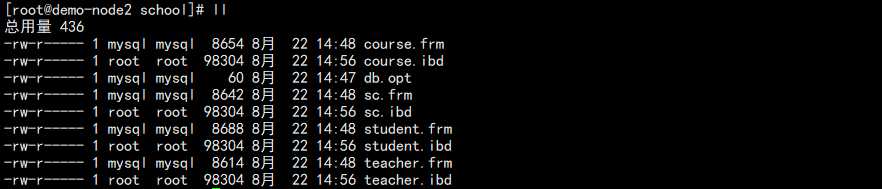
注意,过来的 ibd 文件可能是 root 权限,需要修改为 mysql 用户权限,执行恢复:
alter table course import tablespace; alter table sc import tablespace; alter table teacher import tablespace; alter table student import tablespace;
如果报错,可以重启 MySQL 在执行:
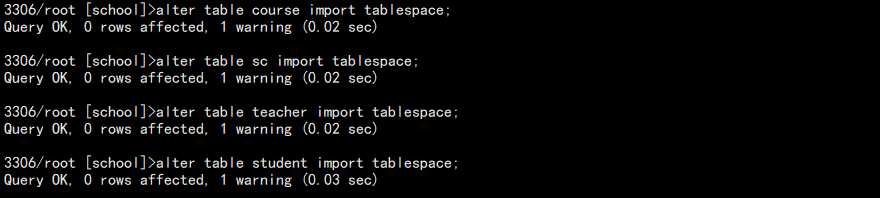
7. 查看恢复结果:

恢复成功!
故障总结:
a. 由于我们是测试,恢复比较容易,但是实际生产中往往很复杂,比如表间关系乱七八糟的还可能导致数据导入失败,可以使用:set foreign_key_checks=0 跳过外键检查再导入。
b. 我们最终想要的还是表结构,所以表结构一定要正确,如果缺少,需要补上。然后再执行 discard 删除 ibd 文件。
c. 这里表少可以一个一个的执行,生产表可能会很多,可以使用之前的 select concat xxx into outfile 来生成批量脚本。
d. 最最最重要,一直牢记在心,备份第一位,然后再操作。
事务 ACID
Atomic:原子性,所有语句被当作一个单元全部执行或者取消,不存在执行一半的情况。
Consistent:一致性,如果数据库在事务开始时处于一致,则在执行期间依旧保留一直。
Isolated:隔离性,事务之间互不影响。
Durable:持久性,事务在执行完成后所有变更将记录到数据库中,变更不会消失。
事务在 5.5 以前的版本需要先执行 begin,之后版本不需要:
begin;
事务结束的标志为:
-- 提交 commit; -- 或者回滚 rollback;
自动提交 autocommit:
1. 查看是否开启自动提交:
select @@autocommit;
结果如图:

