通常使用物理服务器和大多数虚拟机管理程序进行fork是很快的,即使很大的进程也是如此。 然而,Xen的fork()速度很慢,因此对于某些EC2实例类型(以及其他虚拟服务器提供程序),每次父进程调用fork()以便进行RDB持久化时,可能会出现严重的延迟峰值。 如下图所示,清晰的展示了延迟峰值:
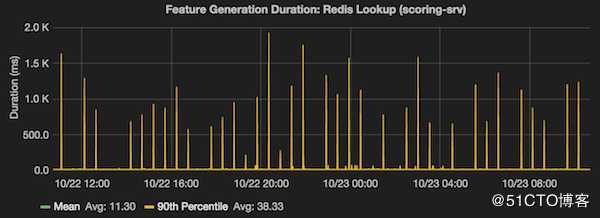
您可以想象一下,如果您在fork()的时候做一个延迟测试,那么在父进程fork()的时候,所有请求将延迟一秒(以上图为例)。 这将产生大量具有高延迟的样本,并且将影响99%的结果。
要更改实例类型,配置,设置或其他任何内容以改善此行为是一个好主意,并且有些用例即使单个请求具有过高延迟也是不可接受的。然而很明显的是,每30分钟发生1秒的延迟峰值不是很明显,因为这与在请求中均匀分布延迟峰值有很大不同。
如果是均匀分布的峰值,如果访问某个页面需要对Redis服务器执行大量请求,则访问页面很可能会碰到延迟:这会严重影响服务质量。
然而,如上图所示,每运行30分钟后1秒的延迟是完全不同的事情。具有良好延迟表现的百分比随着请求数量的增加而变得更好,因为请求越多,这个延迟就越不可能在样本中过度表示出来,反而会被隐藏。如果您每分钟只有1个请求,并且其中一个请求恰好碰到fork()导致的高延迟,那就会让延迟测试结果非常难看。
另外:大多数页面浏览不受影响。 因为唯一那几个用户碰到1秒延迟的,是刚好他们的请求和fork()在同一时间,其他用户的请求只会有极低的概率碰到这样糟糕的事情。 另外请注意,与fork()撞上的页面访问(即使由100个请求组成)也不会延迟超过一秒,因为fork()完成后请求就会完成,并不需要等到RDB持久化完成。
只有fork()会导致延迟毛刺,fork出来的子进程在生成RDB文件过程中,并不会对系统有很大的影响。除非子进程生成RDB文件的过程中(这个过程使用了操作系统的copy-on-write机制)有大量的写入,而且服务器可用内存不多,这时候可能会发生swapping导致出现延迟。
在当今最流行的运行时环境EC2实例中,fork延迟是Redis用户最糟糕的体验之一,所以redis作者正着手测试Redis和EC2:相信很快就会在Redis官方文档中有对EC2进行特定优化的说明 ,到时候会有比在master-slaves中禁用持久性操作更安全的方案。
如果您现在需要EC2 + Redis主机并且已禁用持久性,则最简单的部署方式是禁用Redis实例的自动重启,并使用Sentinel进行故障转移,以便崩溃的主服务器不会自动返回可用状态。 在检查故障转移成功并且有新的可用的master后,系统管理员可以手动重新启动实例。
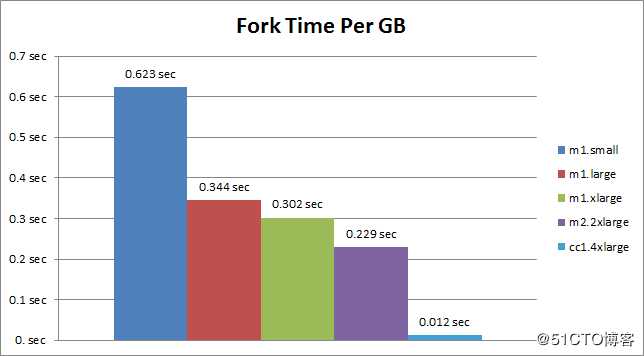
需要说明的是,并非所有EC2实例都是相同的,恰恰相反,各种EC2实例fork表现差异还很大。如下图所示,是老外做的一些测试:
原文:https://blog.51cto.com/14230003/2433013