2. 关闭 autocommit:
-- 当前会话临时关闭 set autocommit=0; -- 所有会话关闭,重启后消失 set global autocommit=0;
3. 永久关闭 autocommit:在 /etc/my.cnf 加入
autocommit=0
建议将自动提交关闭,可以提升数据库性能。
隐式提交语句:
在 MySQL 中有一些语句能够自动触发提交功能,不需要手动 commit。
1. 连续 begin:
begin; sql a; sql b; begin;
当再次出现 begin 的时候就会触发提交。
2. DDL 语句:如 alter / create / drop
3. DCL 语句:如 grant / revoke / set password
4. 锁定语句:lock table / unlock table
5. truncate table / load data infile / select for update
开启事务测试:
1. 首先查看是否关闭自动提交:
select @@autocommit; -- 或者 show variables like "autocommit";
2. 测试删除回滚:
begin; -- 删除数据 delete from student where sname="张三"; -- 查看删除后的结果 select * from student; -- 回滚 rollback; -- 查看结果 select * from student;
如图:
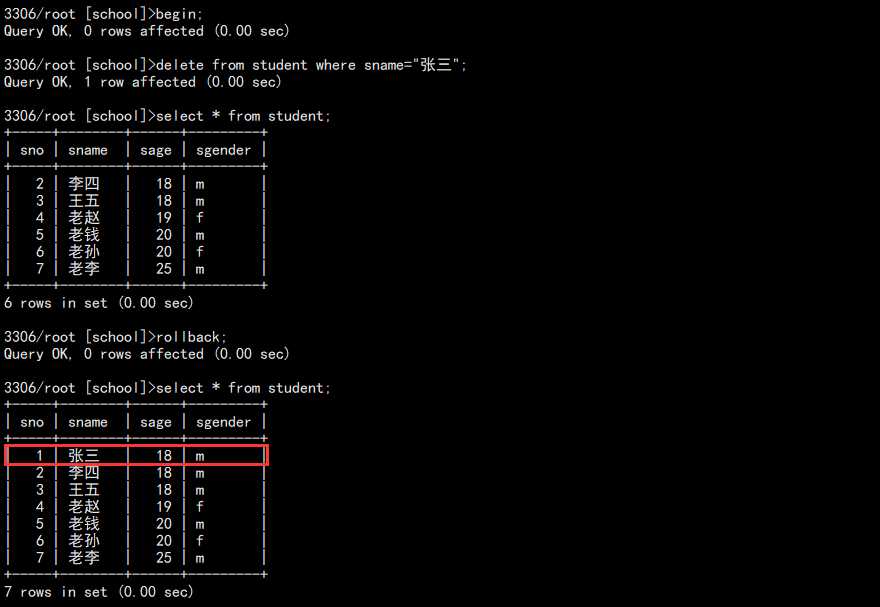
InnoDB 中 redo / undo
整体过程:
begin; update A to B; commit;
1. 原始的提交过程:
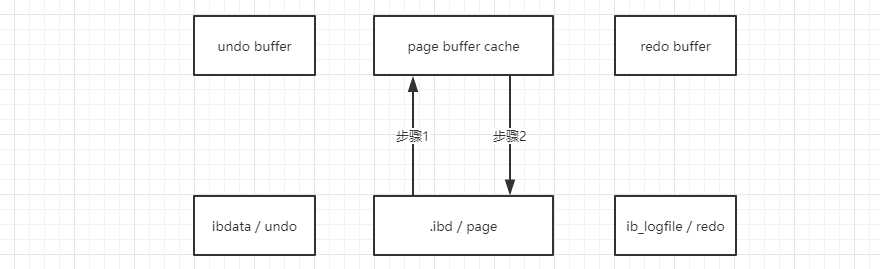
简要说明:
在没有使用 undo 和 redo 的时候,想要把 A update 成 B,需要步骤 1 先从 page 中读出 16K 数据页到 page buffer 中,将 A update 成 B 再度通过步骤 2 将整个数据页写回来。
其问题在于每次读取一个数据页,IO 开销相当大,资源浪费,性能差。
2. 加入 redo 后操作:
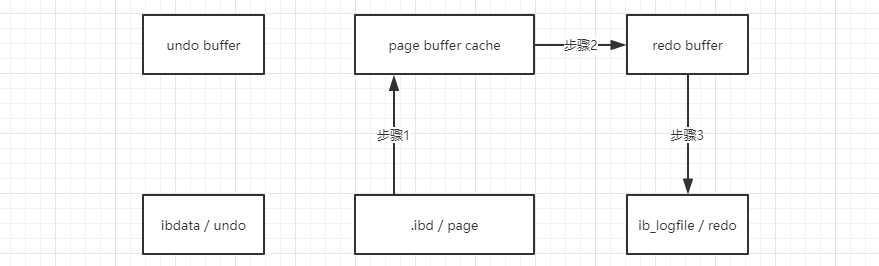
简要说明:
同样的更新过程,通过步骤 1 将 A 数据读取到 page buffer 中,此时 update A to B,并立即将这个更改过程通过步骤 2 记录到 redo buffer 中。此时执行 commit,触发步骤 3,将单条记录变更写到 redo 中。
在这过程中,为了保持数据一致性,数据库拥有日志序列号 LSN,经过步骤 1 之后执行 update,此时 LSN 会自加 1,同时生成事务号 TXID,并跟随数据一起最终持久化到 redo 中。LSN 是和源数据中 LSN 对比确认数据是否变更。最终保持一致,完成更新。TXID 则是为了标记事务本身。
当写入 3 以后,数据库挂了。此时重启数据库会发现源数据中 LSN 和 redo 中 LSN 不一致,触发数据库 CSR 自动故障恢复。将 redo 中的不一致部分读取到 redo buffer,在回到 page buffer cache 中,触发 CKPT 最终写入 page 中,保证数据的一致性,这就是前滚操作。
执行过程中的概念:
redo:重做日志,ib_logfile0~1,默认 50M,轮询使用。
redo log buffer:redo 内存区域。
ibd:存储数据行和索引。
buffer pool:缓冲区池,数据和索引的缓冲。
LSN:日志序列号,磁盘数据页,redo log,buffer pool,redo buffer 中都有,MySQL 每次启动都会比较磁盘数据页和 redo log 中的 LSN,当一致时才能正常启动。
WAL:write ahead log,日志优先写的方式持久化,意味着在 commit 之后,变更只有写到了 redo log 中就代表持久化完成。
脏页:内存中发生了修改,在没写入磁盘之前,该内存页就叫脏页。
CKPT:check point,检查点,将脏页写入磁盘的动作。
TXID:事务号,每一个事务都具备,伴随整个事务。
3. undo 回滚操作:
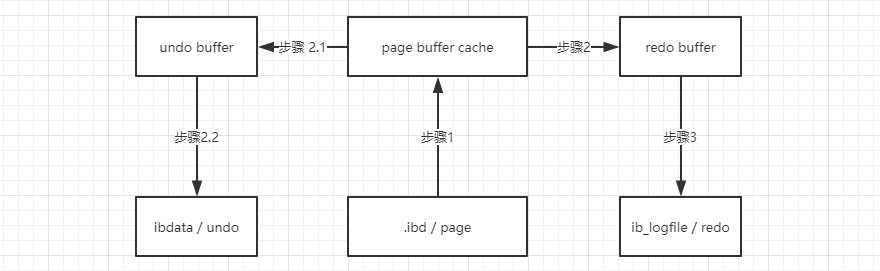
简要说明:
当开启事务,update 将数据读取到 page buffer 的时候,它的旧的值和 LSN 这些会被同步保存到 undo buffer 和 undo 中,另外也会被执行 update,当我们最终并不是执行 commit 而是执行 rollback 的时候,就会将 undo 中的数据再次读出来持久化到磁盘 page 中。
同事也会出现另外的情况,多个事务提交过程中,有些需要提交,有些并没有提交。此时数据库挂了,当重新启动的时候触发 CSR,通过 redo 中执行日志,如果有 commit 标记的就会走 redo,如果没有的则会走 undo 回滚。
InnoDB 中锁 / 隔离级别
在 MySQL 中的锁为行级锁(悲观锁),谁先操作这行谁就具有这行的执行权力:
1. 新开一个窗口,执行一个事务,不提交:

2. 新开另外一个窗口,也去修改这一行:

可以发现卡住了,无法执行。过一段时间会报错:

提示锁等待超时,当然此时修改其它行是没问题的。在 InnoDB 的锁是行级锁,但是在 MyISAM 中则是表级锁,MyISAM 中没有事务,直接锁表。
另外还有乐观锁,就是没有锁,redis 就是这样。
隔离级别(transaction_isolation) ,负责 MVCC,解决读一致性问题。
RU:读未提交,可脏读,一般不允许使用
RC:读已提交(read-committed),可以出现幻读,可以防止脏读,事务提交其它窗口立即生效能够查到。
RR:可重复读(默认,repeatable-read),防止幻读,利用 undo 快照 + GAP(间隙锁) + NextLock(下键锁)
SR:可串行读,可以防止死锁,但并发事务性能差。
测试当前事务隔离级别:
1. 开启事务,在两边查看:
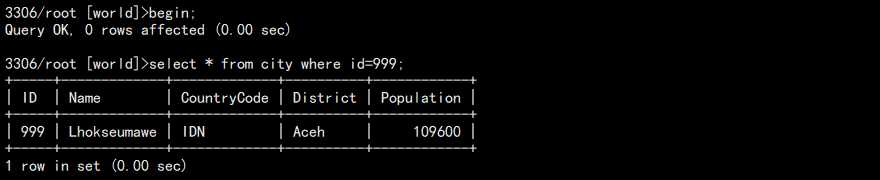
另外一个窗口:

2. 更新这行数据:
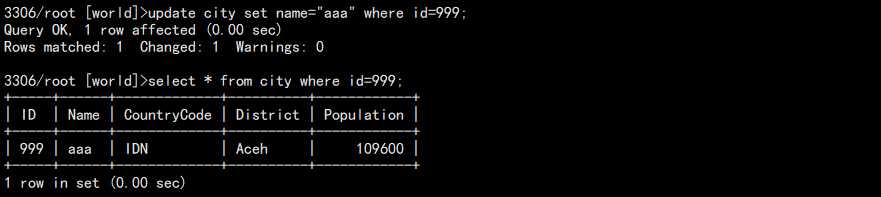
另外一个窗口:

还是旧的数据!
3. 提交事务:

另外一个窗口:

依然是旧的数据!
4. 查看当前事务隔离级别:
select @@tx_isolation;
结果:

5. 如果想要读取到正确的,则只需要 commit 一次再读取,这是为了防止幻读:
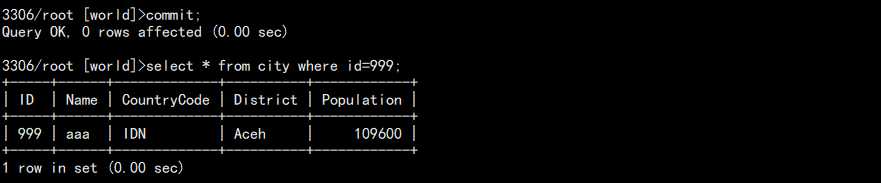
也可以退出重新登录!这就是 RR 的可重复读的作用,同一窗口,数据始终一致。
其它说明:
在将隔离级别调整为 RC 之后,可以在 commit 之后其它窗口立即读取到最新的值,但是这也带来了程序的困扰,可能他还没有处理完这个请求你的值又变了。
为此,在 RC 模式中可以在语句中添加 for update,如:select * from city where id=100 for update; 这样就能锁住该行。直到我这边 commit 才解锁。
InnoDB 存储引擎优化参数
1. 查看默认存储引擎:
select @@default_storage_engine;
2. 查看和修改表的存储引擎:
-- 查看表的存储引擎 show create table city; -- 修改表的存储引擎 alter table city engine="innodb";
一般在建表的时候就设置好,或者直接配置好默认的存储引擎。注意 MyISAM 不支持外键。
3. 查看共享表空间:
select @@innodb_data_file_path;
一般在初始化的时候配置,可以设置为:innodb_data_file_path=ibdata1:512M:ibdata2:512M:autoextend
4. 查看是否开启独立表空间:
show variables like "%innodb_file_per_table%";
5. 查看 buffer pool size:
show variables like "%innodb_buffer_pool_size%";
该值设置原则建议为内存的 75% - 80%。
show engine innodb status\G
也可以通过这样查看,不过这里的 Buffer pool size 显示的是数据页,一页等于 16K。
Free buffers 是空闲的,Database pages 是使用的,一般使用率 70% 左右就行了。
6. innodb_flush_log_at_trx_commit(双1标准之一)
show variables like "%flush_log%";
作用:控制 innodb 将 log buffer 中的数据写入日志文件并 flush 到磁盘的时间点,取值 0,1,2。
0:事务提交时,不做日志写入,而是每秒中将 log buffer 中的数据写入文件系统缓存并 fsync 磁盘一次。
1:每次事务提交都写入日志,flush 到磁盘,确保 ACID。
2:每次事务提交写入文件系统缓存,但是要每秒写入磁盘一次。
7. innodb_flush_method:
作用:控制 log buffer 和 data buffer 刷写磁盘时是否经过文件系统缓存。
show variables like "%innodb_flush%";
默认为 null。写到配置文件中生效。
fsync(默认):日志和数据写磁盘,都走 OS buffer
O_DIRECT:数据写磁盘,不走 OS buffer
O_DSYN:日志写磁盘,不走 OS buffer
# 最高安全模式 innodb_flush_log_at_trx_commit=1 Innodb_flush_method=O_DIRECT # 最高性能: innodb_flush_log_at_trx_commit=0 Innodb_flush_method=fsync
8. redo log 配置:
# 设置 buffer 大小 innodb_log_buffer_size=16777216 # 设置 ib_logfile 的大小,可以稍微大些 innodb_log_file_size=50331648 # 设置 ib_logfile 个数 innodb_log_files_in_group=3
小结
本章节内容非常重要!
原文:https://www.cnblogs.com/Dy1an/p/11393045.html